之前已经写过两篇gene-based 关联分析研究,感兴趣翻往期推文:
基于GCTA的gene-based关联分析研究
使用VEGAS2(Versatile Gene-based Association Study)进行gene based的研究
今日再介绍第三款软件:MAGMA
跟前面的两款软件比起来,MAGMA 使用比较简单。
下面简要介绍基于 MAGMA 的 gene-based 关联分析研究。
1. 下载、安装 MAGMA
wget https://ctg.cncr.nl/software/MAGMA/prog/magma_v1.09.zip
unzip magma_v1.09.zip
2. 下载公共数据
# 下载基因位置文件NCBI37.3.gene.loc
wget https://ctg.cncr.nl/software/MAGMA/aux_files/NCBI37.3.zip
unzip NCBI37.3.zip
# 下载参考人群g1000_eur
wget https://ctg.cncr.nl/software/MAGMA/ref_data/g1000_eur.zip
unzip g1000_eur.zip
注意: 本推文使用的基因组版本是hg19(build 37)、参考人群选用欧洲人群,请各位根据自己研究的实际情况修改;
基因位置文件NCBI37.3.gene.loc如下所示:
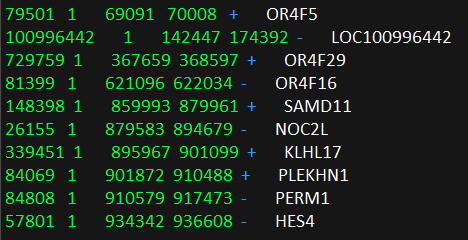
参考人群g1000_eur如下所示:

3. 准备输入文件
到这里,才是自己需要准备的文件,前面的文件全部是通过公共数据获得。
输入文件的格式同VEGAS2和GCTA,只需要 GWAS 结果的 P 值和 SNP id 即可
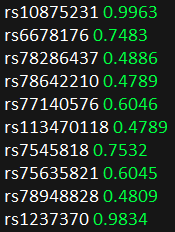
输入文件snpp包括两列,第一列是SNP的ID,第二列是SNP的P值;
输入文件snpp如下所示:
4. 开始分析
4.1 step1: 基因注释
输入命令:
magma --annotate --snp-loc g1000_eur.bim --gene-loc NCBI37.3.gene.loc --out g1000_eur
g1000_eur.bim和NCBI37.3.gene.loc文件通过前面的第二个步骤获得;
该步骤生成g1000_eur.genes.annot结果文件:
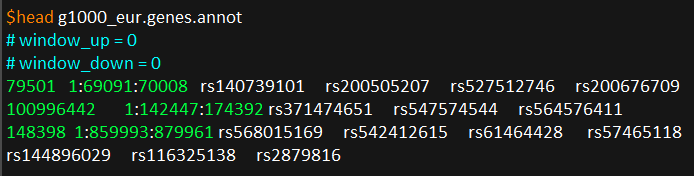
4.2 step2: gene-based 关联分析
输入命令:
magma --bfile g1000_eur --pval snpp N=401670 --gene-annot g1000_eur.genes.annot --out genebased
g1000_eur文件通过前面的第二个步骤获得;
snpp文件通过前面的第三个步骤获得;
g1000_eur.genes.annot文件通过 4.1 步骤获得;
N指的是研究的样本量;
执行以上命令后,生成两个文件:g1000_eur.genes.out和g1000_eur.genes.raw
g1000_eur.genes.out即为gene-based 关联分析结果:
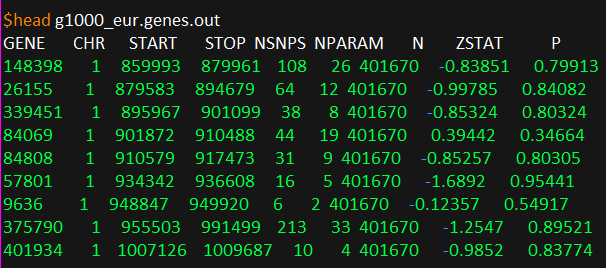
gene-based 关联分析结果的释义如下所示:
• GENE: the gene ID as specified in the annotation file
• CHR: the chromosome the gene is on
• START/STOP: the annotation boundaries of the gene on that chromosome (this includes any window around the gene applied during annotation)
• NSNPS: the number of SNPs annotated to that gene that were found in the data and were not excluded based on internal SNP QC
• NPARAM: the number of relevant parameters used in the model. For the SNP-wise models this is an approximate value; for the principal components regression (raw data default) this is set to the number of principal components retained after pruning; for the multimodels this is the mean NPARAM value of the component base models
• N: the sample size used when analysing that gene; can differ for allosomal chromosomes or when analysing SNP p-value input with variable sample size by SNP (due to missingness or differences in coverage in meta-analysis)
• ZSTAT: the Z-value for the gene, based on its (permutation) p-value; this is what is used as the measure of gene association in the gene-level analyses
• P: the gene p-value
生成的另外一个文件g1000_eur.genes.raw如下所示:
该文件可用于后续的 gene-set 分析。
gene-based 关联分析研究就介绍到这啦~
祝各位生活愉快~
