1、Elasticsearch集群不同颜色代表什么?
绿色——最健康的状态,代表所有的主分片和副本分片都可用;
黄色——所有的主分片可用,但是部分副本分片不可用;
红色——部分主分片不可用。(此时执行查询部分数据仍然可以查到,遇到这种情况,还是赶快解决比较好。
2、Elasticsearch 集群颜色变黄色了要不要紧?
Elasticsearch集群黄色代表:
- 分配了所有主分片,但至少缺少一个副本。
- 没有数据丢失,因此搜索结果仍将完整。
注意:您的高可用性在某种程度上会受到影响。
如果更多分片消失,您可能会丢失数据。 将黄色视为应该提示调查的警告。
3、Elasticsearch集群健康状态如何排查?
3.1集群状态查看
GET /_cluster/health?pretty=true
{ "cluster_name" : "cloud_es", "status" : "green", "timed_out" : false, #是否超时 "number_of_nodes" : 2, #节点数量 "number_of_data_nodes" : 2, #存储节点数量 "active_primary_shards" : 10, #主分片数 "active_shards" : 17, #所以分片数 "relocating_shards" : 0, #碎片迁移 "initializing_shards" : 0, "unassigned_shards" : 0, "delayed_unassigned_shards" : 0, "number_of_pending_tasks" : 0, "number_of_in_flight_fetch" : 0, "task_max_waiting_in_queue_millis" : 0, "active_shards_percent_as_number" : 100.0 #集群分片的可用性百分比,如果为0则表示不可用 }
3.2分片状态查看
GET /_cat/shards?v
index shard prirep state docs store ip node nihao 2 r STARTED 0 208b 192.168.100.110 node01_r1 nihao 2 p STARTED 0 208b 192.168.100.110 node01_r2 nihao 1 p STARTED 0 208b 192.168.100.110 node01_r1 nihao 1 r STARTED 0 208b 192.168.100.110 node01_r2 nihao 0 r STARTED 0 208b 192.168.100.110 node01_r1 nihao 0 p STARTED 0 208b 192.168.100.110 node01_r2 hello 2 p STARTED 1 4.4kb 192.168.100.110 node01_r1 hello 1 p STARTED 1 4.5kb 192.168.100.110 node01_r2 hello 0 p STARTED 0 208b 192.168.100.110 node01_r1 chong 2 r STARTED 1 4.3kb 192.168.100.110 node01_r1 chong 2 p STARTED 1 4.3kb 192.168.100.110 node01_r2 chong 1 p STARTED 0 208b 192.168.100.110 node01_r1 chong 1 r STARTED 0 208b 192.168.100.110 node01_r2 chong 0 r STARTED 0 208b 192.168.100.110 node01_r1 chong 0 p STARTED 0 208b 192.168.100.110 node01_r2 .kibana 0 p STARTED 42 58.9kb 192.168.100.110 node01_r1 .kibana 0 r STARTED 42 74.4kb 192.168.100.110 node01_r2 wefwe 2 r STARTED 0 208b 192.168.100.110 node01_r1 wefwe 2 p STARTED 0 0b 192.168.100.110 node01_r2 wefwe 2 r UNASSIGNED #副本丢失 wefwe 1 p STARTED 0 208b 192.168.100.110 node01_r1 wefwe 1 r STARTED 0 208b 192.168.100.110 node01_r2 wefwe 1 r UNASSIGNED #副本丢失 wefwe 0 r STARTED 0 208b 192.168.100.110 node01_r1 wefwe 0 p STARTED 0 208b 192.168.100.110 node01_r2 wefwe 0 r UNASSIGNED #副本丢失
3.3 查看unsigned 的原因
GET /_cluster/allocation/explain
3.4 查看集群中不同节点、不同索引的状态
GET _cat/shards?h=index,shard,prirep,state,unassigned.reason
3.5 cerebro监控工具排查
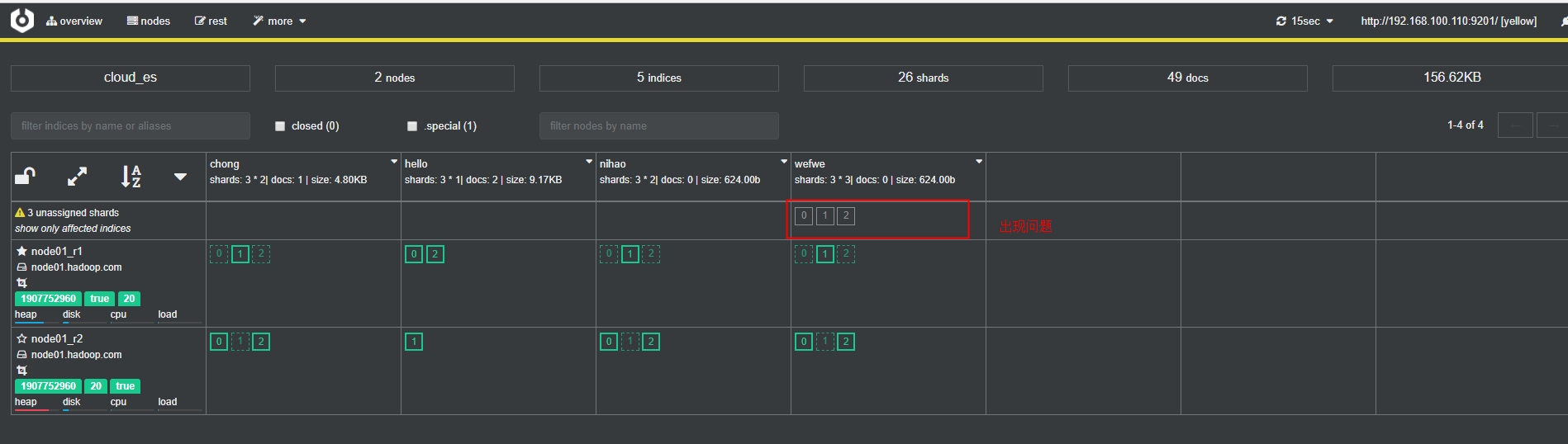
4、Elasticsearch集群黄色的原因排查及解决方案
4.1 原因1:Elasticsearch采用默认配置(5分片,1副本),但实际只部署了单节点集群。
index.number_of_shards:5 index.number_of_replicas:1
解决方案如下:
您可以将副本计数降低到0或将第二个节点添加到群集,以便可以将主分片和副本分片安全地放在不同的节点上。
这样做以后,如果您的节点崩溃,群集中的另一个节点将拥有该分片的副本。 实际环境中索引最大副本数等于集群节点数-1。
(1)设置副本数为0,操作如下:
PUT /cs_indexs/_settings { "number_of_replicas": 0 }
进行段合并,提升访问效率,操作如下:
POST /cs_indexs/_forcemerge?max_num_segments=1
(2)不再物理扩展集群,将后续所有的索引自动创建的副本设置为 0。
PUT /_template/index_defaults { "template": "*", "settings": { "number_of_replicas": 0 } }
4.2 原因2:Elasticsearch分配分片错误。
进一步可能的原因:您已经为集群中的节点数过分分配了副本分片的数量,则分片将保持UNASSIGNED状态。其错误码为:ALLOCATION_FAILED。
解决方案如下:
reroute:重新路由命令允许手动更改群集中各个分片的分配。
核心操作如下:
POST /_cluster/reroute { "commands": [ { "allocate_replica": { "index": "cs_indexs", "shard": 0, # 重新分配的分片(标记黄色的分片) "node": "es-2" } } ] }
reroute扩展使用——可以显式地将分片从一个节点移动到另一个节点,可以取消分配,
并且可以将未分配的分片显式分配给特定节点。
举例使用模板如下:
POST /_cluster/reroute { "commands" : [ { "move" : { "index" : "test", "shard" : 0, "from_node" : "node1", "to_node" : "node2" } }, { "allocate_replica" : { "index" : "test", "shard" : 1, "node" : "node3" } } ] }
其中:
1)move代表移动;
2)allocate_replica 代表重新分配;
3)cancel 代表取消;
4.3 磁盘使用过载。
原因3:磁盘使用超过设定百分比85%。
cluster.routing.allocation.disk.watermark.low——控制磁盘使用的低水位线。 它默认为85%,这意味着Elasticsearch不会将分片分配给使用磁盘超过85%的节点。 它也可以设置为绝对字节值(如500mb),以防止Elasticsearch在小于指定的可用空间量时分配分片。
解决方案:
(1)查看磁盘空间是否超过85%。
[root@localhost home]# df -h Filesystem Size Used Avail Use% Mounted on /dev/xvda1 1014M 165M 849M 17% /boot /dev/mapper/cl-home 694G 597G 98G 86% /home
(2)删除不必要的索引,以释放更多的空间。
DELETE cs_indexs
4.4 磁盘路径权限问题。
原因4:磁盘路径权限问题。安全起见,默认Elasticsearch非root账户和启动。
相关的Elasticsearch数据路径也是非root权限。
解决方案:
去数据存储路径排查权限,或者在data的最外层设置:
chown -R elasticsearch:elasticsearch data