下面的内容需要慢慢看,因为,我的语言表达能力不是很好
首先说Set把,Set集合是一个无序且不允许重复的集合,而且查找效率也是快的可怕的。
但是,有些时候,我们必须要用储存多个相同的值时,Set也是可以通过特殊的方法来储存
相同的值的。
例如,我们创一个实体类,通过实体类来实现。
这样:
创建实体类:
public class Strings{
private String a;
public void A(String a){
this.a=a;
}
public String getA(){
return this.a;
}
@Override
public int hashCode(){
return a.hashCode();//可以先运行一遍,然后再把这个方法注释再运行一遍
} //对比一下效果
@Override
public boolean equals(Object obj){//上一个对比后,然后,又把这个方法注释运行一遍
return true; //对比一下效果
}
public String toString(){
return this.a;
}
}
然后,测试类:
import java.util.*;
public class Test{
public static void main(String args[]){
Set<String>mySet = new HashSet<String>();//我们可以把这里的String的类型改成StringBuffer或StringBuilder
//StringBuffer或StringBuilder自身没有hashCode方法,只能继承Object的默认方法,散列码是对象地址
String a="123"; //因为String a = "123",这样它的散列码由内容获得,结果一样,所以就只能存一个
String b="123"; //a、b、c它们的值都是相同的
String c="123";
mySet.add(a);
mySet.add(b);
mySet.add(c);
System.out.println(a==b);//查看a和b是不是相同的
System.out.println(mySet.size());//这里是查看集合里有几个元素
for(String s:mySet){ //如果上面用了StringBuffer或StringBuilder,那这里的String也要改成相应的StringBuilder或StringBuilder
System.out.println(s);//用遍历进行输出打印
}
System.out.println( "----------------------------" );
Set<Strings>mySet5 = new HashSet<Strings>();//Strings是上边创建的实体类,所以,这里用实体类来当做类型
Strings sa =new Strings();
Strings sb =new Strings();
Strings sc =new Strings();
sa.A("123");
sb.A("123");//给对象赋值
sc.A("123");
mySet5.add(sa);
mySet5.add(sb);
mySet5.add(sc);
System.out.println(sa==sb);//查看两个是否相等
System.out.println(mySet5.size());//打印元素个数
System.out.println(mySet5);//直接打印集合
for(Strings s:mySet5){
System.out.println(s);//遍历打印
}
System.out.println( "----------------------------" );
}
}
通过这样的方法,我们就可以达到用Set储存相同的值的效果了
现在来说StringBuffer,我上一次写过StringBuffer的好处,通过用String用加号来连接字符串和循环结合,对比得出,StringBuffer的效率确实
比用加号连接字符串效率快,但是,今天有个比StringBuffer更快的StringBuilder ,StringBuilder的效率比StringBuffer更快
例如代码:
import java.util.*; public class Test{ public static void main(String args[]){ long start =new Date().getTime(); StringBuilder sBuffer1 = new StringBuilder("NFIT"); System.out.println("这是StringBuilder"); for(int i=0;i<10000000;i++){ sBuffer1.append(i); } long end = new Date().getTime(); String str=sBuffer1.toString(); System.out.println(str.length()); System.out.println(end-start); StringBuffer sBuffer2 = new StringBuffer("NFIT"); System.out.println("这是StringBuffer"); for(int i=0;i<10000000;i++){ sBuffer2.append(i); } long end2 = new Date().getTime(); String str2=sBuffer2.toString(); System.out.println(str2.length()); System.out.println(end2-end); String strs="NFIT"; System.out.println("这是加号的"); for(int i=0;i<10000000;i++){ strs=strs+i; } long end3 = new Date().getTime(); System.out.println(strs.length()); System.out.println(end3-end2); } }
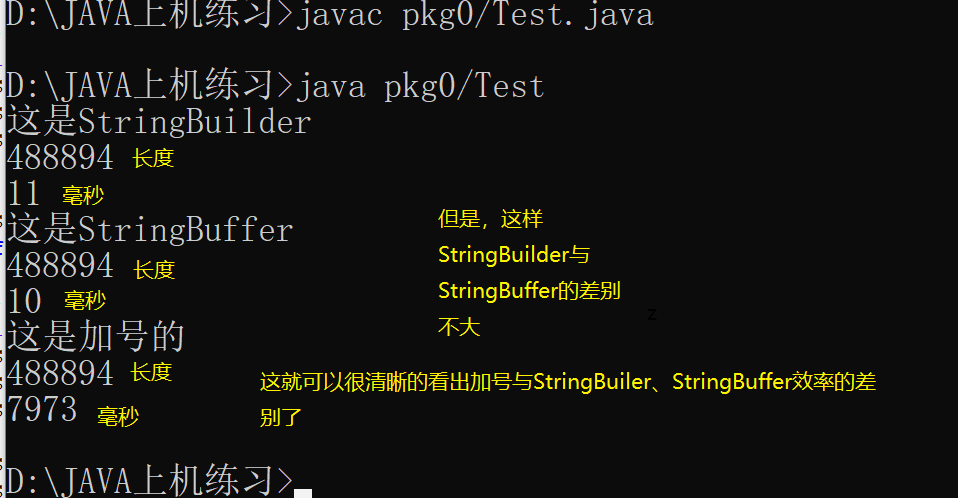
想要StringBuffer与StringBuilder的区别明显的话,那就要让循环次数乘10,或更多,这样效果会明显有点
所以,还是推荐用StringBuilder,这个效率还是很高的。
现在要说明一下Collection是不包含Map的,非常感谢昨天的那位小哥哥的提醒,要不然到现在还因为是包含的呢!!!
谢谢!!