1.读取
2.数据预处理
3.数据划分—训练集和测试集数据划分
from sklearn.model_selection import train_test_split
x_train,x_test, y_train, y_test = train_test_split(data, target, test_size=0.2, random_state=0, stratify=y_train)

4.文本特征提取
sklearn.feature_extraction.text.CountVectorizer
sklearn.feature_extraction.text.TfidfVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf2 = TfidfVectorizer()
观察邮件与向量的关系
向量还原为邮件
(1)用TfidfVectorizer提取

TfidfVectorizer的提取结果:
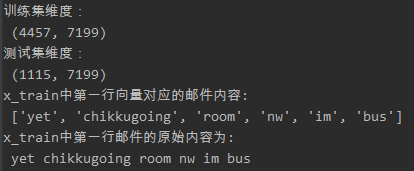
(2)用CountVectorizer提取
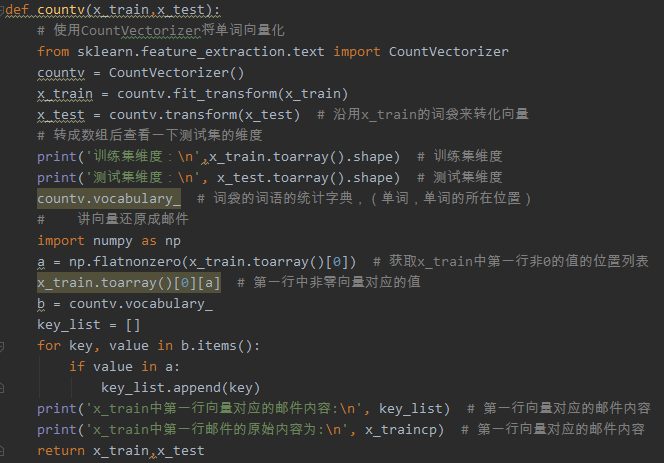
提取结果:
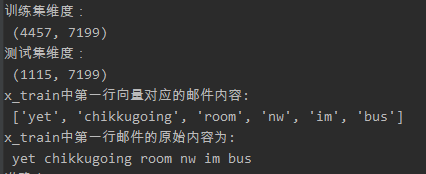
提取第一份邮件时两种方法提取的邮件内容并无差别
4.模型选择
from sklearn.naive_bayes import GaussianNB
from sklearn.naive_bayes import MultinomialNB
说明为什么选择这个模型?
因为高斯贝叶斯适用于正态分布数据,而从词袋中抽出单词,统计某一单词出现的频率属于n次独立重复试验,属于多项式分布概率,应该用多项式贝叶斯,所以选择MultinomialNB模型
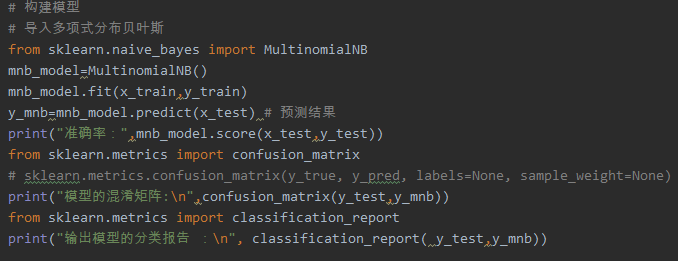
5.模型评价:混淆矩阵,分类报告
from sklearn.metrics import confusion_matrix
confusion_matrix = confusion_matrix(y_test, y_predict)
说明混淆矩阵的含义
from sklearn.metrics import classification_report
说明准确率、精确率、召回率、F值分别代表的意义
(1)混淆矩阵
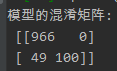
|
ham的预测个数(0) |
spam的预测个数(1) |
邮件实际类型个数统计 |
|
|
ham的真实个数(0) |
966(TP) |
0(FN) |
966 |
|
spam的真实个数(1) |
49(FP) |
100(TN) |
149 |
|
邮件类型预测统计 |
1015 |
109 |
1115 |
TP(True Positive): 真实为0,预测也为0,即真实为ham,预测也为ham的邮件个数;
FN(False Negative): 真实为0,预测为1,即真实为ham,预测为spam的邮件个数;
FP(False Positive): 真实为1,预测为0,即真实为spam,预测为ham的邮件个数;
TN(True Negative): 真实为1,预测也为1,即真实为span预测也为spam的邮件个数;
(2)分类报告
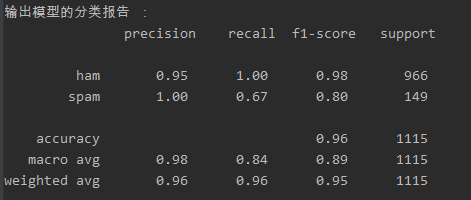
精确率:预测为正类0的准确率,Precision=TP/(TP+FP)
召回率:真实为0预测也为0的准确率,recall=TP/(TP+FN)
准确率:所有样本中被预测正确的样本比例,accuracy=TP+TN/(TP+FN+FP+TN)
F值:用来衡量二分类模型精确度的一种指标,他同时兼顾了分类模型的精确率和召回率。
6.比较与总结
如果用CountVectorizer进行文本特征生成,与TfidfVectorizer相比,效果如何?
在给训练集第一封邮件生成文本特征时,并无明显区别,当从整体上看,他们俩还是有所区别的
(1)CountVectorizer与TfidfVectorizer的区别
CountVectorizer:只考虑了词汇在文本中出现的概率
TfidfVectorizer:除了考虑某词汇在本文本出现的概率,还关注包含这个词语的其他文本的数量,计算他们的TF-IDF,找出文字中的关键词,它能够削减掉那些高频但是在整个文本当做不是具有十分意义的词汇,从而挖掘出更具代表性的词语
TF-IDF的计算公式:TF-IDF=TF*IDF
其中:

如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。分母之所以要加1,是为了避免分母为0(即所有文档都不包含该词)
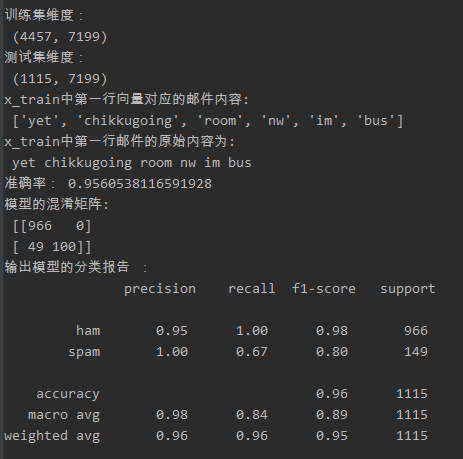
(2)TfidfVectorizer生成的文本特征训练模型得出的结果如下图所示:
(3)CountVectorizer生成的文本特征训练模型得出的结果如下图所示:
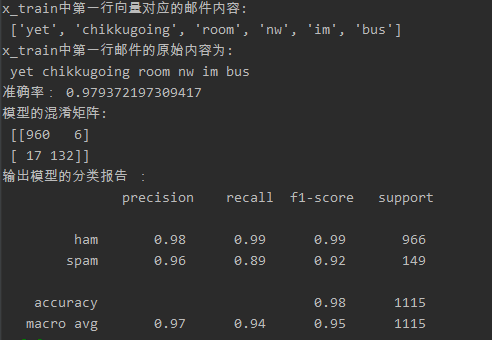
由结果可见,在此次使用CountVectorizer生成的文本特征训练模型比使用TfidfVectorizer生成特征的模型准确率略高点,CountVectorizer生成的文本模型,预测结果:实际邮件是spam预测也为spam的数量比TfidfVectorizer生成的模型多,但是实际是
ham,预测为ham的数量就比TfidfVectorizer生成的模型数量少点,两者相比,CountVectorizer生成的文本构成训练的模型自然就比TfidfVectorizer准确率高了点。