因为没书,又因为需要这个知识,所以在网上找资源看电子书,学完了就看博文再学sql知识,再巩固一下
推荐一个好地方,菜鸟工具,那里有许多教程
ps:里面的许多实例是看的视频,然后自己写的,所以没写详情的内容对数据库...2333
sql server 2005的自学笔记
还有就是命名的问题,这是最后写的,对于表的命名,可以不写as,也可以不加双引号,直接写就行了,但是名称和表之间要有空格。我下面写的有点繁琐...格式的优化可以看目录自连接后的,那都比较好点...
库有两种:系统默认的库、自己建的库
什么是数据库?
侠义:存储数据的仓库
广义:可以对数据进行存储和管理的软件以及数据本身统称为数据库
数据库是由表、关系、操作组成的。
为什么要数据库?
几乎所有的应用软件的后台都需要数据库
数据库存储的空间小,容易持久保存
一般都是mdf,ldf后缀的这两个文件(数据库移植较容易)
存储比较安全
容易维护和升级
简化对数据的操作
为将来的学习oracle准备
b/s架构包含数据库
db又叫数据库
ps:如果连接不上,可能没开启对应的sql服务,建议在附件那里找服务,然后启用sql server 服务
数据结构和数据库的区别
都是研究数据的存储与操作
数据库是在应用软件级别研究数据的存储和操作
数据结构是在系统软件级别研究数据的存储与操作
什么是连接
sql server是客户端,是访问后台的数据库,库和访问库不一样,
只有对应的数据库服务开启,才能去连接数据库,所以连接很重要
命令只能单行发送,不能一块发送
数据库是如何存储的?
字段、记录、表、属性、约束(主键、外键、唯一键、非空、check、default)、触发器
数据库是如何操作的
insert、update、delete、T-SQL、存储过程、函数、、触发器
如何显示数据
select等
为什么会有系统库?
用户创建的库需要系统来维护,最核心的是master,不能删,改,否则会影响系统数据正常
新建数据库-----数据库--右键---新建
数据库创建有两个文件,一个是数据文件,一个是日志文件,用于记录操作
删除库直接右键删除---点击关闭现有连接删除会更好,在删除不了的情况下。类似关闭相关进程
数据库如何分离和附加
不能直接复制黏贴对数据库进行拷贝
右击数据库名字---任务---分离----然后把那一行对号点完,确保数据的时效性、完整性,然后再去对应的路径下去复制ldf、mdf文件
然后附加
怎样附加?
先右键数据库,点击附加,在对应数据库的路径下找到mdf、ldf进行附加、只需要附加ldf会自动附加
对不同版本数据库进行附加出现的兼容性问题
右击数据库,点击生成脚本,然后选择版本 、
用户名的服务器角色sysadmin就是sa权限
要想下载数据库,就得先分离才能继续复制、移动
额,貌似2005没有这个功能
。。。
2008有
新的用户并且进行改密码
1.刚进去点击window身份验证登录(或者管理身份sa添加
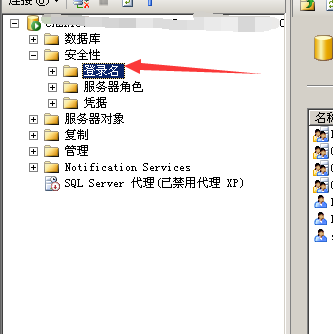
右键----添加用户名
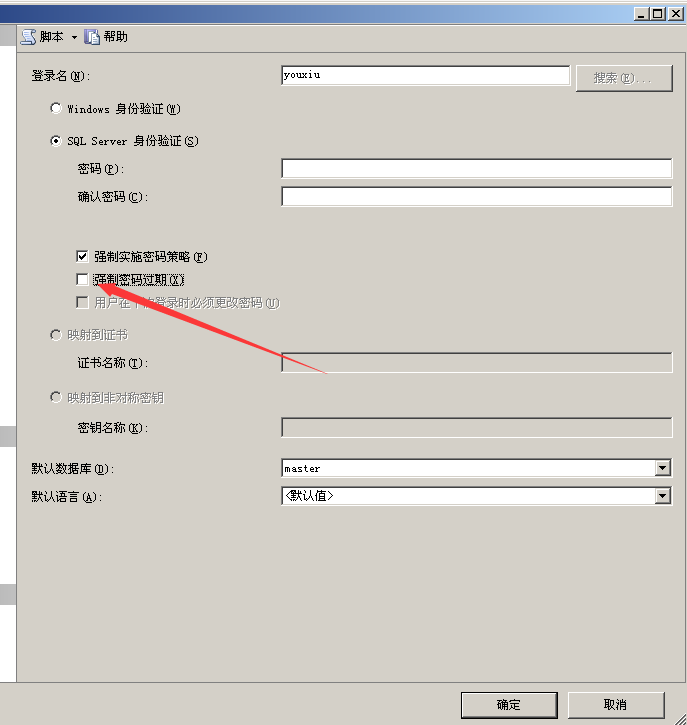
把强制密码过期去掉,这样不会报错
但是创建的用户没有权限
信息产生的重复叫冗余
表的相关数据
能够唯一标识一个事物的叫主键
关系型数据库:表示事物与事物之间的关系,也可以通过主键外键进行连接
外键:来自另外一个表的引用的索引(自己概括的)
字段:一个事物的某一个的特征
记录:字段的组合 表示的是一个具体的事物
表:记录的组合、表示的是同一类型事物的集合
表、字段、记录的关系
字段是事物的属性
记录是事物本身
表是事物的集合
一行叫做元组
列、属性:字段的另一种称谓
整体的叫做表
nvarchar是任意字符,字符长度可变化(无论是全角还是半角,每个字符都占用两个字节)
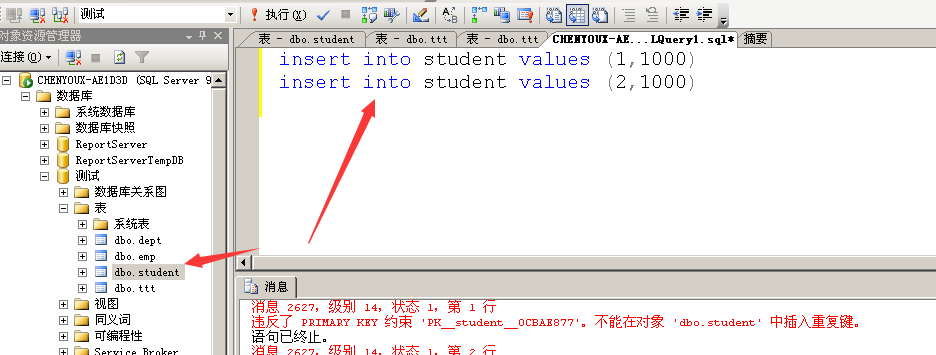
在sql中,图形化界面中,点击执行sql,会把重复的给自动去掉
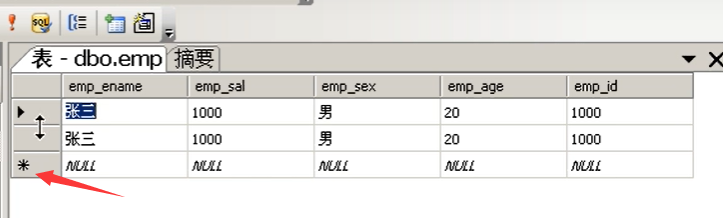
在输入相同数据后,点击再下星号,就可以避免重复而自动删掉
,但会使主键添加失败,需要对id进行更改数字来开启主键
主键、外键有点绕。。
---右键--关系---三个点点----设置主键、外键
外键来自另一个表的主键
还得确保数据类型的相同

create table 创建表 最后的一个字段不建议写逗号,因为Oracle命令逗号执行失败
关于命令
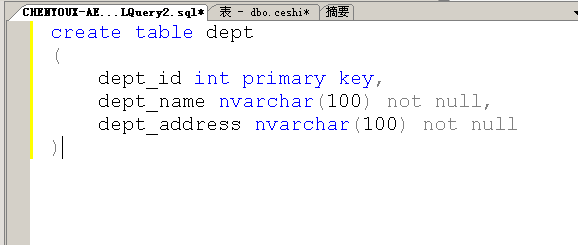
先创建表---再创建主键---类型要注意是nvarchar,不是nvchar,是否为空的确定,空就是null,非空就是not null
--是注释
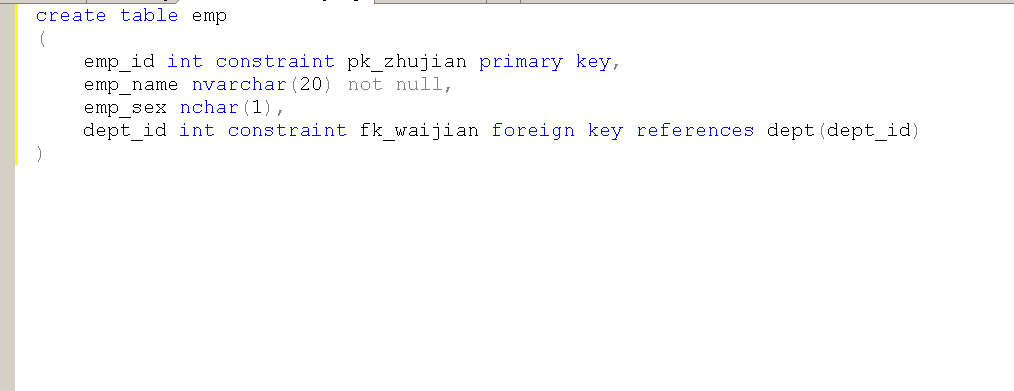
创建的第二个表
是emp
其实可以把constraint 名字 去掉,系统会自定义
不去掉就是自己自定义
先设置主键 primary key
然后定义属性
再设置外键 foreign key
外键要设置参考对象 references
ps:刷新建议点击添加查询的库刷新,不然出来的很慢,23333
约束是什么?
对一个表中的属性操作的限制叫做约束
分类:主键约束(不允许重复元素、避免数据的冗余)
外键约束(通过外键约束,从语法上保证了本事物所关联的其他事物一定是存在的)
事物事物之间通过外键来体现的
check约束:检查约束也就是条件约束
create table student
(
stu_id int primary key,
stu_sal int check (stu_sal>=1000 and stu_sal<=8000)
)
意思为:插入进去在表中为student的,主键值为1,工资为。。。
default:保证事物属性有一定的值
唯一约束:unique
唯一键可以为空
保证了事物属性的取值不允许重复
但是只能有一个为空
自动增长为identity
identity表示该字段的值会自动更新,不需要我们维护,通常情况下我们不可以直接给identity修饰的字符赋值,否则编译时会报错
m表示的是初始值,n表示的是每次自动增加的值
如果m和n的值都没有指定,默认为(1,1)
要么同时指定m和n的值,要么m和n都不指定,不能只写其中一个值,不然会出错
create table student1
(
id int primary key identity(200,10),
name nchar(8) not null,
sex nchar(1) not null,
)
insert student1 (name,sex) values ('张三','男');

drop table 表名 是删除表
在设置是否为空时,默认不写就是允许为空
在唯一约束下输入values,需要同时对values里加入唯一约束,不然语句错误,除非时指定的在表名后加插入属性
然后可以查看select * from 表名 看全部的输入内容
表和约束的区别:
数据库是通过表来解决事物的存储问题
数据库通过约束来解决事物取值的有效性和合法性的问题
建表的过程就是指事物属性及事物属性各种约束的过程
什么是关系:
表和表之间的联系
通过设置不同形式的外键来宝石表和表之间的关系
分类:一对一、一对多、多对多
说明分类:
假设A、B
一对一:
既可以把表A的主键充当表B的外键
也可以把表B的主键充当表A的外键
一对多:
把表A的主键充当B表的外键
或把A表的主键添加到B的表充当B表的外键
多对多:
一边的一个对另一边的多个,反过来也成立,就行
需要单独的再建一个表,来进行数据交互
多对多的一个例子:
折磨人。。
create table js
(
js_id int primary key,
js_name nvarchar(200)
)
create table bjsj
(
--只能组合是主键
bj_id int foreign key references bj(bj_id),
js_id int foreign key references js(js_id),
ke nvarchar(20),
constraint pk_bj_id_js_id primary key (bj_id,js_id,ke)
--主键约束,先定义名字,然后把bjid和jsid,ke充当主键,然后者三个都是主键,如果只设置前两个,就会出现错误在重复时。
)
关系图
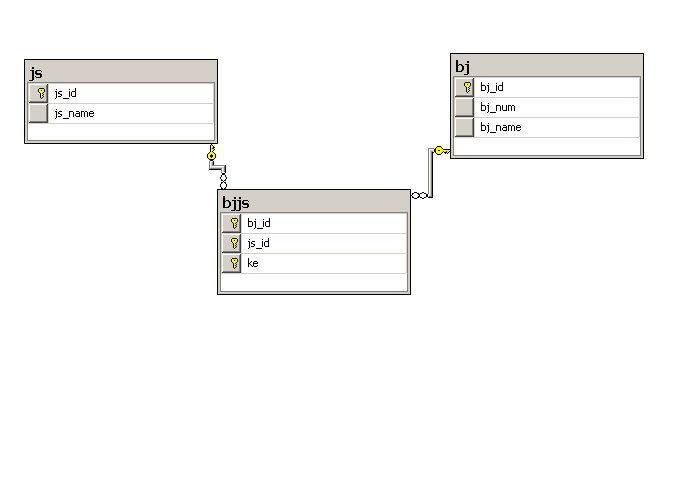
字段表示的是特征
记录表示的是这个事物
表表示的是同一个事物的集合
当设置关系时,被点击的是外键,然后再对
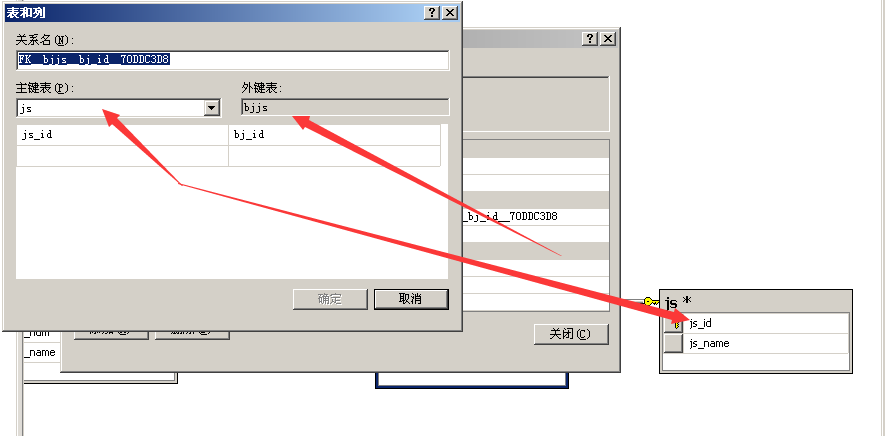
主键:能够唯一表示一个事物的一个字段或者多个字段的组合
含有主键的叫主键表
主键通常是整数,不建议用字符串当主键,除非是集群式服务
主键的值不允许被修改,除非本记录被删除
主键不要定义成id,而要定义成表名id或者表名_id,这是那个命名规则,方便看
要用代理主键,不要使用业务主键:
业务含义:就是有显示含义的
任何表都是不建议用业务主键
通常用在表中独立添加一个整形的编号来充当主键字段
外键:如果一个表的诺干个字段是来自另外诺干个表的主键或唯一键,则这个诺干字段就是外键
外键通常是来自另外表的主键而不是唯一键,因为唯一键可能会有null,即为空
外键不一定来自另外的表,也可能来自本表的主键
含有外键的表叫外键表,外键字段来自的那一张叫主键表
主键表和外键表的删除?
先删外键表,要删主键表,会报错,会导致外键表的数据引用失败
查询
计算列
select * from 表名
*代表所有的
from 表名 表示从表名中查询
相同的,可以把*用属性元素来表示
select bj_id,bj_name from bj;
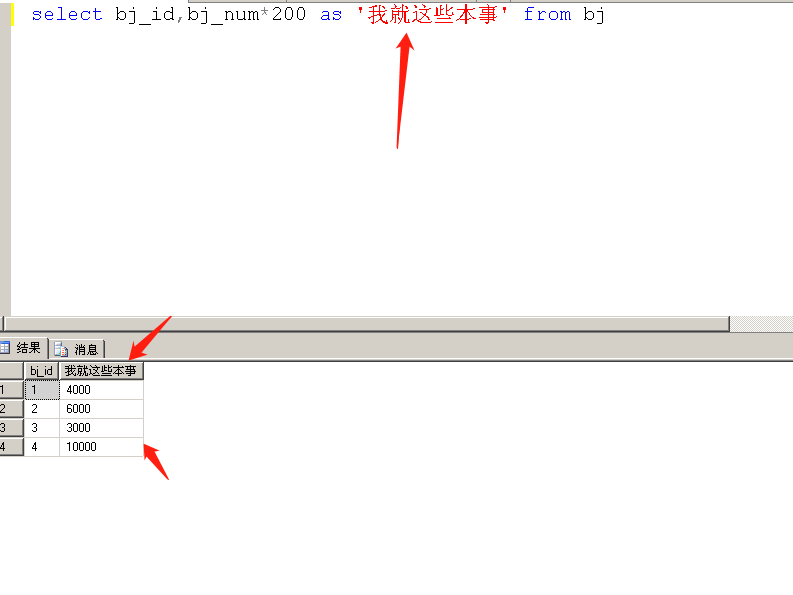
as可以省略,尽量使用给双引号名命名
select 数字 from 表名;
没啥用,就是看行数,我认为
oracle不允许单引号,兼容性问题,最好双引号
distinct
select distinct bj_id from bj;
主要是不同的,通过查询语句,把不同的给显示出来(也可以过滤掉重复的null)
当有两个,就是整体上过滤。。。那两个组合相同的过滤,只有两个都重复,才会过滤
也不能
select bj_num distinct bj_id from bj;
逻辑上有冲突
between
where是对条件的抉择
select * from bj where bj_num>=20 and bj_num <=50;
select * from bj where bj_num between 20 and 50;
--查询bj表中的大20和小50的行
select * from bj where bj_num<=20 or bj_num>=50;
select * from bj where bj_num not between 20 and 50;
--是小于20或者大于50的
in
属于若干个孤立的值
select * from bj where bj_id in (1,2,3)
--在1,2,3的表中的值
select * from bj where bj_id not in (1,2,3)
--不在1,2,3的值得确定
select * from bj where bj_id<>1 and bj_id<>2 and bj_id<>3
--数据库中有两种 !=或者<>
top
select top 2 * from bj;
--输出前两个
select top 15 percent * from bj;
--取多少百分比来,如果要是多一点,就近一位
select top 4 * from bj
where bj_id between 1 and 3
order by bj_id desc;
--在前四个并且选择在包含1到3的,按照降序来,如果不写,默认是升序
--desc是降序
null
null不能参与<> != = 的运算
可以参与is is not的
select * from where bj_id is not null;
0和null不一样,null空值,零表示一个确定的值
任何数据类型都允许null
create table a1(name nvarchar(200),id int,date datetime);
insert into a1 values(null,null,null);
select * from a1;

一个具体的值不能和一个没值的相加不能运算(null不能和任何数据运算,否则永远为空)
可以避免这个
select ename,sai*15+isnull(comm,0) from emp;
如果是null,即返回0,不然就返回comm的值
order by
select * from 表名 order by 属性;
默认升序
如果属性有两个,就是按照优先级,先按照前一个属性,再按照后一个属性
asc表示升序
desc表示降序
select * from emp order by name desc,sal;
这是先对name进行降序,然后对sal进行升序
select * from emp order by name,sal desc;
这是先对name进行升序,再对sal进行降序
如果不指定字段的排序标准,默认是asc升序
模糊查询
select * from bj where bj_num like '%0%';
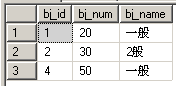
只有关键字0的
基本格式:
select 字段的集合 from 表名 where 某个字段的名字 like 匹配的条件
匹配的条件通常用含有通配符
通配符
%
A%首字母为A的
%A%有含有a的
%A伪字母含有A的
_
select * from emp where ename like '_A%';
ename只要第二个字母是A的就输出
[a-f]只能是a到f的任意单个字符
select * from emp where ename like '_[A-F]%';
把ename中的第二个字符是a到f的记录输出
[a,f]
a或者f
[^A-F]
把ename的第二个字符不是a到f的
条件必须用单引号裱起来
双引号圈起来表示字符串、别名
当有百分号时,需要用来
查看含有%的
select * from student where name like '%/%%';
类似的用还有_等
字符当作转义字符的标志
用m也可以
select * from student where name like '%m%%';
一般用
聚合函数
函数分类:
单行函数、多行函数
区别:
返回的值不一样
多行:多行返回一个值
聚合函数是撮合函数
聚合函数的分类:
max()
min()
avg()平均值
count() 求个数
例子:
select lower(name) from emp;
返回小写的表中的name属性的行数,lower()是单行函数
select max(name) from emp;
返回一行
select count(*) from emo;
返回emp表中所有记录的个数(重复的也被当作有效的记录)
可以用distinct来区分
select count(distinct gongzi) from emp;
返回是去掉重复的
ps:当有null的时候,count只会对除了null的有效,null不会被当作记录
例子2
select max(lar) "最高工资",min(lar) "最低工资", count(*) ”共计数“ from emp;
注意,要是有select的后面语句有单行和多行,内容是不匹配的,会报错
过滤掉空的、不同的
select count(distinct comm) from emp;
group by
切换表,可以用
use 表名;
select bj_name,avg(bj_num)"平均人数"
from bj
group by bj_name;
使用group by之后select中只能出现分组后的整体信息,不能出现组内的详细信息
使用两个group by的属性,有优先级
select deptno,job,avg(sal)
from emp group by deptno,job
order by deptno;
--这是先排序对deptno,再按照deptno,再按照job分类,再进行平均工资的计算
也可以更高级
select deptno,job,avg(sal)“平均工资”,count(*)"人数",sum(sal),“总工资”
,min(sal)"最低工资"
from emp group by deptno,job
order by deptno;
把表中的记录按照不同的字段分成不同的组
group a,b,c,d
先按照啊a分组,如果a相同,再b分组....
最后统计的是最小组的信息
having
对分组之后的信息进行过滤
select deptno,job,avg(sal) as “平均工资”
from emp group by deptno
order by deptno;
having avg(sal)>=2000
--对分组后的平均工资大于2000的进行筛选
也可以对deptno执行过滤
别名不能作为having的过滤参数
where与having
select deptno,avg(sal) "平局工资"
from emp
where ename not like '%A%' --对原始的数据过滤
group deptno --对分组后的进行过滤
having avg(sal)>2000;
--这个是工资大于2000,且名字包含A的例子
ps:where必须写在having的前面,顺序不可颠倒
having时通常会先使用group by(必须)
如果用group by ,但是用的having,会把所有的记录当成一组来过滤
having和where不能出现别名的使用,只能用原始的字段
单行函数是每一行都返回一个结果
多行函数是多行只返回一个结果
标准输入模板

先where再group再having再order
where不允许使用聚合函数
对于group by的使用,有两个,就是最后一个是作为其他的聚合函数的结果
into的使用
在select后和from前面,into 新表名把查询的结果放到一个表内
连接查询
将两个表或者两个以上的表以一定的连接条件连接起来,从中检索出满足条件的顺序
内连接
select ... from A,B
引用两个表叫做笛卡尔集
可以说是第一个表的所有行与第二个第一行结合,然后与第二行结合,依次....
产生结果:
行数是A,B的乘积
列数是A,B之和
select ...from A,B where ...
对产生的笛卡尔积进行过滤
select ... from A join B on ...
select "E".ename "员工名字","D".dname"部门名称"
from emp"E"
join dept "D"
on 1=1
join是连接条件
on是必须有的,不能省略,on是连接条件,即是判断
其实可以对别名不起,这件事为了方便记录
这里可以使用所谓的中文来
select”部门表”.deptno"部门编号”
from emp "员工表"
join dept"部门表”
on 1=1
但是通常是英文
on作为判断来筛选
select "E".ename“"员工姓名”,"D" .dname“部门名称”
from emp "E"
join dept "D"--join是连接
on "E".deptno = "D".deptno
就是在emp表中的ename和连接的dept中的dname下的数据中,把emp.deptno和dept.deptno相同的连接在一块的写出来
挡在过滤on上的一些指定内容,如
on "j".js_name='aa'
这些值的等于必须用单引号,与通配符一样
SQL92标准和SQL99标准的区别:
select ... from A,B where... sql92
select ... from A join B on ... sql99
结果一样,习惯用99,理解方面,自己观点
实例
工资大于4000
select emp.ename,dept.dname
from emp
join dept
on emp.deptno=dept.deptno
--因为有重复的,所以选择相等的来过滤重复的
where emp.sal>2000
工资大于2000的姓名和部门和工资等级
select *
from emp "E"
join dept "D"
on "E".deptno="D".deptno
join salgrade "S"
on "E".sal >= "S".losal and "E".sal <= "S".hisal
where "E".sal > 2000
where 还得必须放后面,不然会语法错误
select * from emp
join dept
on emp.deptno=dept.deptno
having dept.deptno=10
这是错误的,having是针对分组后的筛选
select * from emp
join dept
on 1=1
where dept.deptno > 10;
这样是对的
也可以这样
select * from emp
join dept
on dept.deptno > 10;
输出工资前三的员工的姓名、工资、工资等级
select top 3 ”E“.name,"E".sal,"E".grade,"D".dname
from emp "E"
join dept "D"
on emp.deptno=dept.deptno
join salgrade ”S“
on "E".sal between "S".losaland ”S“.hisal
order by ”E“.sal desc
要是说E的名字中不包含A就是
where ”E“.ename not like '%A%'
只能在rder by前添加
找出每个部门的编号 部门的所有的员工平均工资 平均工资等级
select "T".deptno,"T".avg_sal "部门平均工资","S".grade"工资等级"
from(
select deptno,avg(sal) "avg_sal"
from emp
group by deptno
)"T"
join salgrade "S"
on between "T".avg_sal between "S".losal and "S".hisal
求出emp表中的所有领导的姓名
select * from
where empno in (select mgr from emp)
求出emp表中的不是领导的姓名---还得考虑是否为空
select * from
where empno isnull (select mgr from emp,0)
求平均薪资最高的部门和平均工资
select top 1 deptno"部门编号",avg(sal)"平均工资
from emp
group by deptno
order by avg(sal) desc
在使用jon时,可以使用on不用where进行
select
*
from emp
join dept
on emp.deptno=dept.deptno and emp.sal>2000
on中写连接条件,也可以写过滤条件
等价于
select
*
from emp
join dept
on emp.deptno=dept.deptno
where emp.sal>2000
查询的顺序
select top ...
from A
join B
on...
join c
on...
where...
group by...
having...
order by...
--把工资大于1500的所有员工按部门分组,,把平均工资大于2000的前两个然后部门、等级
select “T”.*,dept.dname,"S".grade
from dept
join(
select top 2 deptno,avg(sal) "avg_sal"
from emp
where sal>1500
group by deptno
having avg(sal)>2000
order by avg(sal) desc--降序,这个select是对最高的前2个进行筛选,有平均工
--资、和员工
)“T”
on dept.deptno="T".deptno
join salgrade
on "T".avg(sal) between salgrade.losal and salgrade.hisal
外连接
不但返回满足连接条件的记录,而且会返回部分不满足的记录
左连接
不但返回满足连接条件的记录,而且会返回左表不满足的记录
右连接
不但返回满足连接条件的记录,而且会返回右表不满足的记录
默认的join是inner,不写也中
实际意义:
返回一个事物及其该事物的相关信息,如果该事物没有相关信息,则输出null

完全连接
join前加full的
就是把左右连接在一块了
内容包含:
两个表中匹配的所有记录
左表中那些在右表中找不到的记录,这些记录的右边全为null
右表中那些在左表中找不到的记录,这些记录的左边全为null
交叉连接
select *
emp from cross
join dept
等价笛卡尔集
select * from emp,dept
或者
select *
emp from
join dept
on 1=1
自连接
一张表自己和自己连接起来查询
自连接是一张表的左表与右表的第一个相对,然后第二个...
用聚合函数求最高薪资
select * from emp
where sal=(select max(sal) from emp)
--因为where不能使用聚合函数,所以得用括号圈起来的语句
select * from emp"E1",emp"E2"
连续两个对一个表的记录、
有两种方法
第一种:
select * from emp"E1",emp"E2"
第二种:
select * from emp"liwai"
join emp "liwai2"
on 1=1
不用聚合函数求薪资最高的员工信息
这个有点难,按照自己搜索学的总结一下
先创建相关表,和行
CREATE TABLE
T_Number (
num int
);
INSERT INTO T_Number(num) VALUES(5);
INSERT INTO T_Number(num) VALUES(23);
INSERT INTO T_Number(num) VALUES(-6);
INSERT INTO T_Number(num) VALUES(7);
如果想得到23最大,就是得到没有比23还大的数,我们可以先得到比23少的数
select lesser.num,greater.num
from t_number lesser,t_number greater
where lesser.num<greater.num
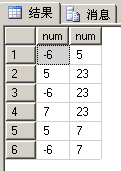
这样就会得到左面第一行的所有比23小的
然后对左表进行筛选
select num
from t_number
where num not in
(
select lesser.num
from t_number lesser,t_number greater
where lesser.num<greater.num
)
这样也对,但是如果有两个23,就会出现差错,所以要用distinct来进行过滤
select distinct num
from t_number
where num not in
(
select lesser.num
from t_number lesser,t_number greater
where lesser.num<greater.num
)

233333
联合
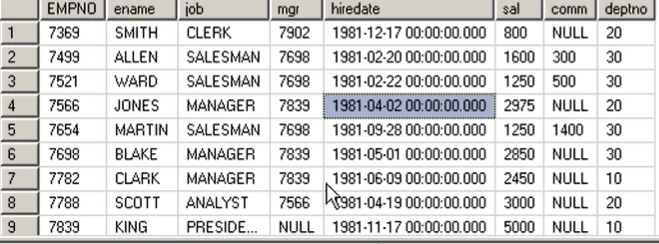
mgr表示上司
empno表示下属
这个表只是一部分
然后
只需要对上司的等于下属的标号就行,因为这样会把有上司和员工的给筛选出来
select e1.ename,e1.sal,e2.ename"上司的名字"
from emp e1
join emp e2
on e1.mgr=e2.empno--对有关系的进行选择
如果要是在mgr上有null
union
ename,sal,'最大老板'
from emp where mgr is null;
--可以看到把null变了
表和表之间的数据以纵向的方式连接在一起叫联合
联合的注意:
若干个select 子句输出的列数必须是相等的
而且
必须得是兼容的,与上一个select的
小结
主键必须有值,不能为空,可以用identity进行起始值的,或者自己设置
当进行了identity的设置,可以不用对其进行赋值,当某个记录删除时,还会按照删除的那个继续递增
删除一个表的行
delete from 表名 where 属性=xxxx
视图
简化查询
避免了代码的冗余,属性大量重复sql的语句
什么是视图?
从代码上看是一个select语句
试图逻辑上被当作一个虚拟表看待
视图格式
create view 视图的名字
as
select 的语句
--select前面不能加begin、后后能加end
视图的优点
增加数据的保密性
简化查询
视图的缺点
增加了数据库维护的成本
视图只是简化查询,不能加快查询
视图不是物理表、是虚拟表
不建议通过视图更新视图所依附的原始表的数据或结果
视图命名一般以v开头,v_xxx_xxxxxx
视图的select语句必须的为所指定的列取别名
事务
事物一系列操作要么成功、要么失败
事务主要保证数据的合理性和并发处理的能力
通俗说:
事务可以保证避免数据处于一种不合理的状态
利用事务可以实现多个用户对资源共享的同时访问
事务必须的保证多个用户对资源共享同时访问,数据库给用户的反应是合理的
事务和线程的关系
事务也是通过锁来解决很多问题
线程同步就是通过锁来解决的
脏读”可重复读
幻读“通过设置事务的优先级可避免
第三方插件要想完成预期功能,一般必须借助数据库的事务机制
事务的三种运行模式:
自动提交事务:
每条单独的语句都是一个事务。如果成功执行,则自动提交;如果错误,则自动回滚.
显式事务:
每个事务均以BEGIN TRANSACTION语句显式开始,以COMMIT或ROLLBACK语句显式结束。
隐性事务:
在前一个事务完成时新事务隐式启动,但每个事务仍以COMMOIT或ROLLBACK语句
事务的四个属性:原子性、一致性、隔离性、持久性
原子性:事务是一个完整的操作。事务的各步操作是不可分的(原子的)﹔要么都执行,要么都不执行。
一致性:当事务完成时,数据必须处于一致状态,要么处于开始状态要么处于结束状态不允许出现中间状态。
隔离性:指当前的事务与其他未完成的事务是隔离的。在不同的隔离级别下,事务的读取操作,可以得到的结果是不同的。
持久性:事务完成后,它对数据库的修改被永久保持,事务日志能够保持事务的永久性。
分页查询
 emp表
emp表
最高的前三个工资的所有信息
select top 3 *
from emp
order by sal desc;
工资从高到低,输出是前3到6个的
select top 3 *
from emp
where empno not in
(select top 3 empno order by sal desc)
order by sal desc;
工资从高到低,输出是前7到9个的
select top 3 *
from emp
where empno not in
(select top 6 empno order by sal desc)
order by sal desc;
一些小知识的自我总结:
业务主键和逻辑主键
业务主键是使用有业务意义的字段做主键,比如身份证号,银行账号等;
逻辑主键是使用没有任何业务意义的字段做主键。因为很难保证业务主键不会重复(身份证号重复)、不会变化(账号升位),因此推荐使用逻辑主键。
主键有两种定义方式:
1.
...
id int primary key not null,
...
2.
...
id int not null,
primary key (id)
...
关于nvarchar、nchar、char的
在看nvarchar和char的时候,发现还是用nvarchar比较好,在业务不算太大,对数据的要求不太多,nvarchar可以根据实际长度来存储数据长度,但是检索数据慢,同比char,在设置几个就是几个,不足的用空格代替,但这样会对内存的存储造成一定压力。
char是英文一个字节、汉字两个字节
ncarchar英文汉字都是两个字节
varchar是和nvarchar一样效率,但字符的占有跟char一样
nchar占用空间比char大。比如char格式下一个字母只占用一个字节,汉字占用两个,nchar所有字符都占用两个字节。
修改表结构
添加表
alter table 表名 add 属性 数据类型 是否为空;
删除表的某一属性
alter table 表名 drop 属性
数据操纵语言
除了int的insert插入不带单引号,其他的都带
INSERT INTO T_Person(Id,Name,Age) VALUES(1,'Jim',20);
更新语句
update T_Person set age=age+1 where name='tom' or age<25
删除表
delete from 表名
删除指定记录
insert into T_Person values(1,'陈优秀',24)
select * from T_Person;
delete from T_Person where age >20;
WHERE 中可以使用的逻辑运算符:or、and、not、<、>、=、>=、<=、!=、<>等.
还有一种模糊查询
select * from T_Employee where fname like '_arry';
--这是查前面一个的字符
select * from T_Employee where fname like '%n%';
--这是查询含有n的模糊匹配
in包含于
select * from T_Employee where fage in(21,23,25)
--在表中的21,23,25的出来
--下面的两个等价
...
where fage >= 23 and fage <=30
where fage between 23 and 30
聚合函数是对分组操作结果进行运算
sql server函数
abs()求绝对值
ceiling()最大上限
floor()最大下限
round()四舍五入
LEN():求字符串长度。LEN('abc')=3
LOWER()、UPPER():转小写、大写
LTRIM():去掉字符串左侧空格
RTRIM():去掉字符串右侧空格
GETDATE():取当前日期时间
DATEADD(datepart,number,date):计算增加以后的日期。参数 date 为待计算的日期,参数 datepart 为计量单位(YEAR,YY,MONTH,MM,DAY,DD 等)DATEADD(DAY,3,date)为计算日期 date 的 3 天后的日期,DATEADD(MONTH,-8,date)为计算日期 date 的 8 个月前的日期
DATEDIFF(datepart,startdate,enddate):计算两个日期之间的差额。datepart 为计量单位
DATEPART(datepart,date):返回一个日期的特定的部分
--查询员工入职年数.SELECT FName,FInDate,DATEDIFF(YEAR,FInDate,GETDATE())FROM T_Employee;
查询各入职年数的员工个数.
SELECT DATEDIFF(YEAR,FInDate,GETDATE()),COUNT(*)
FROM T_Employee
GROUP BY DATEDIFF(YEAR,FInDate,GETDATE());
空值处理
select isnull(fname,'佚名') 姓名 from empolyee
流控制函数
CASE expression
WHEN value1 THEN return_value1
WHEN value2 THEN return_value2
WHEN value3 THEN return_value3
ELSE default_return_value
END
在网上看一个例子,很实用
--有一张表T_Scroes,记录比赛成绩:
--Date Name Scroe
--2008-8-8 拜仁 胜
--2008-8-9 奇才 胜
--2008-8-8 湖人 胜
--2008-8-10 拜仁 负
--2008-8-8 拜仁 负
--2008-8-12 奇才 胜
--要求输出下面格式:
--Name 胜 负
--拜仁 1 2
--湖人 1 0
--奇才 2 0
-注意:在中文字符串前加 N,比如 N'胜'
emmmm
select name,
sum
(case score
when n'胜' then 1
else 0
end
)as 胜,
sum
(
case score
when n'负' then 1
else 0
end
)as 负
from t_score
group by name;
还有datetime也是一个数据类型,他的格式是xxxx-xx-xx xx:xx 也需要加引号说明的