背景:在Jenkins编译失败后,需要拿到Jenkins的编译失败的日志,存储在数据库中,在把数据取出来,在另外一个页面进行展示,我的思路为:
1.观看Jenkins编译失败后的控制台显示的内容
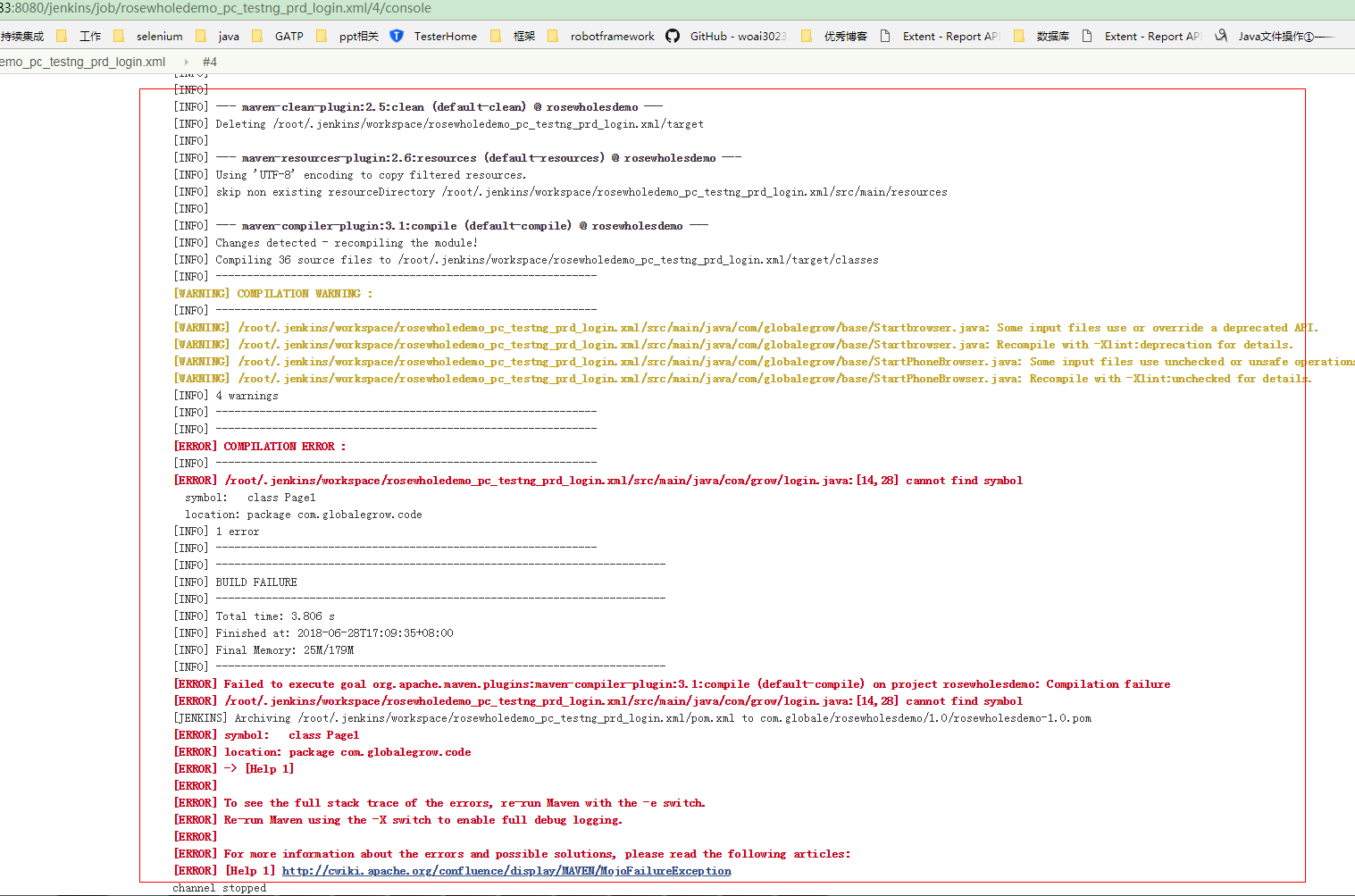
2.在查看网页源码,发现我们实际需要的内容是从<pre class="console-output"></pre>这里面的内容,那这样就很简单

3.编码
使用python的urllib
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:38.0) Gecko/20100101 Firefox/38.0",
"character": "utf-8"} #header是必须,不然会提示错误,相当于爬虫时,就是通过浏览器去实现的
url = settings.JENKINS_URL+'job/'+str(job_name)+'/'+ str(job_number)+'/console' #拼接的Jenkins地址
logger.info("拼接的地址为:%s" %url)
opener = urllib.request.build_opener()
opener.addheaders = [headers]
html_log = opener.open(url).read().decode("utf-8") #打开url后读取内容
build_error_log=re.search(r'<pre class="console-output">(.*)</pre>', html_log, re.S).group(1) #正则取出数据
logger.info(build_error_log)
这样就可以把编译失败的内容给显示出来了