前言
顺理成章地,19.3.21起笔了第三章.也就是最近没啥事了,才有时间搞这些.生命不息奋斗不止吧!
变更记录
# 19.3.21 起笔
# 19.3.21 增加 Flask-RESTful如何获取body/args/header的值
# 19.4.3 增加 使用sqlalchemy-utils达到类似Django的choices(插入/更新值时限制值)效果
# 19.4.10 增加 建立model时指定排序
# 19.4.12 增加 解决多个model文件使用同一个Base的问题
正文
Flask-RESTful获取body/args/header的值
百度一番没啥思路,最后还是看的官方文档(以下内容取至官方文档+Google翻译)
参数位置
默认下,
RequestParser试着从flask.Request.values,以及flask.Request.json解析值。在
add_argument()中使用location参数可以指定解析参数的位置。flask.Request中任何变量都能被使用。例如:# Look only in the POST body parser.add_argument('name', type=int, location='form') # Look only in the querystring parser.add_argument('PageSize', type=int, location='args') # From the request headers parser.add_argument('User-Agent', type=str, location='headers') # From http cookies parser.add_argument('session_id', type=str, location='cookies') # From file uploads parser.add_argument('picture', type=werkzeug.datastructures.FileStorage, location='files')
我们可以看到,官方文档指出,从特定位置取数据只需要在 add_argument 里指定 location 即可
不指定 location 的话默认从args和form中取(写在header中无法取到)
如果取不到理所当然的报错啦,这里给一个例子
parser.add_argument('token', type=str, help='token error', required=True, location='headers') # 从headers中获取token
以上代码就达成了从headers中获取token的作用,没有token则会返回 tokenerror
sqlalchemy-utils达到类似Django的choices效果
首先要注明的是这个限制并不是限制在数据库中的,因此不经过ORM的数据不受限制
首先安装模块
pip install sqlalchemy-utils
sqlalchemy-utils 模块有很多功能,choices功能只是其中一个,但是网上该模块的使用比较稀少.
这里只介绍这一个功能
官方文档
https://sqlalchemy-utils.readthedocs.io/en/latest/
使用DEMO
from sqlalchemy.orm import sessionmaker, relationship, backref from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column, String, Integer, ForeignKey, DateTime from sqlalchemy_utils import ChoiceType class User(mysql_Base): # 用户表 __tablename__ = 'user' # 表名 lv_choices = ( (1, 'vip1'), (2, 'vip2') ) id = Column(Integer, primary_key=True) # 主键 name = Column(String(15), nullable=False, index=True, unique=True) # 用户名,不为空,唯一 pwd = Column(String(20), nullable=False) # 密码,不为空 lv = Column(ChoiceType(lv_choices, Integer()))
建立model时指定查询数据时排序
在正常业务中,我们通常会遇到按照某个字段进行排序的需求,在SQLAlchemy中我们既可以在查询时使用 orderby 方式查询
也可以在建立model时指定默认排序
demo如下
class Commodity(mysql_Base): # 商品表(非H5) __tablename__ = 'commodity' # 表名 delete_choices = ( (0, '未删除'), (1, '已删除') ) id = Column(BigInteger, primary_key=True) # 主键 name = Column(String(25), nullable=False, unique=True) # 商品名称,不可为空,唯一 introduce = Column(Text) # 商品详细说明(可为空) note = Column(String(256)) # 商品备注(后台,可为空) title_img = Column(String(256)) # 大图链接(可为空) integral = Column(Integer, nullable=False, default=0) # 商品价格(不为空/默认0) vaild_day = Column(Integer, nullable=False, default=30) # 商品有效时间(天/不为空/默认30) repertory = Column(Integer, nullable=False, default=10000) # 商品库存(不为空/默认1w) # putaway_time = Column(DateTime, nullable=False) # 商品上架时间(不为空) # soldout_time = Column(DateTime, nullable=True) # 商品下架时间(为空代表无限制) create_time = Column(DateTime, nullable=False) # 商品添加时间(不为空) update_time = Column(DateTime, nullable=False) # 商品最后更新时间(不为空) delete = Column(ChoiceType(delete_choices, Integer)) # 删除状态 # 指定默认排序为update_time __mapper_args__ = { 'order_by': update_time.desc() }
这种方法有利有弊,利是以后输出无需再写排序/弊是不够灵活(比如我们要求排序先把delete为1的去掉再排序)
所以怎么使用还是要看业务需求
多个model文件使用一个Base
一般情况下,我们的业务表结构比较复杂,一个model文件不利于后期的迭代和维护
关于Flask的文件夹配置是没有标准的,Flask的核心成员之一在 lepture 回答了该问题,他指出目录结构应该是灵活的.舒服就好
这里是我常用的文件结构
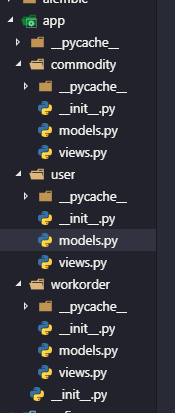
言归正传
我们虽然可以一个model中创建一个 Base, 但是会出现问题,在使用 alembic 提交数据库的时候,如果我在 modelA中创建表a ,在 modelB中创建表b并有一个字段关联表a
会报错,大致翻译是没有找到表a的id
解决方法是所有model使用同一个Base
首先我们在 config 配置文件中直接建立一个Base
# 用户名:密码@访问地址:端口/数据库 mysql_engine = create_engine('mysql+mysqldb://root:***@***:***/boom_web?charset=utf8mb4', pool_recycle=7200, # 空闲时间后自动关闭 pool_size=20, # 最大连接数 pool_timeout=30, # 连接超时 echo=False # 输出每次执行的sql ) # 创建Base基类 mysql_Base = declarative_base()
然后我们将 env 中的配置文件改为
from config.config import mysql_Base # target_metadata = [user_db.metadata, commodity_db.metadata, workorder_db.metadata] # 多个Base可用列表方式全部写进去,[bs1.metadata, bs2.metadata, ...] target_metadata = [mysql_Base.metadata]
# 注意引入的时候要注意直接import到Base,多一级比如 config.mysql_Base 也会报错
然后我们在所有model中引入
from config.config import mysql_Base
class User(mysql_Base): pass
然后写完一个model记得将表引入到 config 中
在config的下方加到
(不加会导致检测不到model)
from app.commodity.models import * from app.user.models import * from app.workorder.models import *
完整 config 为
# -*- coding=utf-8 -*- from sqlalchemy import create_engine, MetaData from sqlalchemy.orm import sessionmaker, relationship, backref from sqlalchemy.ext.declarative import declarative_base # 用户名:密码@访问地址:端口/数据库 mysql_engine = create_engine('mysql+mysqldb://root:***@***:***/boom_web?charset=utf8mb4', pool_recycle=7200, # 空闲时间后自动关闭 pool_size=20, # 最大连接数 pool_timeout=30, # 连接超时 echo=False # 输出每次执行的sql ) # 创建Base基类 mysql_Base = declarative_base() # 创建DBSession类型 mysql_DBSession = sessionmaker(bind=mysql_engine) from app.commodity.models import * from app.user.models import * from app.workorder.models import *
这样再执行提交即可