表全部数据

1 查询people_no重复的记录
select * from people where people_no in (select people_no from people group by people_no having count(people_no) > 1);
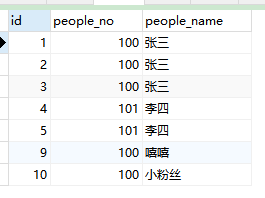
2 查询people_no重复的记录 ,排除最小id,如果删除改为delete from
select * from people where people_no in (select people_no from people group by people_no having count(people_no) > 1) and id not in (select min(id) from people group by people_no having count(people_no)>1);

3 查询people_no people_name重复的记录
select * from people a where (a.people_no,a.people_name) in (select people_no,people_name from people GROUP BY people_no,people_name HAVING count(*)>1);

4 查询people_no people_name重复的记录,排除最小id
select * from people a where (a.people_no,a.people_name) in (select people_no,people_name from people GROUP BY people_no,people_name HAVING count(*)>1) and a.id not in (select min(id) from people GROUP BY people_no,people_name HAVING count(*)>1);

原文链接:https://www.cnblogs.com/LDDXFS/p/9867928.html