用python实现文件自动下载,我搜索了一些href链接,保存在excel里面,然后希望python能自动开机启动下载任务,然后读取excel的href链接,并且,自动下载,下载好以后,自动在excel记录下下载完毕的结果,如果没有完成,下次继续下载。我希望电脑能在我不在家的时候,自己去下载文件,不需要我自己点开来。并且下载目录让python自己创建,我只要指定保存的总文件路径。现在先实现从excel里面读取href连接的功能,使用第三方库openpyxl
java/javascript/php/python都是能操作excel文件的,可以读取保存,但是javascript实现不了文件下载保存,其他都能实现,所以用哪个语言我觉得都是一样的。
1.1 Python官方库操作excel
Python官方库一般使用xlrd库来读取Excel文件,使用xlwt库来生成Excel文件,使用xlutils库复制和修改Excel文件,这三个库只支持到Excel2003。
1.2 第三方库openpyxl介绍
第三方库openpyxl(可读写excel表),专门处理Excel2007及以上版本产生的xlsx文件,xls和xlsx之间转换容易。 注意:如果文字编码是“gb2312” 读取后就会显示乱码,请先转成Unicode
1.安装 cmd 运行命令行
pip install openpyxl

从网上下载的图片有logo的话还可以用python批量清除logo
1.循环获取href地址
import openpyxl wb = openpyxl.load_workbook('file/allhref.xlsx') sheets = wb.sheetnames # print(sheets, type(sheets)) def getHref(ws): # print(ws['A']) for href in ws['B']: if href.value != 'href': { print(href.value) } for sheet in sheets: # 循环表 if(sheet == 'Sheet1'): getHref(wb[sheet]) # wb[sheet]

import openpyxl import urllib.request import time filePath = "F:/E/git/python-learn/writeExcel/download/" wb = openpyxl.load_workbook('file/allhref.xlsx') sheets = wb.sheetnames # print(sheets, type(sheets)) def getHref(ws): # print(ws['A']) A一竖列 #循环B数列 for href in ws['B']: if href.value != 'href': { dowload(href.value) } def dowload(url): response = urllib.request.urlopen(url) data = response.read() t = int(time.time() * 1000) name = filePath + '%d'%t+".jpg" //创建保存的文件名称 with open(name, 'wb') as code: code.write(data) for sheet in sheets: # 循环表 if(sheet == 'Sheet1'): getHref(wb[sheet]) # wb[sheet]
保存文件为时间戳,时间戳转字符串
t = int(time.time() * 1000) '%d'%t
创建文件夹 依赖os模块
os.mkdir(“test”)
图片下载已经实现了,python不能用{ },包住代码块,写的真难受。
import openpyxl import urllib.request import time import os filePath = "F:/download/" #换成自己的下载目录地址 wb = openpyxl.load_workbook('file/***.xlsx') #换成自己的exal目录 sheets = wb.sheetnames # print(sheets, type(sheets)) def getHref(ws): # print(ws['A']) A一竖列 #循环B数列 i = 0 for href in ws['B']: name = (ws['A'][i].value) i = i + 1 if href.value != 'href': dowload(href.value, name) def dowload(url, fileName): response = urllib.request.urlopen(url) data = response.read() t = int(time.time() * 1000) os.mkdir("download/"+fileName)//创建新的文件来保存特殊的文件 name = filePath + '%d'%t+".jpg" with open(name, 'wb') as code: code.write(data) for sheet in sheets: # 循环表 if(sheet == 'Sheet1'): getHref(wb[sheet]) # wb[sheet]
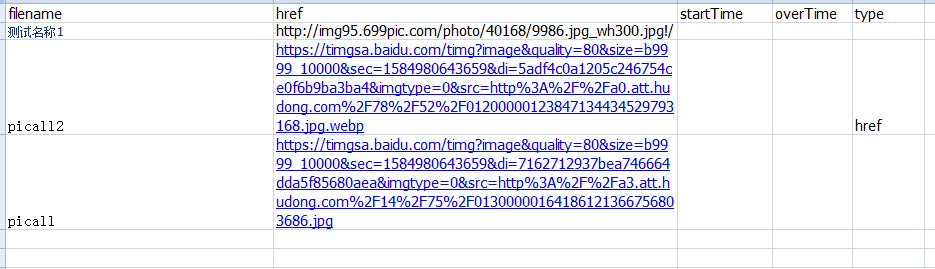
sheet1表1的目录
下面要支持对电影,pdf,迅雷的下载支持 和 对路径文件名称的自动匹配,保存成功对exal的保存,获取时间保存到overTime一行