一、unittst框架的作用
当我们写的用例越来越多时,我们就需要考虑用例编写的规范与组织,以便于后期的维护,而unittest正是这样一款工具
二、unittest是Python自带的标准库中的模块,其中包括:
1、TestCase类
2、TestSuite类
3、TestLoader类
4、TextTestRunner类
5、TextTestResult类
6、TestFixture类
解释下:
TestCase:
一个Testcase的实例就是一个测试用例,测试用例就是一个完整的测试流程,包括初始化setUp、运行run、测试后的还原tearDown
TestSuite:
对一个功能的测试往往需要多测试用例的,可以把多的测试用例集合在一起执行,这就是TestSuite的概念。常用addTest()方法将一个测试用例添加到测试套件中
TextTestRunner:
是用来执行测试用例的,其中的run(test)用来执行TestSuite/TestCase。测试的结果会保存在TextTestResult实例中
TestFixture:
测试准备前要做的工作和测试执行完后要做的工作.包括setUp()和tearDown()。通过覆盖TestCase的setUp和tearDown来实现。
TestLoader:
是用来搜索所有以test开头的测试用例,然后将其加入到testsuite中
图形化解释:
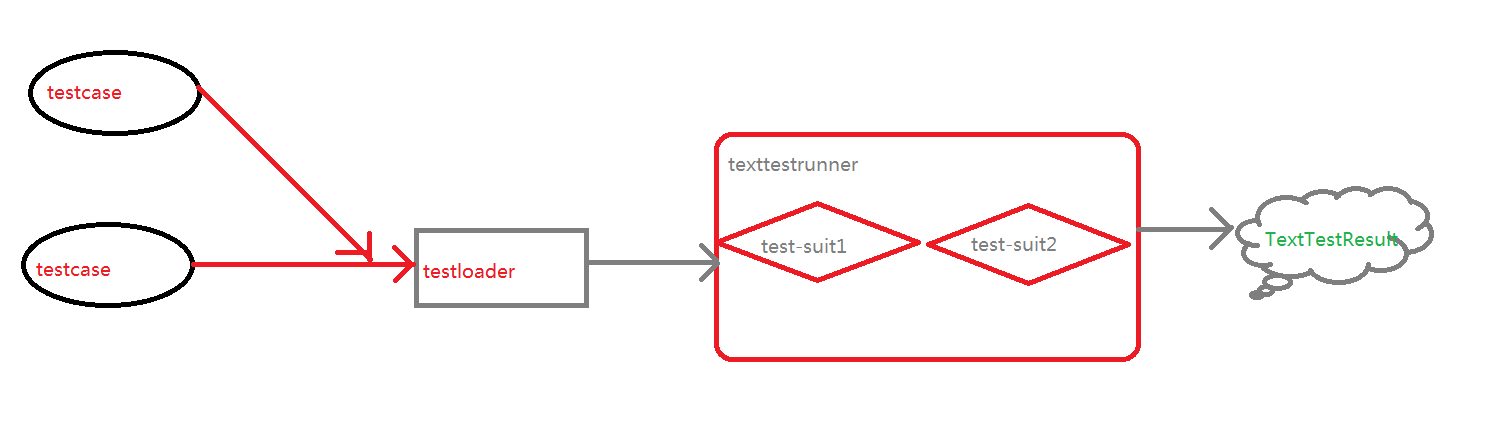
三、框架的组成
在写测试类以及测试用例时要规定一个命名习惯,一般测试类可以以Test开头,也可以以Test结尾。测试用例一般是以test开头。
eg:结构如下:
import unittest #导入unittest包
#创建测试类:从unittest.TestCase继承
classRomanNumeralConverterTest(unittest.TestCase):
def setUp(self): #初始化测试环境
def tearDown(self): #还原测试环境
def test_case(self):测试用例
四、百度案例
# -*- coding:utf-8 -*-
from selenium import webdriver
import unittest
import time
class x(unittest.TestCase):
#setUp:用于设置初始化环境的,该类中的方法执行时都会先执行setup中
#代码如:打开浏览器、变量赋值、连接数据库等工作
def setUp(self):
self.dr=webdriver.Chrome()
self.dr.maximize_window()
self.dr.implicitly_wait(20)#智能等待,sleep机械等待
self.dr.get('http://www.baidu.com')
#编写实际用例的地方
#搜索多测师
def test_caseA(self):
self.dr.find_element_by_id('kw').send_keys(u'多测师')
sleep(3)
#搜索达内
def test_case3(self):
self.dr.find_element_by_id('kw').send_keys(u'达内')
sleep(3)
#搜索北大青鸟
def test_case2(self):
self.dr.find_element_by_id('kw').send_keys(u'北大青鸟')
sleep(3)
#用例执行完,还有测试环境如:退出登录、断开数据库、关闭浏览器
def tearDown(self):
self.dr.quit()#关闭所有窗口
if __name__ == '__main__':
unittest.main()#
#unittest.main():使用它可以将一个单元测试模块变为可直接运行的测试脚本,main()方法使用TestLoader类来搜索所有包含在该模块中以“test”命名开头的测试方法,并自动执行
注意:pycharm工具默认执行方式为unittests方式
五、组织用例集
这里我们假设,脚本当中有多个TestCase如test_case1,test_case2…,那我们应该怎样去控制它们的执行顺序
#执行方案一:
if __name__ == '__main__':
unittest.main()#
注:这里它搜索所有以test开头的测试用例方法,根据ASCII码的顺序加载测试用例, 数字与字母的顺序为:0-9,A-Z,a-z
#执行方案二:
if __name__ == '__main__':
suite=unittest.TestSuite()#构造测试容器(先实例化测试套件)
suite.addTest(baidu('test'))#添加用例
suite.addTest(baidu('test_jd'))
#suite.addTests([foo('test_dcs'),foo('test_dn'),foo('test_bdqn')])
run=unittest.TextTestRunner()#获取运行方法
run.run(suite)
注:执行的顺序是用例的加载顺序,比如这里是先执行2后执行1。
#执行方案三:执行顺序和方案一相同(路径不要太深,复杂)
在方案2中,如果我们有成百上千个用例的话,一个一个add进去,是不太现实的,那么我们可以用defaultTestLoader来加载,该添加方法不过当前py文件下有多少个用例有多少个类,都可以执行
if __name__ == '__main__':
test_dir = './'
discover=unittest.defaultTestLoader.discover(test_dir,pattern='*d3.py')
runner = unittest.TextTestRunner()
runner.run(discover)
自动化用例编写注意点:
1、一个自动化脚本就是一个完整的场景:从开始---执行过程---结束(退出)
2、一个自动化脚本只验证一个功能点,不要试图把所有功能都写在一个用例中
3、编写自动化用例尽量是正常场景,避免异常场景(用名不填验证登录)
4、自动动化用例直接尽量保证独立性,不要造成一个用例与多个用例产出数据上或
业务上的关联,这会给后期带来用例维护上的不便
5、自动化用例的断言,只针对需要断言的地方进行断言(重要环节),没必要在每个
个环境进行断言验证
解释:
1、'./':表示当前路径
2、'd3.py':就是你新建的工程文件名字
3.discover方法里面有三个参数:
-case_dir:这个是待执行用例的目录。
-pattern:这个是匹配脚本名称的规则,test*.py意思是匹配test开 头的所有脚本。
-top_level_dir:这个是顶层目录的名称,一般默认等于None就行了。
4.discover加载到的用例是一个list集合,需要重新写入到一个list对象testcase里,这样就可以用unittest里面的TextTestRunner这里类的run方法去执行。