任何数据的持久化和网络传输都是以字节形式进行的,所以字节流和字符流之间必然存在转换问题。字符转字节是编码过程,字节转字符是解码过程。io包中提供了InputStreamReader和OutputStreamWriter用于字符和字节的转换。
来看一个小例子:

char[] charArr = new char[1];
StringBuffer sb = new StringBuffer();
FileReader fr = new FileReader("test.txt");
while(fr.read(charArr) != -1)
{
sb.append(charArr);
}
System.out.println("编码:" + fr.getEncoding());
System.out.println("文件内容:" + sb.toString());
FileReader类其实就是简单的包装一下FileInputStream,但是它继承InputStreamReader类,当调用read方法时其实调用的是StreamDecoder类的read方法,这个StreamDecoder正是完成字节到字符的解码的实现类。如下图:
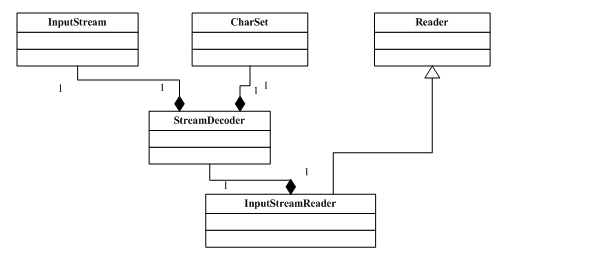
InputStream 到 Reader 的过程要指定编码字符集,否则将采用操作系统默认字符集,很可能会出现乱码问题。上例代码输出如下:
编码:UTF8 文件内容:hello�����Dz����ļ�!
再来看一个例子,换一个字符集:
char[] charArr = new char[1];
StringBuffer sb = new StringBuffer();
//设置编码
InputStreamReader isr = new InputStreamReader(
new FileInputStream("D:/test.txt")
, "GBK");
while(isr.read(charArr) != -1)
{
sb.append(charArr);
}
System.out.println("编码:" + isr.getEncoding());
System.out.println("文件内容:" + sb.toString());
输出正常:
编码:GBK 文件内容:hello!我是测试文件!