好记性,不如烂笔头
mybatis的搭建:https://www.cnblogs.com/xdp-gacl/p/4261895.html
ssm的mybatis 的配置:
https://www.cnblogs.com/aeolian/p/9143730.html
https://blog.csdn.net/u010013573/article/details/87860078
单纯使用mybatis框架,配置:
1.创建实体类 2.创建mapping.xml映射数据的xml映射文件 3.创建conf.xml的配置文件(文件内容是配置连接数据库的数据,和mapping.xml建立映射关系)
<mappers> <!-- 注册userMapper.xml文件, userMapper.xml位于me.gacl.mapping这个包下,所以resource写成me/gacl/mapping/userMapper.xml--> <mapper resource="mapping/userMapper.xml"/> </mappers>
2.使用spring框架:
如果使用mapper接口的话配置如下(spring的配置方法):
mapperLocations的作用(https://www.cnblogs.com/1xin1yi/p/7373739.html)
<!-- 让spring管理sqlsessionfactory 使用mybatis和spring整合包中的 -->
<bean id="sessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean"> <property name="dataSource" ref="datasource"></property> <property name="typeAliasesPackage" value="com.fan.entity"/> <!-- 当mybatis的xml文件和mapper接口不在相同包下时,需要用mapperLocations属性指定xml文件的路径。 *是个通配符,代表所有的文件,**代表所有目录下 --> <property name="mapperLocations" value="classpath:com/fan/mapper/*.xml" /> <!--也可以引入mybatis配置文件 <property name="configLocation" value="classpath:mybatis/SqlMapConfig.xml"></property> --> </bean> <!-- 通过扫描的模式,扫描目录在com.lanyuan.mapper目录下的mapper--> <bean class="org.mybatis.spring.mapper.MapperScannerConfigurer"> <property name="basePackage" value="com.fan.mapper"></property> </bean>
结论是:如果Mapper.xml与Mapper.class在同一个包下且同名,spring扫描Mapper.class的同时会自动扫描同名的Mapper.xml并装配到Mapper.class。
如果Mapper.xml与Mapper.class不在同一个包下或者不同名,就必须使用配置mapperLocations指定mapper.xml的位置。
此时spring是通过识别mapper.xml中的 <mapper namespace="com.fan.mapper.UserDao"> namespace的值来确定对应的Mapper.class的。
如果使用mapper接口的话,则需要创建mapper接口,mapping.xml的namespace的值=接口的包名+接口的类名,2. 接口中方法名 = mapper.xml中 具体的SQL语句定义的id值;
3.方法的返回值和参数要和映射文件中一致(当数据库的字段名和对象的属性名一致时,可以用简单属性resultType。但是当数据库中的字段名称和对象中的属性名称不一致时,就需要resultMap属性。
接口开发的三个特点
1、 Mapper接口方法名和mapper.xml中定义sql的id值相同
2、 Mapper接口方法接收的参数类型和mapper.xml中定义的sql 的parameterType的类型相同
3、 Mapper接口方法的返回值类型和mapper.xml中定义的sql的resultType的类型相同
Mapper接口开发需要遵循以下规范:
1、 Mapper.xml文件中的namespace与mapper接口的类路径相同。
2、 Mapper接口方法名和Mapper.xml中定义的每个statement的id相同
3、 Mapper接口方法的输入参数类型和mapper.xml中定义的每个sql 的parameterType的类型相同
4、 Mapper接口方法的输出参数类型和mapper.xml中定义的每个sql的resultType的类型相同
mybatis:
1.首先在数据库创建相应的表如 user.java,2.然后创建实体类,实体类的属性名字和表的字段名要一致,3.然后创建mapper.xml文件进行映射 4.然后将mapper.xml映射文件的路径放到conf.xml中,conf.xml是配置连接数据的相关信息的(为什么没有建立mapper接口呢,因为这个样子就可以实现基本的增删改查,建立mapper接口一般多应用在框架中,直接调用接口来调用方法,包括引入mapper.xml文件。可以直接引入整个包下面的mapper接口即可,当然namespace的名字要和mapper接口的名字一样,这样xml文件才能找到相应的接口,为什么接口不需要写实现类呢,实际上xml文件就是实现类,实现了接口的方法,不是吗)
补充:关于mapper.xml的namespace -- 为这个mapper指定一个唯一的namespace,namespace的值习惯上设置成包名+sql映射文件名,这样就能够保证namespace的值是唯一的
例如namespace="me.gacl.mapping.userMapper"就是me.gacl.mapping(包名)+userMapper(userMapper.xml文件去除后缀)
<select id="getUser" parameterType="int" resultType="me.gacl.domain.User"> select * from users where id=#{id} </select>
resultType和resultMap的用法:https://blog.csdn.net/qq_42780864/article/details/81429114#commentBox(这个说的很好,很详细)
resultType
resultType可以把查询结果封装到pojo类型中,但必须pojo类的属性名和查询到的数据库表的字段名一致。
如果sql查询到的字段与pojo的属性名不一致,则需要使用resultMap将字段名和属性名对应起来,进行手动配置封装,将结果映射到pojo中
resultMap
resultMap可以实现将查询结果映射为复杂类型的pojo,比如在查询结果映射对象中包括pojo和list实现一对一查询和一对多查询。
使用association映射关联对象User的结果集,association后面配置的是被关联的对象,比如A对象里面关联了B,则association B
配置resultMap标签,映射不同的字段和属性名
<!-- resultMap最终还是要将结果映射到pojo上,type就是指定映射到哪一个pojo --> <!-- id:设置ResultMap的id --> <resultMap type="order" id="orderResultMap"> <!-- 定义主键 ,非常重要。如果是多个字段,则定义多个id --> <!-- property:主键在pojo中的属性名 --> <!-- column:主键在数据库中的列名 --> <id property="id" column="id" /> <!-- 定义普通属性 --> <result property="userId" column="user_id" /> <result property="number" column="number" /> <result property="createtime" column="createtime" /> <result property="note" column="note" /> </resultMap>
结果就可以封装到pojo类型中
使用parameterType属性指明查询时使用的参数类型,id="getuser",如果与mapper接口的话,getuser和mapper接口里米方法名字是一样的
resultType属性指明查询返回的结果集类型
resultType="me.gacl.domain.User"就表示将查询结果封装成一个User类的对象返回
二、假如表字段和实体类属性名字不一致怎么办?
详细可见:https://www.cnblogs.com/xdp-gacl/p/4264425.html
其中一种方法:可以通过resultmap标签来实现
<id property="id" column="order_id"/> ,id表示实体类属性的名字,colum表示表字典的名字,这样就算不一致,也可以一一映射了,还可以通过sql
这是因为我们将查询的字段名都起一个和实体类属性名相同的别名,这样实体类的属性名和查询结果中的字段名就可以一一对应上
比如:这里order_id是表的字段名,id是实体类的属性名,通过这样也可以映射的上
<select id="selectOrder" parameterType="int" resultType="me.gacl.domain.Order"> select order_id id, order_no orderNo,order_price price from orders where order_id=#{id} </select>
一对一经典:关于<resultMap>标签,因为条件是c_id是class的,所以type="",就是class的,id应该是和上面的保持一致,内容都是class的映射;而association的是关联出来的,那么下面的内容就写teacher的

新知识:关于
<sql id="Base_Column_List" >
user_id, user_name, user_birthday, user_salary
</sql>这个意思就是我定义了这些个字段,
<include refid="Base_Column_List" />就是把这些字段引入到sql
<sql id="Base_Column_List" > user_id, user_name, user_birthday, user_salary </sql> <select id="selectByPrimaryKey" resultMap="BaseResultMap" parameterType="java.lang.String" > select <include refid="Base_Column_List" /> 等于把user_id, user_name, user_birthday, user_salary这些字段引入到sql语句了,如果有大量重复性需要写这些字段的,估计是显得高级点,或者省事吧
from t_user where user_id = #{userId,jdbcType=CHAR} </select>
经典mapper.xml解析:
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" > <mapper namespace="me.gacl.dao.UserMapper" > <resultMap id="BaseResultMap" type="me.gacl.domain.User" >这儿的resultmap的作用就是将实体类属性名和表字段名不一致的映射起来,方便后面的操作 <id column="user_id" property="userId" jdbcType="CHAR" /> <result column="user_name" property="userName" jdbcType="VARCHAR" /> <result column="user_birthday" property="userBirthday" jdbcType="DATE" /> <result column="user_salary" property="userSalary" jdbcType="DOUBLE" /> </resultMap> <sql id="Base_Column_List" > 这儿就是定义一下这些字段,后面不需要重复写,直接引用即可 user_id, user_name, user_birthday, user_salary </sql> <select id="selectByPrimaryKey" resultMap="BaseResultMap" parameterType="java.lang.String" > select <include refid="Base_Column_List" /> 这儿就 引用了上面的<sql>标签 from t_user where user_id = #{userId,jdbcType=CHAR} </select> <delete id="deleteByPrimaryKey" parameterType="java.lang.String" > delete from t_user where user_id = #{userId,jdbcType=CHAR} </delete> <insert id="insert" parameterType="me.gacl.domain.User" > insert into t_user (user_id, user_name, user_birthday, user_salary) values (#{userId,jdbcType=CHAR}, #{userName,jdbcType=VARCHAR}, #{userBirthday,jdbcType=DATE}, #{userSalary,jdbcType=DOUBLE}) </insert> <insert id="insertSelective" parameterType="me.gacl.domain.User" > insert into t_user <trim prefix="(" suffix=")" suffixOverrides="," > <if test="userId != null" > user_id, </if> <if test="userName != null" > user_name, </if> <if test="userBirthday != null" > user_birthday, </if> <if test="userSalary != null" > user_salary, </if> </trim> <trim prefix="values (" suffix=")" suffixOverrides="," > <if test="userId != null" > #{userId,jdbcType=CHAR}, </if> <if test="userName != null" > #{userName,jdbcType=VARCHAR}, </if> <if test="userBirthday != null" > #{userBirthday,jdbcType=DATE}, </if> <if test="userSalary != null" > #{userSalary,jdbcType=DOUBLE}, </if> </trim> </insert> <update id="updateByPrimaryKeySelective" parameterType="me.gacl.domain.User" > update t_user <set > <if test="userName != null" > user_name = #{userName,jdbcType=VARCHAR}, </if> <if test="userBirthday != null" > user_birthday = #{userBirthday,jdbcType=DATE}, </if> <if test="userSalary != null" > user_salary = #{userSalary,jdbcType=DOUBLE}, </if> </set> where user_id = #{userId,jdbcType=CHAR} </update> <update id="updateByPrimaryKey" parameterType="me.gacl.domain.User" > update t_user set user_name = #{userName,jdbcType=VARCHAR}, user_birthday = #{userBirthday,jdbcType=DATE}, user_salary = #{userSalary,jdbcType=DOUBLE} where user_id = #{userId,jdbcType=CHAR} </update> <!-- ==============以下内容是根据自身业务扩展的内容======================= --> <!-- select标签的id属性与UserMapper接口中定义的getAllUser方法要一模一样 --> <select id="getAllUser" resultMap="BaseResultMap"> 这儿的resultMap="BaseResultMap"在上面就是定义过得那个,所以可以直接映射了
select user_id, user_name, user_birthday, user_salary from t_user </select> </mapper>
Mybatis为什么要加@params,mapper里面如果只有一个参数的话,可以不加,如果多个参数则需要加。不使用@Param注解时,参数只能有一个,并且是Javabean。
https://blog.csdn.net/youanyyou/article/details/79406486
https://blog.csdn.net/qq_39505065/article/details/90550705
@param给参数起别名,例如@params(“abcd”)String aa,那么sql中就要写入你定义的名字#{abcd}
建议全部用@param,给映射器方法中的每个参数来取一个名字。否则,多参数将会以它们的顺序位置和SQL语句中的表达式进行映射,这是默认的。
@Param Parameter N/A 如果你的映射器的方法需要多个参数, 这个注解可以被应用于映射器的方法 参数来给每个参数一个名字。否则,多 参数将会以它们的顺序位置来被命名 (不包括任何 RowBounds 参数) 比如。 #{param1} , #{param2} 等 , 这 是 默 认 的 。 使 用 @Param(“person”) xiaoming,参数应该被命名为 #{person}。
像String accountId的名字可以随意定义了,定义为String abc什么的都是不影响的了
public int insertRefundInfo(@Param("account_id")String accountId, @Param("trade_no")String tradeNo, @Param("pay_node_code")String payNodeCode, @Param("pay_interface_code")String payInterfaceCode, @Param("partner_id")String partnerId,@Param("app_id")String appId, @Param("out_trade_no")String outTradeNo, @Param("channel_trade_no")String channelTradeNo, @Param("refund_no")String refundNo, @Param("refund_fee")String refundFee, @Param("refund_time")Date refundTime, @Param("refund_status")String refundStatus, @Param("buyer_logon_id")String buyerLogonId,@Param("store_id")String storeId,@Param("terminal_id")String terminalId,@Param("operator_id")String operatorId,@Param("area_code")String areaCode);
而且, #{ } 中的属性必须与 @Param中定义的一致,eg: @Param("username")user_name , 那么#{username} ,要和@Param括号里定义的名字一致这样才可以。
见:https://blog.csdn.net/mrqiang9001/article/details/79520436#commentBox
PS :反正都用上@params,否则可能会报错,也不直观
不使用@param注解传递多个参数的情况
使用jdk1.7可以用这些参数来传参1, 0, param1, param2
使用1.8可以用这些参数来传参 arg1, arg0, param1, param2
比如:dao层
List<User> demo(int userid, String name);
使用上面说的这些来传参,0表示userid的参数,1表示name
<select id="demo" resultMap="User">
select *
from user where user_id=#{0} and name= #{1}
</select>
jdk1.8之后
第一种,用arg0,和1.7类似的意思
<select id="demo" resultMap="User">
select *
from user where user_id=#{arg0} and name= #{arg1}
</select>
第二种使用 param1
<select id="demo" resultMap="User">
select *
from user where user_id=#{param0} and name= #{param1}
</select>
@Param注解传参法
public User selectUser(@Param("userName") String name, int @Param("deptId") deptId);
<select id="selectUser" resultMap="UserResultMap">
select * from user
where user_name = #{userName} and dept_id = #{deptId}
</select>
可以看出使用@Param要直观很多,参考:https://blog.csdn.net/qq_39505065/article/details/90550705
association和collection的区别:
参考链接: https://www.cnblogs.com/deng-cc/p/9337601.html
之前我们提到的映射,都是简单的字段和对象属性一对一,假设对象的属性也是一个对象,即涉及到两个表的关联,此时应该如何进行映射处理?
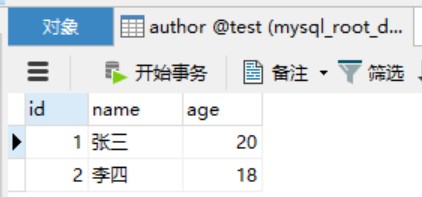
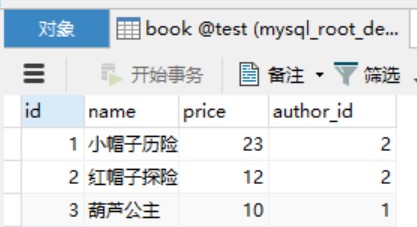
public class Book {
private long id;
private String name;
private int price;
private Author author;
//... getter and setter
}
public class Author {
private long id;
private String name;
private int age;
private List<Book> bookList;
//... getter and setter
}
1、association 关联
1.1 method1
mapper namespace="dulk.learn.mybatis.dao.BookDao">
<resultMap id="bookResultMap" type="dulk.learn.mybatis.pojo.Book">
<id property="id" column="id" />
<result property="name" column="name" />
<result property="price" column="price" />
<!--关联属性-->
<association property="author" javaType="dulk.learn.mybatis.pojo.Author">
<!--注:此处column应为book中外键列名-->
<id property="id" column="author_id" />
<!--注:避免属性重名,否则属性值注入错误-->
<result property="name" column="authorName" />
<result property="age" column="authorAge" />
</association>
</resultMap>
<!--嵌套查询,结果映射只能使用resultMap-->
<select id="findBookById" parameterType="long" resultMap="bookResultMap">
SELECT
b.*,
a.name AS 'authorName',
a.age AS 'authorAge'
FROM book b, author a
WHERE b.author_id = a.id
AND b.id = #{id}
</select>
</mapper>
- property - 关联对象在类中的属性名(即Author在Book类中的属性名,author)
- javaType - 关联对象的Java类型
- id中的column属性,其值应该尽量使用外键列名,主要是对于重名的处理,避免映射错误
- 同样的,对于result中的column属性的值,也要避免重名带来的映射错误,如上例若 a.name 不采用别名 "authorName",则会错误地将 b.name 赋值给Author的name属性
1.2 method2
<mapper namespace="dulk.learn.mybatis.dao.BookDao">
<!--author的resultMap-->
<resultMap id="authorResultMap" type="dulk.learn.mybatis.pojo.Author">
<id property="id" column="authorId"/>
<result property="name" column="authorName"/>
<result property="age" column="authorAge"/>
</resultMap>
<resultMap id="bookResultMap" type="dulk.learn.mybatis.pojo.Book">
<id property="id" column="id"/>
<result property="name" column="name"/>
<result property="price" column="price"/>
<!--引用author的resultMap-->
<association property="author" resultMap="authorResultMap" />
</resultMap>
<!--注意这里a.id的别名和authorResultMap中相对应-->
<select id="findBookById" parameterType="long" resultMap="bookResultMap">
SELECT
b.*,
a.id AS 'authorId',
a.name AS 'authorName',
a.age AS 'authorAge'
FROM book b, author a
WHERE b.author_id = a.id
AND b.id = #{id}
</select>
</mapper>
1.3 method3
<mapper namespace="dulk.learn.mybatis.dao.BookDao">
<resultMap id="bookResultMap" type="dulk.learn.mybatis.pojo.Book">
<id property="id" column="id"/>
<result property="name" column="name"/>
<result property="price" column="price"/>
<!--使用select属性进行查询关联-->
<association property="author" column="author_id" javaType="dulk.learn.mybatis.pojo.Author" select="findAuthorById"/>
</resultMap>
<!--简化了book的查询语句,不再需要与其他表关联-->
<select id="findBookById" parameterType="long" resultMap="bookResultMap">
SELECT b.*
FROM book b
WHERE b.id = #{id}
</select>
<!--新增了author表的查询语句,将会被调用获取结果并组装给book-->
<select id="findAuthorById" parameterType="long" resultType="dulk.learn.mybatis.pojo.Author">
SELECT *
FROM author
WHERE id = #{id}
</select>
</mapper>
2、collection 集合
<mapper namespace="dulk.learn.mybatis.dao.AuthorDao">
<resultMap id="authorResultMap" type="dulk.learn.mybatis.pojo.Author">
<id property="id" column="id"/>
<result property="name" column="name" />
<result property="age" column="age" />
<!--使用collection属性,ofType为集合内元素的类型-->
<collection property="bookList" ofType="dulk.learn.mybatis.pojo.Book" columnPrefix="book_">
<id property="id" column="id"/>
<result property="name" column="name" />
<result property="price" column="price" />
</collection>
</resultMap>
<select id="findById" parameterType="long" resultMap="authorResultMap">
SELECT a.*, b.id AS 'book_id', b.name AS 'book_name', b.price AS 'book_price'
FROM author a, book b
WHERE a.id = b.author_id
AND a.id = #{authorId}
</select>
</mapper>
- 第一种即 column 的值和列名完全一致,如 column="book_id"
- 第二种也就是推荐的方式,在 collection 中使用属性 columnPrefix 来定义统一前缀,在接下来的 column 中就可以减少工作量了,如上例中 columnPrefix = "book_",column = "id",它们的效果等同于 column = "book_id"