2018-12-20
关键词: HBase是什么 、 什么是HBase 、 HBase基本概念
本篇文章系本人根据目前所掌握的知识对 HBase 的基本概念作出的一篇轻简式科普文章。关于文章所述的知识点本人不保证其绝对、完全正确性。
1、从一幅画说起
绘画界有一支流派被称为 “印象派” ,印象派画系里数莫奈的 《日出 · 印象》 知名度比较高了。话说印象派这一派系的由来还和莫奈这幅画有关。当时有位记者嘲讽这幅画:“完全就是凭印象胡乱画出来的!” 或许这是阴差阳错,亦或许这就是自然的本质,这种 “凭印象胡乱画出来的” 画作终究还是被世人所接纳了。

《日出 · 印象》
2、“画”与 HBase 有什么关系?
“画” 与 HBase 当然没有关系。但是我却从画的派系里得到一些感悟。
印象派的风格初看起来确确实实如那位记者所言:“完全是凭印象胡乱画出来的” 。 但即使如此,印象派还是成了一支大派系,得到世人的认可。事实上,当你看多几,会发现这幅画也是很美的。我想这足以说明 “仅凭印象” 这一模式是一种可行的模式,或者说至少会是另一种分支的发展路线。那我们联想到 IT 行业来。IT 行业,尤其是软件行业,技术迭代的周期非常短,程序员要想在这个行业长久地保持竞争力,就必须不断地学习新技术。而一门 IT 技术几乎都会含有大量的知识点内容,处于工作状态中的程序员们通常不会有太多的时间来学习新技术。因此,如何快速学习并应用新技术成了每一个程序员不得不关注的事。如今,快速阅读与碎片化阅读几乎成了现代人的主流学习方式了。这种学习方式基本上是粗略地阅读书籍、博客或者某些公众号推文,然后抓取一些关键字眼来学习。它在我看来与 “印象派画” 有异曲同工之妙。印象派画往往都是在很短的时间内匆匆完成的,稍有停顿,你想画的景色就已经改变了。
提到 “快速阅读” 、 “抓关键字阅读” 等字眼我想不少人一时之间都会很难认可这种学习方式。觉得你不对知识点细嚼慢咽,如何能真正学到技术知识呢?对,想要真正学好知识,确实得沉下心来慢慢研究,就像传统画派那般仔细严谨。但我前面说了:这种 “仅凭印象” 、 “快速完成” 的模式已经被证实确实是一种可行的模式,只是它有别与传统流派而已。两种模式没有对错之分,只是各自有应用领域之别而已。现代社会是一个快节奏的社会,要想跟上社会发展的进程,那学习自然也不能慢下脚步来。在这里我敢断言:现代社会快速阅读、快速学习的重要性比起传统精研细究的方式更高!
那么回到我们关于 HBase 的话题。本篇文章,我主要以自己的语言来介绍 HBase 是什么。目标是让那些从未接触过 HBase 而又打算学习 HBase 的同学能有个 “启蒙式” 印象。同时,会对涉及到的每一个知识点提取出一些关键字眼来,基本上,记住这些关键字眼就能记住这一个知识点的了。
3、从哲学三问看 HBase
哲学史上有三个终极问题,传说只要能回答这三个终极问题,就代表着哲学已经到达尽头了:
1. 我是谁?
2. 我从哪里来?
3. 我要到哪里去?
今天我们就以这三个问题来认识一下 HBase 。当然,这三个问题在 HBase 上是可以得到回答的,只是回答了这三个问题只能代表这我们首次踏入了 HBase 的大门而不是已经到达了终点。
3.1、灵魂第一问:我是谁?
首先来看看 HBase 到底是什么。
HBase 是 Apache 旗下的一款面向海量数据的数据库软件。它根据 Google 在 2006 年发表的论文 《BigTable》 设计而来,这篇论文论述了如何实现大规模结构化数据的分布式存储。HBase 于 2008 年正式成为 Apache 基金会下的项目。一句话:HBase 是一款处理海量数据的分布式数据库软件。
这里有一个概念不得不提,何谓 “海量数据” ?个人对海量数据的定义有两点:
1. 数据本身足够大。TB 及以上级别的数据量。
2. 数据增长速度足够快。每天以几十上百 GB 甚至更高的速度在增长。
3.2、灵魂第二问:我从哪里来?
其次,我们来聊聊 HBase 是基于什么样的环境,或者说需求下而诞生的。
我们都知道,能量是不可能凭空产生的,HBase 亦如是。一个新事物的诞生,必然是出于人们对旧有事物的不满足。在HBase诞生之前,人们使用的数据库软件基本都是面向 “行” 存储的。什么是面向行存储呢?从逻辑上讲就是我们把同一张表中的数据按一行一行的形式保存起来。从物理上讲则是我们把同一张表中的数据按一行一行的形式存储在介质上。下面有一幅简图:
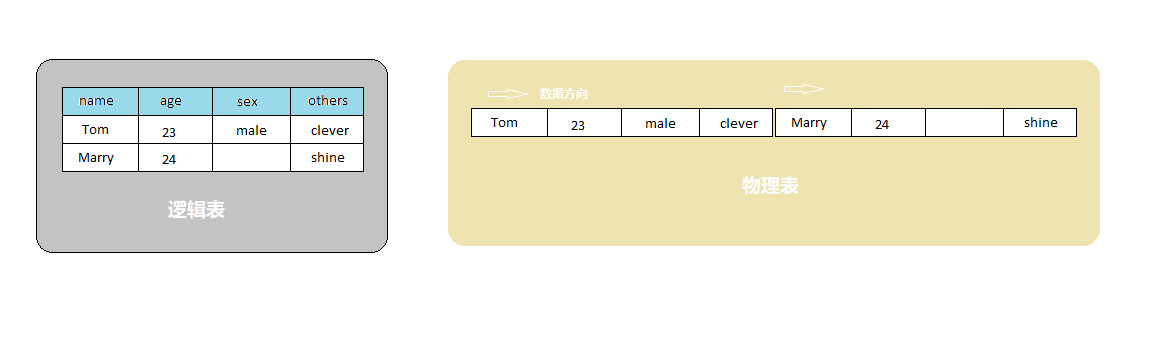
传统数据库的按行存储
上图右侧部分就是行存储方式在硬盘上的存储形式。
这种行式存储的数据库以 MySQL 、Oracle 为代表,长期占据各大中小型企业机房。但随着经济与互联网的发展,各大企业数据量也呈爆发式增长。传统关系型数据库因为只能把同一个数据库中的数据存储在一个文件里,当数据量大到一定程度时就必然会引发性能问题。并且传统关系型数据库对字段空值也要占据一块物理存储空间,这在某些情况下就可能会造成极大的空间浪费了。于是乎,HBase 就以一种类似于 “上帝说要有光,于是便有了光” 的形式出现了。一句话:HBase 的诞生是为了解决海量数据存储问题的。
3.3、灵魂终极问:我要到哪里去?
最后,我们来说说 HBase 它适合于哪些场景以及我们该如何来学习 HBase 。
首先我们得知道几个关于 HBase 的特性。HBase 是基于 HDFS 的一款数据库软件,而 HDFS 又是一款被设计用于部署在廉价硬件之上的文件管理系统。 HBase 是基于列在物理介质上存储的数据库,这就意味着同一张表中的数据很有可能会被保存在不同的机器上。HBase 是属于非关系型数据库,不支持表关联及各种关系型查询。简要总结一下 HBase 的特性就是
1. 存储成本低廉
2. 查询响应速度不高
3. 不适用于做数据分析
因此,我们可以总结出当你的数据业务同时满足以下 4 条时,HBase 再适合不过了:
1. 主体需求不是做数据分析
2. 查询时不需要那么灵活以及实时
3. 单表数据量超过千万,且并发较高
4. 对于硬件没有太多的预算
然后再来看看该如何来学习 HBase 。
这里主要讲我们程序员如何给自己搭建一个纯学习环境,当然,如果你或者说你的公司条件很好,能够直接上生产环境来学习,自然是最好不过的。
准备一台性能好一点的电脑。何谓 “性能好一点” 呢?
1. 内存 16GB 及以上
2. CPU 笔记本标压 U 的话能上 i7 就最好了,台式机随便一个 i 都行。
3. 硬盘 50GB 以上就行
4. 手感很好的键盘
现在主流操作系统应该是 windows 吧?装一个虚拟机软件。笔者用的是 vmware ,然后 CentOS 虚拟机。windows 系统是你日常查资料做笔记用的。 CentOS 虚拟机用于安装 HBase 学习环境。HBase 非常依赖 HDFS 与 Zookeeper ,关于这两个框架的知识,本文就不涉及了,有兴趣的同学可以自行查阅资料学习。关于更多详细的软件部署步骤,还需要各位同学自行查阅,本文这里不适合啰嗦太多这些内容。
最后,学习环境搞定了,那该如何进一点学习呢?笔者根据个人经验作出如下建议
1、主要的学习资料应为: 1. 培训机构教学视频 ;2. 书籍。
2、入门靠培训机构教学视频,视频讲解虽然非常详细,但往往非常消耗时间,并且很容易走神,初期靠教学视频有了一个模糊的概念就可以了
3、知识点巩固与进阶要靠书籍 。并且应该大量阅读不同书籍,基本上,同一个知识点,在不同的书上你都能 “解锁一些新姿势”。
4、不知道去哪里找培训机构的教学视频? 1. 淘宝; 2. 闲鱼。 试试看?
5、不知道有什么书可以看? 淘宝、京东、当当、亚马逊 等书籍电商网站去逛逛?
6、书籍太多,不知道哪些书好,纠结买哪本? 建议把每一本书都看一遍。什么?买书买到肉疼?同学,学习就是一场投资行为,没有付出是不行的。(不过这些书都买的话确实要花很多钱,而且往往后面还有很多框架等着我们学。长此以往,经济压力确实不小。不过,仍然是有解决的办法的,笔者在这方面摸索出了一套自己的学习方式,但是我在这里不能说太多:不一定要看纸质书)
好,今天关于 HBase 暂且聊到这。
2018 - 12 - 20 发表
2019 - 04 - 05 修改