转载 http://www.cnblogs.com/yuyd902/archive/2008/10/08/1306651.html
让我们看看如何对所选择的陈述实行更好的控制。SimpleSelector可以被继承,它的select方法可以被修改来实现更好的过滤:
// whose value ends with "Smith"
StmtIterator iter = model.listStatements(
new SimpleSelector(null, VCARD.FN, (RDFNode) null) {
public boolean selects(Statement s)
{return s.getString().endsWith("Smith");}
});
iter = model.list_statements(
Class.new(Java::SimpleSelector) {
def selects s
java.lang.String.new(s.getString).endsWith 'Smith'
end
}.new(nil, VCARD::FN, nil))
这个示例使用了一个简洁的Java技术,就是当创建此类的一个实例时重载一个内联的方法。(类似的,jruby中也有这种方法。)这里selects(…)方法会检查以保证全名以“Smith”做结尾。重要的是要注意对主体,谓语和客体的过滤是在调用selects(…)方法之前的执行的,所以额外的测试只会被应用于匹配的陈述。完整的代码可以在Tutorial8中找到,并会产生如下的输出:
The database contains vcards for:
John Smith
Becky Smith
你也许会认为下面的代码:
StmtIterator iter = model.listStatements(
new
SimpleSelector(null, null, (RDFNode) null) {
public boolean selects(Statement s) {
return (subject == null || s.getSubject().equals(subject))
&& (predicate == null || s.getPredicate().equals(predicate))
&& (object == null || s.getObject().equals(object))
}
}
});
等同于:
model.listStatements(new SimpleSelector(subject, predicate, object)
虽然在功能上它们可能是等同的,但是第一种形式会列举出模型中所有的陈述,然后再对它们进行逐一的测试。而第二种形式则允许执行时建立索引来提供性能。你可以在一个大模型中自己试试验证一下,但是现在先为自己倒一杯咖啡休息一下吧。
对模型的操作
Jena提供了把模型当作一个集合整体来操纵的三种操作方法。即三种常用的集合操作:并,交和差。
两个模型的并操作就是把表示两个模型的陈述集的并操作。这是RDF设计所支持的关键操作之一。它此操作允许把分离的数据源合并到一起。考虑下面两个模型:
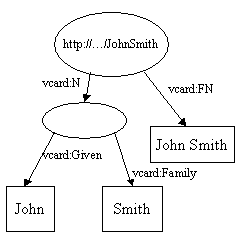
和
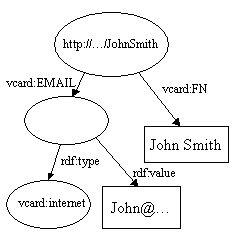
当它们被合并时,两个http://...JohnSmith会合并成一个,重复的vcard:FN箭头会被丢弃,此时就会产生:
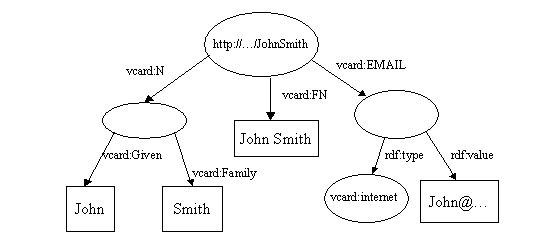
让我们看一下这个代码的功能(完整的代码在Tutorial9中),再看看会发生什么。
// read the RDF/XML files
model1.read(new InputStreamReader(in1), "");
model2.read(new InputStreamReader(in2), "");
// merge the Models
Model model = model1.union(model2);
// print the Model as RDF/XML
model.write(system.out, "RDF/XML-ABBREV");
require 'java'
module Java
include_package 'com.hp.hpl.jena.rdf.model'
include_package 'com.hp.hpl.jena.vocabulary'
include_package 'com.hp.hpl.jena.util'
include_package 'java.io'
InputFileName1 = 'vc-db-3.rdf'
InputFileName2 = 'vc-db-4.rdf'
model1 = Java::ModelFactory.createDefaultModel
model2 = Java::ModelFactory.createDefaultModel
in1 = Java::FileManager.get.open InputFileName1
if in1 == nil
raise ArgumentError, 'File: ' + InputFileName1 + ' not found'
end
in2 = Java::FileManager.get.open InputFileName2
if in2 == nil
raise ArgumentError, 'File: ' + InputFileName2 + ' not found'
end
model1.read in1, ''
model2.read in2, ''
model = model1.union model2
model.write java.lang.System.out, 'RDF/XML-ABBREV'
puts
end
petty writer会产生如下的输出:
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:vcard="http://www.w3.org/2001/vcard-rdf/3.0#">
<rdf:Description rdf:about="http://somewhere/JohnSmith/">
<vcard:EMAIL>
<vcard:internet>
<rdf:value>John@somewhere.com</rdf:value>
</vcard:internet>
</vcard:EMAIL>
<vcard:N rdf:parseType="Resource">
<vcard:Given>John</vcard:Given>
<vcard:Family>Smith</vcard:Family>
</vcard:N>
<vcard:FN>John Smith</vcard:FN>
</rdf:Description>
</rdf:RDF>
即便你不熟悉RDF/XML的语法细节,你仍然可以清楚的看见模型如同预期般被合并了。我们可以在类似的方式下运算模型的交操作和差操作。