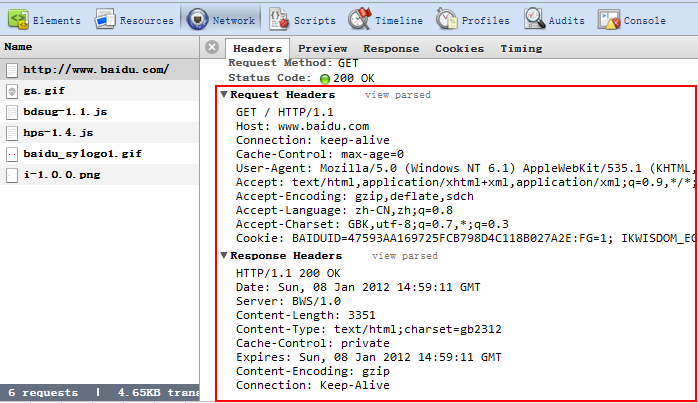
相信大家都知道常用的请求方式也就是"Get"和“Post”,那么下面就来探究下Get和Post都有哪些好玩的地方,还是上图说话,首先
我输入www.baidu.com,会找到如下的请求和响应的信息。
1: “Request Header“:
第一行: Get / Http/1.1
这里面有三个信息:①"Get",表示请求的模式。 ②“/",请求网站的根目录。 ③"http/1.1",这个就是http的版本。
第二行: Host
请求目标的网站,跟“/"并一起就是"www.baidu.com/"。
第三行: Connection
默认为“keep-Alive“,这里就是文章开头所说的默认支持长连接。
第四行: Cache-Control
这玩意跟缓存有关,其中max-age表示缓存的时间(s)。
第五行:User-Agent
告诉serve我client的身份,一般由浏览器决定,比如:浏览器类型,版本等等。
第六行:Accept
以及后面的Accept打头的都是表明client能够接收的种类和类型。
最后一行:Cookie
如果我们第一次向baidu请求时是没有cookie信息这一栏的,因为在浏览器下找不到于baidu相关的cookie,
当我们第二次刷新页面时,get请求就会找到本地的cookie并附带给server。
2: "Response Header":
第一行: Http/1.1 200 OK
这个估计大家都知道吧,200表示返回的状态码,OK则是描述性的状态码。
第二行:Date
表示服务器响应的时间。
第三行: Server
响应客户端的服务器。
第四行:Content-Length
表示服务器返回给客户端正文的字节流长度。
第五行:Content-Type
表示正文的类型。
第七行:Expires
告诉client绝对的过期时间,比如2012.1.10,在这个时间内client都可以不用发送请求而直接从client的cache中获取,
对js,css,image的缓存很有好处,所以说用好了这个属性对我们http的性能有很大的帮助。
第八行:Content-Encoding
文档类型的编码方式,服务器端采用gzip的形式进行了文档压缩,此时减小了文档,利于下载,但是必须client端支持
gzip的解码操作。
post的方式也是一样的,这里就不说了,上面列举了这么多也是希望大家能够对Http的细节要有一定程度的掌握。