物理执行图表示一组rdd如何放在集群中运行。
当触发Action执行的时候,这一组相互依赖的rdd要被处理,所以要转化为可运行的物理执行图,调度在集群中执行。
因为大部分的rdd并不是真正的存储数据,只是数据从中流转,所以不能直接在集群中运行rdd,需要将rdd转换成stage和task,从而运行task。
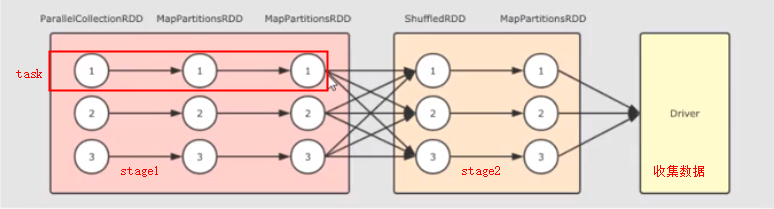
由图可得:
1.在同一个stage中所有rdd对应分区,在同一个task中执行。
2.stage划分是由shuffle操作断开的。
1.谁执行具体任务
Executor是执行rdd计算任务的容器,也就是一个进程,负责运行task,具体计算任务的线程叫做task。
2.task如何设计
1.每个rdd的每个分区都对应一个task。
2.分阶段,一个task计算所有rdd中对应分区。
3.物理执行图基本概念
Application:编写的Spark的应用程序。
Driver:Spark中的Driver负责运行上述Application的main函数并创建SparkContext,创建SparkContext的目的是为了准备Spark应用程序的运行环境,在Spark中有SparkContext负责与ClusterManager通信,进行资源申请、任务的分配和监控当Executor部分运行完毕后,Driver同时负责将SparkContext关闭。
Executor:进程——运行在工作节点上,负责运行Task。
DAG: 有向无环图。用户提交的应用程序,Spark底层会根据宽依赖、窄依赖自动生成DAG。反应出RDD之间的依赖关系。
DAGScheduler: DAGscheduler是一个由SparkContext创建,运行在driver上的组件,根据每个job中rdd依赖关系生成DAG。将stage中生成的taskset提交给TaskScheduler。TaskScheduler负责taskset调度,在executor执行taskset。
得到结果再发送给driver。
job:用户提交的作业。spark程序放在集群中运行,job是最大单位,将job拆分为stage和task去调度执行,一个job就是一个spark程序从 读取 - 计算 - 运行的过程。 spark任务调用一次Action算子生成一个job。
一个spark程序可能有多个job,job之间是串行的,第二个job需要等到第一个job执行结束才会执行。
Stage:是Job的基本调用单元,Job根据宽窄依赖划分不同的Stage,一个job包含一个或多个stage,一个Stage中包含一个或者多个同种Task。
task:Executor的工作单元。一个Stage内只会存在同一种Task,Task数量与Stage的Partition数量保持一致(运行的Task数量可能会大于Partition数量)。
一个Application由一个Driver和若干个Job构成,一个Job由多个Stage构成,一个Stage由多个没有Shuffle关系的Task组成。
4.物理执行图运行在集群中
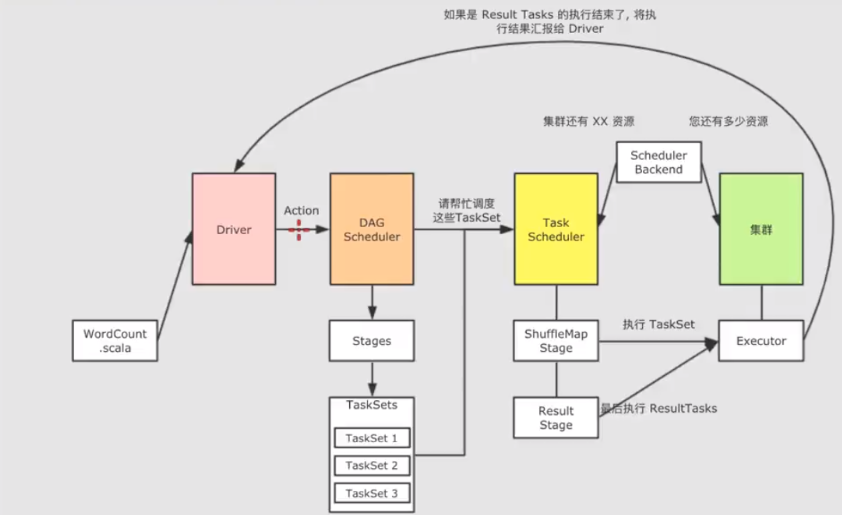
1.先把spark程序提交给driver,driver负责运行spark程序的main方法,运行完后生成逻辑执行图,然后把逻辑执行图调用Action。
2.DAGScheduler会生成stage并划分成不同阶段,每个阶段对应一个TaskSet。
3.DAGScheduler请求TaskScheduler调度TaskSet,TaskScheduler会询问集群有多少资源,资源返回给TaskScheduler。
4.TaskScheduler把stage调度到executor中执行taskSet,得到结果再发送给driver。