上接SQL SERVER 查询性能优化——分析事务与锁(四)
(四)未检测到的分布式死锁
某应用程序持有数据库资源,开启事务之后又与用户交互,而在与用户的交互过程中出现了错误,导致数据库资源迟迟不能释放。SQL SERVER 2005/2008 动态管理视图sys.dm_exec_requests提供相关信息,该SESSION_ID的status字段值为“sleeping”,wait_type为“NULL”值。如果是SQL 2005则可以通过Microsoft SQL Server Management Studio管理工具中的“活动监视器--》进程信息”视图,该进程的“开启事务字段”显示非“0”值。如下图。
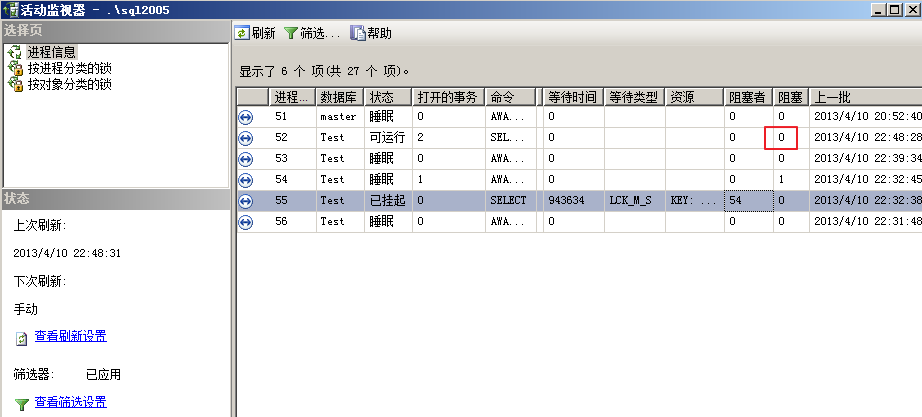
在SQL 2005(2008)中执行代码,即SQL SERVER 查询性能优化——分析事务与锁(二)中的“例一”,也就是下面的代码,得到如下图。
select spid 进程,STATUS 状态, 登录帐号=SUBSTRING(SUSER_SNAME(sid),1,30) ,用户机器名称=SUBSTRING(hostname,1,12) ,是否被锁住=convert(char(3),blocked) ,数据库名称=SUBSTRING(db_name(dbid),1,20),cmd 命令,waittype as 等待类型 ,last_batch 最后批处理时间,open_tran 未提交事务的数量 from master.sys.sysprocesses --列出锁住别人(在别的进程中blocked字段中出现的值)但自己未被锁住(blocked=0) Where spid in (select blocked from master.sys.sysprocesses) and blocked=0

由于应用程序持有事务,而且应用程序出错之后,没对事务的相应处理,也没有需要等待的资源,但持有事务,与前一种(三)情况类似,但通过SQL PROFILER工具进行跟踪,却无法发现任何错误事件。
建议解决方式
应用程序所造成的分布式死锁,很难加以跟踪分析,需要程序开发人员自行记录该应用程序的行为,比较多用户情况下,在进行哪些工作之后,系统就迟滞无法正常执行下去。这需要程序开发人员保持良好的开发习惯:事务越晚开启越好,使用资源越少越好,一旦开启了事务迟早关闭,事务执行过程中不要与用户有任何交互,要输入的参数或内容应该在开启事务之前就应该输入完毕,对相关数据的各种校验也要在开启事务之前进行校验,事务应该只是在往数据库中插入更新数据时开启,插入更新完毕之后,就立即关闭。
(五)锁定数据粒度太低或太高
用户设置不当的锁定粒度时,如果设置事务一律使用Row lock或table lock均可能产生问题,或是当系统资源使用过度,也很容易产生被锁定的情形。
建议解决方式
可以通过SQL PROFILER 观察“TextData”字段所呈现的SQL语句,观察该应用程序是否设置了锁定提示,若想要暂时停止锁定提示造成的影响,可以通过以下语句
Dbcc traceon(8755)
或以SQL SERVER 激活参数-T 8755 来停止锁定提示功能,若有改善,可以重新考虑从应用程序从新移除锁定提示的可能性。
(六)Compile Blocking
此现象是由于编译存储过程导致被锁定,在master.sys.sysprocesses视图中或sp_lock存储过程中观察到的等待资源字段中的内容是“COMPILE”,或者使用SQL PROFILER 录制过程中出现大量的“SP:REComplie”事件。由于重新编译需要耗费CPU资源,所以,此种锁定是在一长串的被锁定连接中,单一锁定者锁定时间不长,但整个链接各点都有一点耗时,所以在链接尾端的被锁定者需要等待较长时间。同时会出现CPU的使用率比较高。
当存储过程中使用了缓存数据表,而该缓存数据表还需要设置结构,如需要要设置主键或者利用缓存数据表开打开游标,则每次调用该存储过程进,都会要求重新编译。或这个存储过程是当应用程序执行时,常常会被调用的热门存储过程,就会出现Compile Blocking的状况出现。
但存储过程第一次使用时,也会需要编译,所以不要一看到是在等待编译,就识以为是COMPILE Blocking现象。
建议解决方式
使用sp_executesql执行语句,即使用sp_executesql执行SQL语句,SQL语句不会编译为存储过程执行计划的一部分,因此在执行该类语句时,SQL SERVER 会自由的使用高速缓存中的现有语句计划,或者在执行阶段建立新的执行计划,不管任何一种情况,调用存储过程的计划都不会受影响,也不必进行重新编译。
EXECUTE语句也有相同的效果,但不建议你使用。因为使用EXECUTE没有使用SP_EXECUTESQL语句的效率高,因为前者不允许查询参数化。
三、基本原则:
1. 事务不可以跨批处理,语句越短越好,事务期间不要与用户进行交互
2. 小心处理逾时放弃,或者执行错误等情况。
3. 正确建立索引。可以参考本人前面的相关文章。
(如SQL Server 查询性能优化——创建索引原则(一)
SQL Server 查询性能优化——覆盖索引(一)等系列文章)
4. 数据表最好有聚集索引,而且聚集索引的键值不要太大,因为所有的非聚集索引存储的都是聚集索引的键值。不要使用经常需要进行更新的字段做为聚集索引的键值,因为聚集索引一旦进行了变更,则所有的非聚集索引也要跟着进行变更,导致大量的锁定。索引建少了,影响查询效率,建多了,浪费维护的资源与降低新增、修改、删除的效率,所以建好索引之后,要小心观察SQL SERVER 使用索引的情况,将多余的索引删除,对于数据密度大,或者查询条件鉴别率太低的字段不要建立索引。
5. 尽量不要激活Implicit Transaction,以免它长时间的持有事务。
6. 尽量降低事务隔离级别
7. 进行压力测试以了解当大用户量时,交互将造成何种程度的锁定问题。
四、 防止与处理死锁
1.尽量避免或尽快处理锁定,当锁定与被锁定过多时,就可能造成死锁
2.访问资源的顺序要相同。例如连接A先访问资源1,然后访问资源2,而连接B的访问顺序与之相反,则可能发生死锁。不要在开启事务的情况下,调用外部程序,容易造成分布式死锁。
3.让不同的连接使用相同的锁定。或两条连接因为修改相同的资源而互相锁定,如果你的系统对于更新数据的正确性不做强制性要求,可以考虑使用sp_getbindtoken和sp_bindsession两个系统存储过程,让连接共享锁定,则两条连接同时更新数据,也就可能造成数据更新遗失。
例:
use Test go create proc sp_upd_OPINION @OPINIONID varchar(20), @bindToken varchar(255) output as exec sp_getbindtoken @bindToken output update WBK_OPINION set OPINION_VALUE='true' where OPINION_ID=@OPINIONID go create proc sp_upd_OPINION2 @OPINIONID varchar(20), @bindSession varchar(255) output as exec sp_bindsession @bindSession update WBK_OPINION set OPINION_VALUE='False' where OPINION_ID=@OPINIONID go ----在第一个连接中执行 declare @bindToken varchar(255) begin tran exec sp_upd_opinion 'PreEntryIDUse',@bindToken output select * from WBK_OPINION select @@trancount --事务数量为 select @bindToken
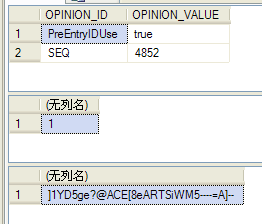
----在第二个连接中执行 ---其中@binToken是由第一个连接执行完毕之后,而获取的 begin tran exec sp_upd_opinion2 'PreEntryIDUse',@bindToken select * from WBK_OPINION select @@trancount --事务数量为
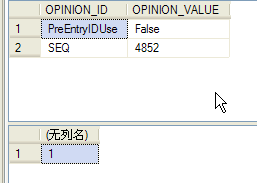
---在第三个连接中执行以下语句,由于不在同一个事务之内,所以会被锁定 update WBK_OPINION set OPINION_VALUE='true' where OPINION_ID='PreEntryIDUse' rollback tran ---回滚
1. 你可以根据以上代码,自行编码相应的测试示例,通过Management studio分别使用三条连接来执行更新示例代码,你会发现享有相同TOKEN的两条连接会一同更新,而其获取的@@TRANCOUNT系统变量也是一样的。而不在同一事务中的其他连接则会被锁住。@@TRANCOUNT也与前述的事务无关。
2.提交不同的数据访问路径。如果两条不同连接的SQL语句,因为抢相同索引而导致死锁,可以考虑为不同的访问语句建立不同的索引,通过索引提示强制让两条连接访问各自的索引。或者是两条不同的连接访问相同的数据表,如果引用不同的索引,但各自的访问顺序正彼此交错,形成死锁,则可强制两条连接使用相同的索引,以维护访问先后秩序。
不管如何,采用此类解决方式时,都要考虑额外的性能损耗,因为你通过索引提示强制了索引访问,让查询优化程序不能凭借数据的特性使用最佳的索引。
五、发生死锁后的处理
通过设置SET DEADLOCK_PRIORITY LOW,让不重要的事务自动放弃,并在这些连接执行的业务逻辑中,加上针对死锁的错误处理。
事实上,在非常复杂的高并发量的系统中,要完全预防死锁,或者要知道什么样的用户在特殊的访问次序中会发生死锁,是非常困难的。所以应用程序应该对死锁错误“1205”要有相应的处理,以完成原有的业务逻辑的处理或是善后清除处理。