转载于http://www.cnblogs.com/kevingrace/p/8012792.html
之前简单介绍了CentOS下单机部署RabbltMQ环境的操作记录,下面详细说下RabbitMQ集群知识,RabbitMQ是用erlang开发的,集群非常方便,因为erlang天生就是一门分布式语言,但其本身并不支持负载均衡。
Rabbit集群模式大概分为以下三种:单一模式、普通模式、镜像模式,其中:
1)单一模式:最简单的情况,非集群模式,没什么好说的。
2)普通模式:默认的集群模式。
-> 对于Queue来说,消息实体只存在于其中一个节点,A、B两个节点仅有相同的元数据,即队列结构。
-> 当消息进入A节点的Queue中后,consumer从B节点拉取时,RabbitMQ会临时在A、B间进行消息传输,把A中的消息实体取出并经过B发送给consumer。
-> 所以consumer应尽量连接每一个节点,从中取消息。即对于同一个逻辑队列,要在多个节点建立物理Queue。否则无论consumer连A或B,出口总在A,会产生瓶颈。
-> 该模式存在一个问题就是当A节点故障后,B节点无法取到A节点中还未消费的消息实体。
-> 如果做了消息持久化,那么得等A节点恢复,然后才可被消费;如果没有持久化的话,然后就没有然后了。
3)镜像模式:把需要的队列做成镜像队列,存在于多个节点,属于RabbitMQ的HA方案。
-> 该模式解决了上述问题,其实质和普通模式不同之处在于,消息实体会主动在镜像节点间同步,而不是在consumer取数据时临时拉取。
-> 该模式带来的副作用也很明显,除了降低系统性能外,如果镜像队列数量过多,加之大量的消息进入,集群内部的网络带宽将会被这种同步通讯大大消耗掉。
-> 所以在对可靠性要求较高的场合中适用于该模式(比如下面图中介绍该种集群模式)。
RabbitMQ集群中的基本概念:
1)RabbitMQ的集群节点包括内存节点、磁盘节点。顾名思义内存节点就是将所有数据放在内存,磁盘节点将数据放在磁盘。不过,如前文所述,如果在投递消息时,打开了消息的持久化,那么即使是内存节点,数据还是安全的放在磁盘。
2)一个rabbitmq集 群中可以共享 user,vhost,queue,exchange等,所有的数据和状态都是必须在所有节点上复制的,一个例外是,那些当前只属于创建它的节点的消息队列,尽管它们可见且可被所有节点读取。rabbitmq节点可以动态的加入到集群中,一个节点它可以加入到集群中,也可以从集群环集群会进行一个基本的负载均衡。
RabbitMQ集群中有两种节点:
1)Ram内存节点:只保存状态到内存(一个例外的情况是:持久的queue的持久内容将被保存到disk)
2)Disk磁盘节点:保存状态到内存和磁盘。
内存节点虽然不写入磁盘,但是它执行比磁盘节点要好。RabbitMQ集群中,只需要一个磁盘节点来保存状态就足够了;如果集群中只有内存节点,那么不能停止它们,否则所有的状态,消息等都会丢失。
RabbitMQ集群思路:
那么具体如何实现RabbitMQ高可用,我们先搭建一个普通集群模式,在这个模式基础上再配置镜像模式实现高可用,Rabbit集群前增加一个反向代理,生产者、消费者通过反向代理访问RabbitMQ集群。
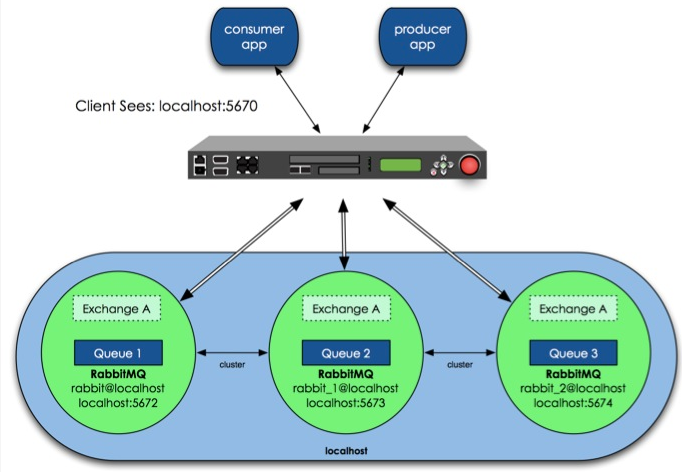
上图中3个RabbitMQ运行在同一主机上,分别用不同的服务端口。当然在生产环境里,多个RabbitMQ肯定是运行在不同的物理服务器上,否则就失去了高可用的意义。
RabbitMQ集群模式配置
该设计架构可以如下:在一个集群里,有3台机器,其中1台使用磁盘模式,另2台使用内存模式。2台内存模式的节点,无疑速度更快,因此客户端(consumer、producer)连接访问它们。而磁盘模式的节点,由于磁盘IO相对较慢,因此仅作数据备份使用,另外一台作为反向代理。
配置RabbitMQ集群非常简单,只需要几个命令,如下面范例,简单说下配置的几个步骤:
第一步:queue、kevintest1、kevintest2做为RabbitMQ集群节点,分别安装RabbitMq-Server ,安装后分别启动RabbitMq-server。
|
1
2
|
启动命令 # Rabbit-Server start |
第二步:在安装好的三台节点服务器中,分别修改/etc/hosts文件,指定queue、kevintest1、kevintest2的hosts。
|
1
2
3
4
5
6
|
172.16.3.32 queue172.16.3.107 kevintest1172.16.3.108 kevintest2 三台节点的hostname要正确,主机名分别是queue、kevintest1、kevintest2,如果修改hostname,建议安装rabbitmq前修改。请注意RabbitMQ集群节点必须在同一个网段里,如果是跨广域网效果就差。 |
第三步:设置每个节点Cookie
|
1
2
3
4
5
6
7
8
9
10
11
12
|
Rabbitmq的集群是依赖于erlang的集群来工作的,所以必须先构建起erlang的集群环境。Erlang的集群中各节点是通过一个magic cookie来实现的,这个cookie存放在/var/lib/rabbitmq/.erlang.cookie 中,文件是400的权限。所以必须保证各节点cookie保持一致,否则节点之间就无法通信。# ll /var/lib/rabbitmq/.erlang.cookie-r-------- 1 rabbitmq rabbitmq 21 12月 6 00:40 /var/lib/rabbitmq/.erlang.cookie将queue的/var/lib/rabbitmq/.erlang.cookie这个文件,拷贝到kevintest1、kevintest2的同一位置(反过来亦可),该文件是集群节点进行通信的验证密钥,所有节点必须一致。拷完后重启下RabbitMQ。复制好后别忘记还原.erlang.cookie的权限,否则可能会遇到错误# chmod 400 /var/lib/rabbitmq/.erlang.cookie设置好cookie后先将三个节点的rabbitmq重启# rabbitmqctl stop# rabbitmq-server start |
第四步:停止所有节点RabbitMq服务,然后使用detached参数独立运行,这步很关键,尤其增加节点停止节点后再次启动遇到无法启动,都可以参照这个顺序
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
[root@queue ~]# rabbitmqctl stop[root@kevintest1 ~]# rabbitmqctl stop[root@kevintest2 ~]# rabbitmqctl stop [root@queue ~]# rabbitmq-server -detached[root@kevintest1 ~]# rabbitmq-server -detached[root@kevintest2 ~]# rabbitmq-server -detached 分别查看下每个节点[root@queue ~]# rabbitmqctl cluster_statusCluster status of node rabbit@queue ...[{nodes,[{disc,[rabbit@queue]}]},{running_nodes,[rabbit@queue]},{partitions,[]}]...done. [root@kevintest1 ~]# rabbitmqctl cluster_statusCluster status of node rabbit@kevintest1...[{nodes,[{disc,[rabbit@kevintest1]}]},{running_nodes,[rabbit@kevintest1]},{partitions,[]}]...done.[root@kevintest2 ~]# rabbitmqctl cluster_statusCluster status of node rabbit@kevintest2...[{nodes,[{disc,[rabbit@kevintest2]}]},{running_nodes,[rabbit@kevintest2]},{partitions,[]}]...done. |
第五步:将kevintest1、kevintest2作为内存节点与queue连接起来,在kevintest1上,执行如下命令:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
[root@kevintest1 ~]# rabbitmqctl stop_app[root@kevintest1 ~]# rabbitmqctl join_cluster --ram rabbit@queue [root@kevintest1 ~]# rabbitmqctl start_app[root@kevintest2 ~]# rabbitmqctl stop_app[root@kevintest2 ~]# rabbitmqctl join_cluster --ram rabbit@queue #上面已经将kevintest1与queue连接,也可以直接将kevintest2与kevintest1连接,同样而已加入集群中[root@kevintest2 ~]# rabbitmqctl start_app1)上述命令先停掉rabbitmq应用,然后调用cluster命令,将kevintest1连接到,使两者成为一个集群,最后重启rabbitmq应用。2)在这个cluster命令下,kevintest1、kevintest2是内存节点,queue是磁盘节点(RabbitMQ启动后,默认是磁盘节点)。3)queue如果要使kevintest1或kevintest2在集群里也是磁盘节点,join_cluster 命令去掉--ram参数即可#rabbitmqctl join_cluster rabbit@queue 只要在节点列表里包含了自己,它就成为一个磁盘节点。在RabbitMQ集群里,必须至少有一个磁盘节点存在。 |
第六步:在queue、kevintest1、kevintest2上,运行cluster_status命令查看集群状态:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
# rabbitmqctl cluster_statusCluster status of node rabbit@queue ...[{nodes,[{disc,[rabbit@queue]},{ram,[rabbit@kevintest2,rabbit@kevintest1]}]},{running_nodes,[rabbit@kevintest2,rabbit@kevintest1,rabbit@queue]},{partitions,[]}]...done.[root@kevintest1 rabbitmq]# rabbitmqctl cluster_statusCluster status of node rabbit@kevintest1 ...[{nodes,[{disc,[rabbit@queue]},{ram,[rabbit@kevintest2,rabbit@kevintest1]}]},{running_nodes,[rabbit@kevintest2,rabbit@queue,rabbit@kevintest1]},{partitions,[]}]...done. [root@kevintest2 rabbitmq]# rabbitmqctl cluster_statusCluster status of node rabbit@kevintest2 ...[{nodes,[{disc,[rabbit@queue]},{ram,[rabbit@kevintest2,rabbit@kevintest1]}]},{running_nodes,[rabbit@kevintest1,rabbit@queue,rabbit@kevintest2]},{partitions,[]}]...done.这时可以看到每个节点的集群信息,分别有两个内存节点一个磁盘节点 |
第七步:往任意一台集群节点里写入消息队列,会复制到另一个节点上,我们看到两个节点的消息队列数一致:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
[root@kevintest2 ~]# rabbitmqctl list_queues -p hrsystemListing queues …test_queue 10000…done.[root@kevintest1 ~]# rabbitmqctl list_queues -p hrsystemListing queues …test_queue 10000…done. [root@queue ~]# rabbitmqctl list_queues -p hrsystemListing queues …test_queue 10000…done. -p参数为vhost名称 |
这样RabbitMQ集群就正常工作了,这种模式更适合非持久化队列,只有该队列是非持久的,客户端才能重新连接到集群里的其他节点,并重新创建队列。假如该队列是持久化的,那么唯一办法是将故障节点恢复起来;为什么RabbitMQ不将队列复制到集群里每个节点呢?这与它的集群的设计本意相冲突,集群的设计目的就是增加更多节点时,能线性的增加性能(CPU、内存)和容量(内存、磁盘)。理由如下:当然RabbitMQ新版本集群也支持队列复制(有个选项可以配置)。比如在有五个节点的集群里,可以指定某个队列的内容在2个节点上进行存储,从而在性能与高可用性之间取得一个平衡。
=============清理RabbitMQ消息队列中的所有数据============
|
1
2
3
4
5
6
|
方法如下:# rabbitmqctl list_queues //查看所有队列数据# rabbitmqctl stop_app //要先关闭应用,否则不能清除# rabbitmqctl reset# rabbitmqctl start_app# rabbitmqctl list_queues //这时候看到listing 及queues都是空的 |
=========================================================================================
RabbitMQ集群:
1)RabbitMQ broker集群是多个erlang节点的逻辑组,每个节点运行rabbitmq应用,他们之间共享用户、虚拟主机、队列、exchange、绑定和运行时参数;
2)RabbitMQ集群之间复制什么信息:除了message queue(存在一个节点,从其他节点都可见、访问该队列,要实现queue的复制就需要做queue的HA)之外,任何一个rabbitmq broker上的所有操作的data和state都会在所有的节点之间进行复制;
3)RabbitMQ消息队列是非常基础的关键服务。本文3台rabbitMQ服务器构建broker集群,1个master,2个slave。允许2台服务器故障而服务不受影响。
RabbitMQ集群的目的
1)允许消费者和生产者在RabbitMQ节点崩溃的情况下继续运行
2)通过增加更多的节点来扩展消息通信的吞吐量
RabbitMQ集群运行的前提:
1)集群所有节点必须运行相同的erlang及rabbitmq版本
2)hostname解析,节点之间通过域名相互通信,本文为3个node的集群,采用配置hosts的形式。
RabbitMQ端口及用途
1)5672 客户端连接用途
2)15672 web管理接口
3)25672 集群通信用途
RabbitMQ集群的搭建方式:
1)通过rabbitmqctl手工配置 (本文采用此方式)
2)通过配置文件声明
3)通过rabbitmq-autocluster插件声明
4)通过rabbitmq-clusterer插件声明
RabbitMQ集群故障处理机制:
1)rabbitmq broker集群允许个体节点down机,
2)对应集群的的网络分区问题( network partitions)
RabbitMQ集群推荐用于LAN环境,不适用WAN环境;要通过WAN连接broker,Shovel or Federation插件是最佳的解决方案;Shovel or Federation不同于集群。
RabbitMQ集群的节点运行模式:
为保证数据持久性,目前所有node节点跑在disk模式,如果今后压力大,需要提高性能,考虑采用ram模式
RabbitMQ节点类型
1)RAM node:内存节点将所有的队列、交换机、绑定、用户、权限和vhost的元数据定义存储在内存中,好处是可以使得像交换机和队列声明等操作更加的快速。
2)Disk node:将元数据存储在磁盘中,单节点系统只允许磁盘类型的节点,防止重启RabbitMQ的时候,丢失系统的配置信息。
问题说明:
RabbitMQ要求在集群中至少有一个磁盘节点,所有其他节点可以是内存节点,当节点加入或者离开集群时,必须要将该变更通知到至少一个磁盘节点。
如果集群中唯一的一个磁盘节点崩溃的话,集群仍然可以保持运行,但是无法进行其他操作(增删改查),直到节点恢复。
解决方案:设置两个磁盘节点,至少有一个是可用的,可以保存元数据的更改。
RabbitMQ集群节点之间是如何相互认证的:
1)通过Erlang Cookie,相当于共享秘钥的概念,长度任意,只要所有节点都一致即可。
2)rabbitmq server在启动的时候,erlang VM会自动创建一个随机的cookie文件。cookie文件的位置是/var/lib/rabbitmq/.erlang.cookie 或者 /root/.erlang.cookie,为保证cookie的完全一致,采用从一个节点copy的方式。
Erlang Cookie是保证不同节点可以相互通信的密钥,要保证集群中的不同节点相互通信必须共享相同的Erlang Cookie。具体的目录存放在/var/lib/rabbitmq/.erlang.cookie。
说明:这就要从rabbitmqctl命令的工作原理说起,RabbitMQ底层是通过Erlang架构来实现的,所以rabbitmqctl会启动Erlang节点,并基于Erlang节点来使用Erlang系统连接RabbitMQ节点,在连接过程中需要正确的Erlang Cookie和节点名称,Erlang节点通过交换Erlang Cookie以获得认证。
=======以下记录CentOS6.9下RabbitMQ集群部署过程=======
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
|
集群机器信息:rabbitmq01.kevin.cn 192.168.1.40rabbitmq02.kevin.cn 192.168.1.41rabbitmq03.kevin.cn 192.168.1.42 1)设置hosts主机解析,rabbitmq 集群通信用途,所有节点配置相同。[root@rabbitmq01 ~]# cat /etc/hosts127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4::1 localhost localhost.localdomain localhost6 localhost6.localdomain6192.168.1.40 rabbitmq01.kevin.cn192.168.1.41 rabbitmq02.kevin.cn192.168.1.42 rabbitmq03.kevin.cn 其他两个节点的hosts配置一致。 2)三台节点服务器上都要部署rabbitmq环境,可以参考:http://www.cnblogs.com/kevingrace/p/7693042.html前台运行rabbitmq服务:# /etc/init.d/rabbitmq-server start (用户关闭连接后,自动结束进程)或者# rabbitmq-server start 设置开机启动# chkconfig rabbitmq-server on 后台运行rabbitmq服务:# rabbitmq-server -detached # lsof -i:5672# lsof -i:15672# lsof -i:25672 查看各节点状态:# rabbitmqctl status或者# /etc/init.d/rabbitmq-server status 3)设置节点间认证的cookie。可以把其中一个节点(比如rabbitmq01)的文件使用scp拷贝到其他两个节点上[root@rabbitmq01 ~]# cat /var/lib/rabbitmq/.erlang.cookieFXQTFVXIUWEBZRLXFQOZ[root@rabbitmq02 ~]# cat /var/lib/rabbitmq/.erlang.cookieFXQTFVXIUWEBZRLXFQOZ[root@rabbitmq03 ~]# cat /var/lib/rabbitmq/.erlang.cookieFXQTFVXIUWEBZRLXFQOZ 同步完cookie之后,重启rabbitmq-server。# /etc/init.d/rabbitmq-server restart 4)为了把集群中的3个节点联系起来,可以将其中两个节点加入到另一个节点中。比如:将rabbitmq01、rabbitmq03分别加入到集群rabbitmq02中,其中rabbitmq01和rabbitmq02节点为内存节点。rabbitmq02为磁盘节点。 注意:rabbitmqctl stop_app ---仅关闭应用,节点不被关闭 [root@rabbitmq01 ~]# rabbitmqctl stop_app[root@rabbitmq01 ~]# rabbitmqctl join_cluster --ram rabbit@rabbitmq02[root@rabbitmq01 ~]# rabbitmqctl start_app [root@rabbitmq03 ~]# rabbitmqctl stop_app[root@rabbitmq03 ~]# rabbitmqctl join_cluster --ram rabbit@rabbitmq02[root@rabbitmq03 ~]# rabbitmqctl start_app 查看RabbitMQ集群情况(三个节点查看的结果一样)[root@rabbitmq01 ~]# rabbitmqctl cluster_statusCluster status of node rabbit@rabbitmq01 ...[{nodes,[{disc,[rabbit@rabbitmq02]}, {ram,[rabbit@rabbitmq03,rabbit@rabbitmq01]}]}, {running_nodes,[rabbit@rabbitmq03,rabbit@rabbitmq02,rabbit@rabbitmq01]}, {cluster_name,<<"rabbit@rabbitmq02.kevin.cn">>}, {partitions,[]}, {alarms,[{rabbit@rabbitmq03,[]}, {rabbit@rabbitmq02,[]}, {rabbit@rabbitmq01,[]}]}] RabbitMQ集群的名字默认是第一个节点的名字,比如上面集群的名字是rabbitmq01。 修改RabbitMQ集群的名字kevinmq# rabbitmqctl set_cluster_name kevinmq# rabbitmqctl cluster_status 重启集群:# rabbitmqctl stop# rabbitmq-server -detached# rabbitmqctl cluster_status //观察集群的运行状态变化 5)重要信息:当整个集群down掉时,最后一个down机的节点必须第一个启动到在线状态,如果不是这样,节点会等待30s等最后的磁盘节点恢复状态,然后失败。如果最后下线的节点不能上线,可以通过forget_cluster_node 指令来踢出集群。 如果所有的节点不受控制的同时宕机,比如掉电,会进入所有的节点都会认为其他节点比自己宕机的要晚,即自己先宕机,这种情况下可以使用force_boot指令来启动一个节点。 6)打破集群:当一个节点不属于这个集群的时候,需要及时踢出,可以通过本地或者远程的方式# rabbitmqctl stop_app# rabbitmqctl reset# rabbitmqctl start_app 这样再次查看RabbitMQ集群的时候,该节点就不会在这里面了# rabbitmqctl cluster_status 7)客户端连接集群测试通过web管理页面进行创建队列、发布消息、创建用户、创建policy等。http://192.168.1.41:15672/或者通过rabbitmqadmin命令行来测试[root@rabbitmq02 ~]# wget https://192.168.1.41:15672/cli/rabbitmqadmin[root@rabbitmq02 ~]# chmod +x rabbitmqadmin[root@rabbitmq02 ~]# mv rabbitmqadmin /usr/sbin/Declare an exchange[root@rabbitmq02 ~]# rabbitmqadmin declare exchange name=my-new-exchange type=fanoutexchange declaredDeclare a queue, with optional parameters[root@rabbitmq02 ~]# rabbitmqadmin declare queue name=my-new-queue durable=falsequeue declaredPublish a message[root@rabbitmq02 ~]# rabbitmqadmin publish exchange=my-new-exchange routing_key=test payload="hello, world"Message publishedAnd get it back[root@rabbitmq02 ~]# rabbitmqadmin get queue=test requeue=false+-------------+----------+---------------+--------------+------------------+-------------+| routing_key | exchange | message_count | payload | payload_encoding | redelivered |+-------------+----------+---------------+--------------+------------------+-------------+| test | | 0 | hello, world | string | False |+-------------+----------+---------------+--------------+------------------+-------------+ |
测试后发现问题问题:
[root@rabbitmq01 ~]# rabbitmqctl stop_app
[root@rabbitmq01 ~]# rabbitmqctl stop
在stop_app或者stop掉broker之后在rabbitmq01节点的上队列已经不可用了,重启rabbitmq01的app或broker之后,虽然集群工作正常,但rabbitmq01上队列中消息会被清空(queue还是存在的)
对于生产环境而已,这肯定是不可接受的,如果不能保证队列的高可用,那么做集群的意义也不太大了,还好rabbitmq支持Highly Available Queues,下面介绍下queue的HA。
=================Queue HA配置===============
默认情况下,RabbitMQ集群中的队列存在于集群中的单个节点上,这要看创建队列时声明在那个节点上创建,而exchange和binding则默认存在于集群中所有节点。
队列可以通过镜像来提高可用性,HA依赖rabbitmq cluster,所以队列镜像也不适合WAN部署,每个被镜像的队列包含一个master和一个或者多个slave,当master
因任何原因故障时,最老的slave被提升为新的master。发布到队列的消息被复制到所有的slave上,消费者无论连接那个node,都会连接到master;如果master确
认要删除消息,那么所有slave就会删除队列中消息。队列镜像可以提供queue的高可用性,但不能分担负载,因为所有参加的节点都做所有的工作。
1. 配置队列镜像
通过policy来配置镜像,策略可在任何时候创建,比如先创建一个非镜像的队列,然后在镜像,反之亦然。
镜像队列和非镜像队列的区别是非镜像队列没有slaves,运行速度也比镜像队列快。
设置策略,然后设置ha-mode,3种模式:all、exactly、nodes。
每个队列都有一个home node,叫做queue master node
1)设置policy,以ha.开头的队列将会被镜像到集群其他所有节点,一个节点挂掉然后重启后需要手动同步队列消息
|
1
|
# rabbitmqctl set_policy ha-all-queue "^ha." '{"ha-mode":"all"}' |
2)设置policy,以ha.开头的队列将会被镜像到集群其他所有节点,一个节点挂掉然后重启后会自动同步队列消息(生产环境采用这个方式)
|
1
|
# rabbitmqctl set_policy ha-all-queue "^ha." '{"ha-mode":"all","ha-sync-mode":"automatic"}' |
2. 问题:
配置镜像队列后,其中1台节点失败,队列内容是不会丢失,如果整个集群重启,队列中的消息内容仍然丢失,如何实现队列消息内容持久化那?
集群节点跑在disk模式,创建见消息的时候也声明了持久化,为什么还是不行那?
因为创建消息的时候需要指定消息是否持久化,如果启用了消息的持久化的话,重启集群消息也不会丢失了,前提是创建的队列也应该是创建的持久化队列。
客户端连接rabbitMQ集群服务的方式:
1)客户端可以连接集群中的任意一个节点,如果一个节点故障,客户端自行重新连接到其他的可用节点;(不推荐,对客户端不透明)
2)通过动态DNS,较短的ttl
3)通过HA+4层负载均衡器(比如haproxy+keepalived)
==========Haproxy+keepalived的部署===============
消息队列作为公司的关键基础服务,为给客户端提供稳定、透明的rabbitmq服务,现通过Haproxy+keepalived构建高可用的rabbitmq统一入口,及基本的负载均衡服务。
为简化安装配置,现采用yum的方式安装haproxy和keepalived,可参考 基于keepalived+nginx部署强健的高可用7层负载均衡方案。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
|
在两台两台服务器部署haproxy+Keepalived环境,部署过程一样。haroxy01.kevin.cn 192.168.1.43haroxy02.kevin.cn 192.168.1.441)安装[root@haproxy01 ~]# yum install haproxy keepalived -y[root@haproxy01 ~]# /etc/init.d/keepalived start2)设置关键服务开机自启动[root@haproxy01 ~]# chkconfig --list|grep haproxy[root@haproxy01 ~]# chkconfig haproxy on[root@haproxy01 ~]# chkconfig --list|grep haproxy3) 配置将haproxy的log记录到 /var/log/haproxy.log[root@haproxy01 ~]# more /etc/rsyslog.d/haproxy.conf$ModLoad imudp$UDPServerRun 514local0.* /var/log/haproxy.log[root@haproxy01 ~]# /etc/init.d/rsyslog restart4)haproxy的配置,2台机器上的配置完全相同[root@haproxy01 ~]# more /etc/haproxy/haproxy.cfg#---------------------------------------------------------------------# Example configuration for a possible web application. See the# full configuration options online.## https://haproxy.1wt.eu/download/1.4/doc/configuration.txt##---------------------------------------------------------------------#---------------------------------------------------------------------# Global settings#---------------------------------------------------------------------global# to have these messages end up in /var/log/haproxy.log you will# need to:## 1) configure syslog to accept network log events. This is done# by adding the '-r' option to the SYSLOGD_OPTIONS in# /etc/sysconfig/syslog## 2) configure local2 events to go to the /var/log/haproxy.log# file. A line like the following can be added to# /etc/sysconfig/syslog## local2.* /var/log/haproxy.log#log 127.0.0.1 local2 noticechroot /var/lib/haproxypidfile /var/run/haproxy.pidmaxconn 4000user haproxygroup haproxydaemon# turn on stats unix socketstats socket /var/lib/haproxy/stats#---------------------------------------------------------------------# common defaults that all the 'listen' and 'backend' sections will# use if not designated in their block#---------------------------------------------------------------------defaultsmode tcpoption tcplogoption dontlognulloption http-server-closeoption redispatchretries 3timeout http-request 10stimeout queue 1mtimeout connect 10stimeout client 1mtimeout server 1mtimeout http-keep-alive 10stimeout check 10smaxconn 3000###haproxy statistics monitor by laijingli 20160222listen statics 0.0.0.0:8888mode httplog 127.0.0.1 local0 debugtransparentstats refresh 60sstats uri / haproxy-statsstats realm Haproxy statisticstats auth laijingli:xxxxx#---------------------------------------------------------------------# main frontend which proxys to the backends#---------------------------------------------------------------------frontend kevin_rabbitMQ_cluster_frontendmode tcpoption tcpkalog 127.0.0.1 local0 debugbind 0.0.0.0:5672use_backend kevin_rabbitMQ_cluster_backendfrontend kevin_rabbitMQ_cluster_management_frontendmode tcpoption tcpkalog 127.0.0.1 local0 debugbind 0.0.0.0:15672use_backend kevin_rabbitMQ_cluster_management_backend#---------------------------------------------------------------------# round robin balancing between the various backends#---------------------------------------------------------------------backend kevin_rabbitMQ_cluster_backendbalance roundrobinserver rabbitmq01.kevin.cn 192.168.1.40:5672 check inter 3s rise 1 fall 2server rabbitmq02.kevin.cn 192.168.1.41:5672 check inter 3s rise 1 fall 2server rabbitmq03.kevin.cn 192.168.1.42:5672 check inter 3s rise 1 fall 2backend kevin_rabbitMQ_cluster_management_backendbalance roundrobinserver rabbitmq01.kevin.cn 192.168.1.40:15672 check inter 3s rise 1 fall 2server rabbitmq02.kevin.cn 192.168.1.41:15672 check inter 3s rise 1 fall 2server rabbitmq03.kevin.cn 192.168.1.42:15672 check inter 3s rise 1 fall 25)keepalived配置,特别注意2台服务器上的keepalived配置不一样。=======================先看下haroxy01.kevin.cn机器上的配置===========================[root@haproxy01 ~]# more /etc/keepalived/keepalived.confglobal_defs {notification_email {wangshibo@kevin.cn102533678@qq.com}notification_email_from notice@kevin.cnsmtp_server 127.0.0.1smtp_connect_timeout 30router_id haproxy43 ## xxhaproxy101 on master , xxhaproxy102 on backup}###simple check with killall -0 which is less expensive than pidof to verify that nginx is runningvrrp_script chk_nginx {script "killall -0 nginx"interval 1weight 2fall 2rise 1}vrrp_instance KEVIN_GATEWAY {state MASTER ## MASTER on master , BACKUP on backupinterface em1virtual_router_id 101 ## KEVIN_GATEWAY virtual_router_idpriority 200 ## 200 on master , 199 on backupadvert_int 1###采用单播通信,避免同一个局域网中多个keepalived组之间的相互影响unicast_src_ip 192.168.1.43 ##本机ipunicast_peer {192.168.1.44 ##对端ip}authentication {auth_type PASSauth_pass 123456}virtual_ipaddress {192.168.1.45 ## VIP}###如果只有一块网卡的话监控网络接口就没有必要了#track_interface {# em1#}track_script {chk_nginx}###状态切换是发送邮件通知,本机记录log,后期会触发短信通知notify_master /usr/local/bin/keepalived_notify.sh notify_masternotify_backup /usr/local/bin/keepalived_notify.sh notify_backupnotify_fault /usr/local/bin/keepalived_notify.sh notify_faultnotify /usr/local/bin/keepalived_notify.sh notifysmtp_alert}###simple check with killall -0 which is less expensive than pidof to verify that haproxy is runningvrrp_script chk_haproxy {script "killall -0 haproxy"interval 1weight 2fall 2rise 1}vrrp_instance kevin_rabbitMQ_GATEWAY {state BACKUP ## MASTER on master , BACKUP on backupinterface em1virtual_router_id 111 ## kevin_rabbitMQ_GATEWAY virtual_router_idpriority 199 ## 200 on master , 199 on backupadvert_int 1###采用单播通信,避免同一个局域网中多个keepalived组之间的相互影响unicast_src_ip 192.168.1.43 ##本机ipunicast_peer {192.168.1.44 ##对端ip}authentication {auth_type PASSauth_pass 123456}virtual_ipaddress {192.168.1.46 ## VIP}###如果只有一块网卡的话监控网络接口就没有必要了#track_interface {# em1#}track_script {chk_haproxy}###状态切换是发送邮件通知,本机记录log,后期会触发短信通知notify_master /usr/local/bin/keepalived_notify_for_haproxy.sh notify_masternotify_backup /usr/local/bin/keepalived_notify_for_haproxy.sh notify_backupnotify_fault /usr/local/bin/keepalived_notify_for_haproxy.sh notify_faultnotify /usr/local/bin/keepalived_notify_for_haproxy.sh notifysmtp_alert}=============================再看下haroxy02.kevin.cn机器上的配置==========================[root@haproxy02 ~]# more /etc/keepalived/keepalived.confglobal_defs {notification_email {wangshibo@kevin.cn102533678@qq.com}notification_email_from notice@kevin.cnsmtp_server 127.0.0.1smtp_connect_timeout 30router_id haproxy44 ## xxhaproxy101 on master , xxhaproxy102 on backup}###simple check with killall -0 which is less expensive than pidof to verify that nginx is runningvrrp_script chk_nginx {script "killall -0 nginx"interval 1weight 2fall 2rise 1}vrrp_instance KEVIN_GATEWAY {state BACKUP ## MASTER on master , BACKUP on backupinterface em1virtual_router_id 101 ## KEVIN_GATEWAY virtual_router_idpriority 199 ## 200 on master , 199 on backupadvert_int 1###采用单播通信,避免同一个局域网中多个keepalived组之间的相互影响unicast_src_ip 192.168.1.44 ##本机ipunicast_peer {192.168.1.43 ##对端ip}authentication {auth_type PASSauth_pass YN_API_HA_PASS}virtual_ipaddress {192.168.1.45 ## VIP}###如果只有一块网卡的话监控网络接口就没有必要了#track_interface {# em1#}track_script {chk_nginx}###状态切换是发送邮件通知,本机记录log,后期会触发短信通知notify_master /usr/local/bin/keepalived_notify.sh notify_masternotify_backup /usr/local/bin/keepalived_notify.sh notify_backupnotify_fault /usr/local/bin/keepalived_notify.sh notify_faultnotify /usr/local/bin/keepalived_notify.sh notifysmtp_alert}###simple check with killall -0 which is less expensive than pidof to verify that haproxy is runningvrrp_script chk_haproxy {script "killall -0 haproxy"interval 1weight 2fall 2rise 1}vrrp_instance kevin_rabbitMQ_GATEWAY {state MASTER ## MASTER on master , BACKUP on backupinterface em1virtual_router_id 111 ## kevin_rabbitMQ_GATEWAY virtual_router_idpriority 200 ## 200 on master , 199 on backupadvert_int 1###采用单播通信,避免同一个局域网中多个keepalived组之间的相互影响unicast_src_ip 192.168.1.44 ##本机ipunicast_peer {192.168.1.43 ##对端ip}authentication {auth_type PASSauth_pass YN_MQ_HA_PASS}virtual_ipaddress {192.168.1.46 ## VIP}###如果只有一块网卡的话监控网络接口就没有必要了#track_interface {# em1#}track_script {chk_haproxy}###状态切换是发送邮件通知,本机记录log,后期会触发短信通知notify_master /usr/local/bin/keepalived_notify_for_haproxy.sh notify_masternotify_backup /usr/local/bin/keepalived_notify_for_haproxy.sh notify_backupnotify_fault /usr/local/bin/keepalived_notify_for_haproxy.sh notify_faultnotify /usr/local/bin/keepalived_notify_for_haproxy.sh notifysmtp_alert}配置中用到的通知脚本,2台haproxy服务器上完全一样:[root@haproxy01 ~]# more /usr/local/bin/keepalived_notify.sh#!/bin/bash###keepalived notify script for record ha state transtion to log files###将将状态转换过程记录到log,便于排错logfile=/var/log/keepalived.notify.logecho --------------- >> $logfileecho `date` [`hostname`] keepalived HA role state transition: $1 $2 $3 $4 $5 $6 >> $logfile###将状态转换记录到nginx的文件,便于通过web查看ha状态(一定注意不要开放到公网)echo `date` `hostname` $1 $2 $3 $4 $5 $6 "" > /usr/share/nginx/html/index_for_nginx.html###将nginx api和rabbitmq的ha log记录到同一个文件里cat /usr/share/nginx/html/index_for* > /usr/share/nginx/html/index.html6)haproxy监控页面。访问地址http://192.168.1.43:88887)查看keepalived中高可用服务运行在那台服务器上https://192.168.1.438)通过VIP访问rabbitMQ服务http://192.168.1.46:56729)其他问题rabbitmq服务客户端使用规范1)使用vhost来隔离不同的应用、不同的用户、不同的业务组2)消息持久化,exchange、queue、message等持久化需要在客户端声明指定 |