在开发新需求时,需要基于现有数据管理类进行扩展,在完成该项目的过程中,发现需要更加全面深入的了解,因此有了本篇文章,全面分析现有数据管理类的设计思路,分析现有设计优缺点,为后续改进提供方向。
背景介绍
上层业务繁多,各个业务和各个数据之间形成网状交叉,存在多个业务方依赖相同数据的场景,如果不加以统一管理,会增加流量消耗,减慢响应速度。
较为理想的数据请求逻辑是,同一类数据请求在只维护一个实例,各个业务方按需请求,支持数据缓存以及发布订阅。
为了达到上述目标,抽象出 数据管理类,它的核心职责如下:
- 管理数据请求的全生命周期:包括创建请求、发送请求、取消请求以及响应请求
- 管理请求缓存:同类型数据已存一份,对业务方提供统一读取接口
- 支持发布订阅:通过定时驱动数据查询,并主动推送给各业务方
整体设计
通过梳理现有实现,去掉无关代码,提炼出如下类图:
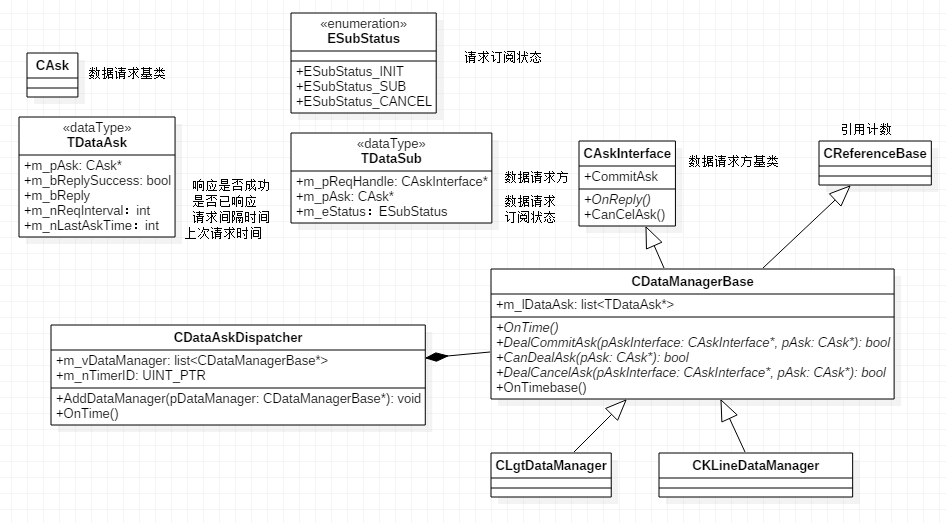
核心类为 CDataManagerBase,每类业务数据的管理,都需要以它为父类,并纳入到 CDataAskDispatch 类中,以便融入现有的请求响应处理框架和定时处理框架。
上图中的 CLgtDataManager 类,就是负责 Lgt 业务数据的具体类,数据缓存以及读写接口在该类中提供。
核心接口
从业务使用方来看,核心接口有以下五个:
CanDealAsk: 决定自身能否处理该请求DealCommitAsk:处理请求发送DealCancelAsk:处理请求取消OnReply: 处理请求响应OnTime: 处理定时任务
接下来分析如何通过核心接口,实现上面提到的三个核心职责
管理数据请求的全生命周期
- 请求发送
在项目中,使用 引用计数 (具体由 CReferenceBase 类实现)来管理请求的生命周期。由各个业务方创建请求,转交给数据管理类。这里需要注意,数据管理类是直接使用业务方的请求还是根据业务方数据创建新的请求?
刚开始实现时,笔者采用直接使用业务方的请求,增加引用后保存起来的方法。初版实现提交后,经过评审,上级提出这样不妥,原因如下:
- 管理类持有上层业务方的请求引用
- 不采用引用计数保存。那么如果上层界面销毁该指针,那么管理类就持有无效指针,这是非常危险的。
- 采用引用计数保存,则请求在管理类中始终保留一份引用,业务方失去了对该请求生命周期的掌控,业务方释放该请求,本以为释放了,其实还没释放,这个会带来隐藏的内存泄露。
因此,采用方案2,根据业务方的请求数据,数据管理类创建自己的请求。这样一来,与业务方解耦。业务方对请求的管理能做到一一对应。
晚上回去想了想,这里想要达到的是数据层持有一份ask,但又不增加对应引用,std::weak_ptr可以用在这个场景中。但 std::weak_ptr 是配合 std::shared_ptr 来使用的,目前项目中没有使用智能指针,所以,此方案作罢。
- 请求取消
业务方可以随时取消请求,这里可进一步细分为 取消请求响应 和 取消请求订阅。
-
取消请求响应
- 该功能由请求响应框架负责。当取消请求响应时,框架会删除底层请求与发送方的关联关系,当响应数据到了,由于找不到响应数据对应的发送方,也就无法通知发送方。
-
取消请求订阅
- 由实际的数据管理类实现。当取消请求订阅时,会根据请求,找到对应的订阅实例并删除。这样,当订阅请求的响应数据到达时,找不到对应的订阅实例,无法通知订阅方。
看了下,在目前的取消实现中,只处理了情况2,未处理情况1,可能会造成不必要的数据请求,在后续实现中可以改进。
- 请求响应
请求响应,正常来说是哪个业务方发起的请求,响应数据就回调给哪个业务方。这个由请求响应框架负责,在数据管理类中不用考虑。
管理请求缓存
不同业务方对于数据的时效性不同,有的只接受最新数据,有的接收内存缓存数据,有的接收硬盘缓存数据。因此,需要在请求时,根据不同时效性要求,选择不同的缓存方案。
- 只接收最新数据: 数据管理类不进行数据缓存,任何请求来了发给后台。
- 接受内存缓存数据:当有数据请求时,如内存中有缓存数据,则先返回给业务方,同时,开启定时请求,并推送数据给业务方。
- 接受硬盘缓存数据:程序启动时,读取硬盘数据来初始化内存缓存,后续流程同2)。
这里需要注意:不能假定缓存数据的生产者和消费者在同一线程,因此,对缓存的操作要加锁,为进一步提高效率,可进行如下优化:
- 考虑到缓存数据是读多写少,采用读写锁,提高加锁效率。
- 一条数据有很多子项,业务方存在同时使用所有子项,也存在在不同函数使用不同子项,为减少加锁消耗,可进一步做缓存,针对每条数据,首次访问时加锁,后续再访问其中子项时,不再加锁;访问新的数据时再加锁。
- 缓存持久化。根据时效性策略,将响应数据持久化到硬盘。
支持发布订阅
数据管理类对每个业务方的请求,自动增加订阅功能。如果业务方不希望订阅,可在响应后取消订阅。
具体的发布功能,通过每个指令设定好的定时间隔,配合定时驱动来实现,当同类数据响应后,通知各个订阅方,以达到节省流量和实时通知。
为提高效率,可对发布/订阅机制做如下设计:
- 当业务方在订阅响应中进行取消订阅时,此时不能删除订阅实例,而是要等响应完成后再删除。
- 同类数据,至少有1个业务方继续订阅,就要定时请求并通知。无业务方时,不再请求
- 订阅查询超时间隔设置设计:
4.1 当订阅请求响应错误时,可缩短定时间隔进行重试,若失败到设定次数,不再请求,等待设定时间后恢复请求。
4.2 当订阅请求响应成功时,更新下次定时间隔,使其达到上次响应与下次实际请求之间的时间等于设定的时间间隔。
4.3 当订阅请求尚未回复时,如果超出设定的超时时间,认定为响应出错,转流程4.1处理。 - 考虑时间记录值回转
一般通过比较当前时间与上次请求发送时间是否超过时间间隔,来决定请求发送。考虑这种情况,程序运行很长时间,当前时间记录值已溢出了,小于上次请求发送时间,此时可以这样处理。
当发生溢出时,我们只需要知道 当前时间 与 上次发送时间之间的间隔绝对值,只要间隔绝对值超过设定的值,就需要重发。
// nLastAskTime 为上次发送时间. curTime 为当前时间 nSetAskInterval 为定时间隔
unsigned long nInterval = unsigned long(-1) - nLastAskTime + curTime;
if (nInterval > nSetAskInterval)
{
bNeedReSend = true;
}
unsigned long(-1) - nLastAskTime是求出尚未溢出的值距离最大数值的距离,加上当前时间 curTime,得到实际的时间间隔,如果大于设定的时间间隔,则需要重发请求。
小结
本文总结了数据管理类设计的方案要点,一个良好的数据管理类,需要完成以下职责:
- 管理数据请求的全生命周期,包括发送请求、取消请求以及响应请求
- 管理请求缓存
- 支持发布订阅
经过上述分析和思考,数据管理模块未来可从以下几点改进:
- 更精细化的订阅请求管理。例如:支持同类请求不同的订阅间隔等
- 更好的可扩展性。
- 将通用操作提升到基类,提供更多辅助函数,降低开发新业务数据管理类时的心智负担。
- 实现通用数据管理类,数据类型由外部注入,降低重复代码。
- 增加更完善的日志记录,方便维护和查问题。