1.网络爬虫的基本概念
网络爬虫(又称网络蜘蛛,机器人),就是模拟客户端发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序。
只要浏览器能够做的事情,原则上,爬虫都能够做到。
2.网络爬虫的功能
 图2
图2
网络爬虫可以代替手工做很多事情,比如可以用于做搜索引擎,也可以爬取网站上面的图片,比如有些朋友将某些网站上的图片全部爬取下来,集中进行浏览,同时,网络爬虫也可以用于金融投资领域,比如可以自动爬取一些金融信息,并进行投资分析等。
有时,我们比较喜欢的新闻网站可能有几个,每次都要分别打开这些新闻网站进行浏览,比较麻烦。此时可以利用网络爬虫,将这多个新闻网站中的新闻信息爬取下来,集中进行阅读。
有时,我们在浏览网页上的信息的时候,会发现有很多广告。此时同样可以利用爬虫将对应网页上的信息爬取过来,这样就可以自动的过滤掉这些广告,方便对信息的阅读与使用。
有时,我们需要进行营销,那么如何找到目标客户以及目标客户的联系方式是一个关键问题。我们可以手动地在互联网中寻找,但是这样的效率会很低。此时,我们利用爬虫,可以设置对应的规则,自动地从互联网中采集目标用户的联系方式等数据,供我们进行营销使用。
有时,我们想对某个网站的用户信息进行分析,比如分析该网站的用户活跃度、发言数、热门文章等信息,如果我们不是网站管理员,手工统计将是一个非常庞大的工程。此时,可以利用爬虫轻松将这些数据采集到,以便进行进一步分析,而这一切爬取的操作,都是自动进行的,我们只需要编写好对应的爬虫,并设计好对应的规则即可。
除此之外,爬虫还可以实现很多强大的功能。总之,爬虫的出现,可以在一定程度上代替手工访问网页,从而,原先我们需要人工去访问互联网信息的操作,现在都可以用爬虫自动化实现,这样可以更高效率地利用好互联网中的有效信息。
3.安装第三方库
在进行爬取数据和解析数据前,需要在Python运行环境中下载安装第三方库requests。
在Windows系统中,打开cmd(命令提示符)界面,在该界面输入pip install requests,按回车键进行安装。(注意连接网络)如图3
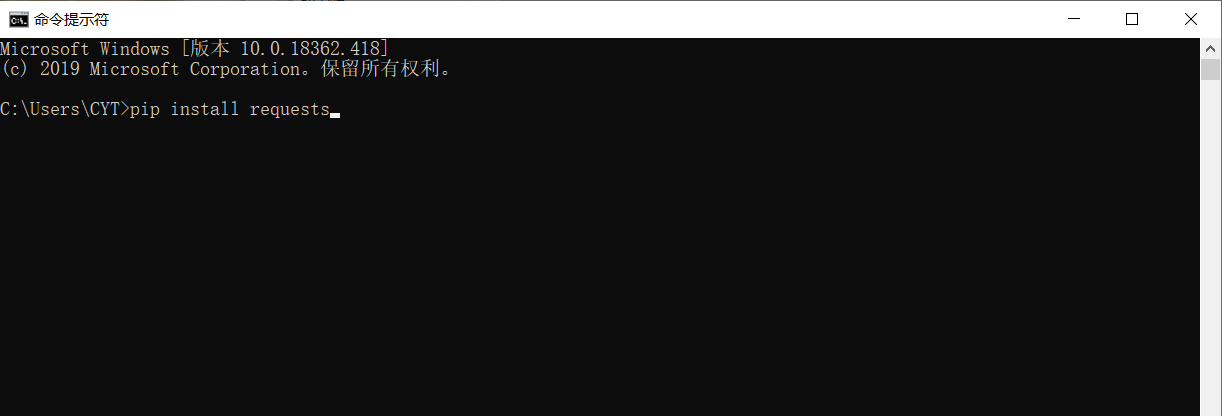
图3
安装完成,如图4
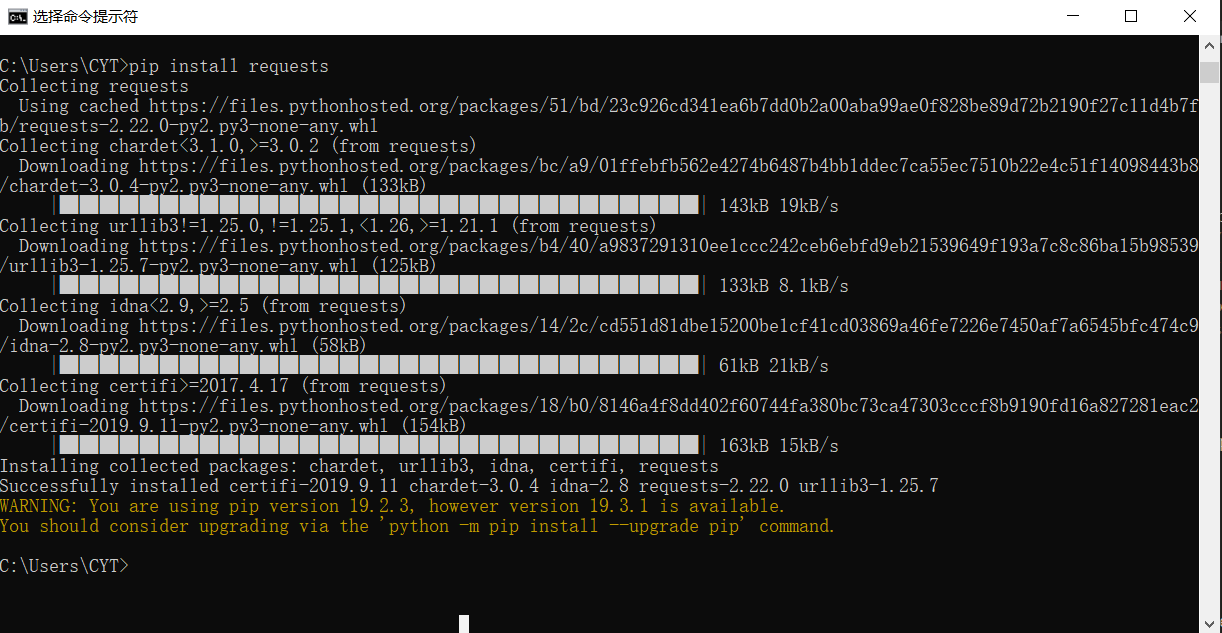
图4
4.爬取淘宝首页
1 # 请求库 2 import requests 3 # 用于解决爬取的数据格式化 4 import io 5 import sys 6 sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf-8') 7 # 爬取的网页链接 8 r= requests.get("https://www.taobao.com/") 9 # 类型 10 # print(type(r)) 11 print(r.status_code) 12 # 中文显示 13 # r.encoding='utf-8' 14 r.encoding=None 15 print(r.encoding) 16 print(r.text) 17 result = r.text
运行结果,如图5
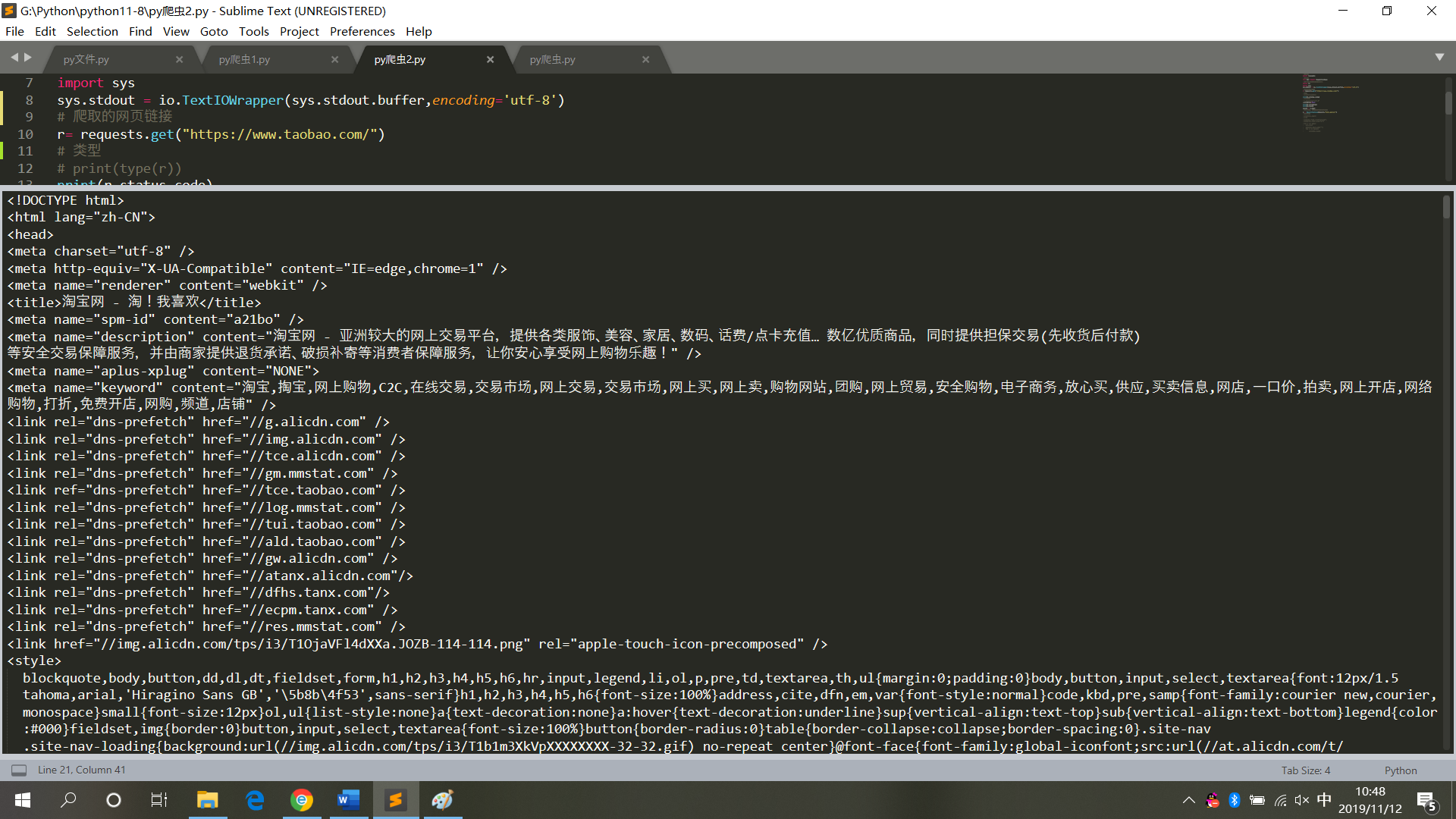
图5
5.爬取和解析淘宝网首页
1 # 请求库 2 import requests 3 # 解析库 4 from bs4 import BeautifulSoup 5 # 用于解决爬取的数据格式化 6 import io 7 import sys 8 sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf-8') 9 # 爬取的网页链接 10 r= requests.get("https://www.taobao.com/") 11 # 类型 12 # print(type(r)) 13 print(r.status_code) 14 # 中文显示 15 # r.encoding='utf-8' 16 r.encoding=None 17 print(r.encoding) 18 print(r.text) 19 result = r.text 20 # 再次封装,获取具体标签内的内容 21 bs = BeautifulSoup(result,'html.parser') 22 # 具体标签 23 print("解析后的数据") 24 print(bs.span) 25 a={} 26 # 获取已爬取内容中的script标签内容 27 data=bs.find_all('script') 28 # 获取已爬取内容中的td标签内容 29 data1=bs.find_all('td') 30 # 循环打印输出 31 for i in data: 32 a=i.text 33 print(i.text,end='') 34 for j in data1: 35 print(j.text)
运行结果,如图6
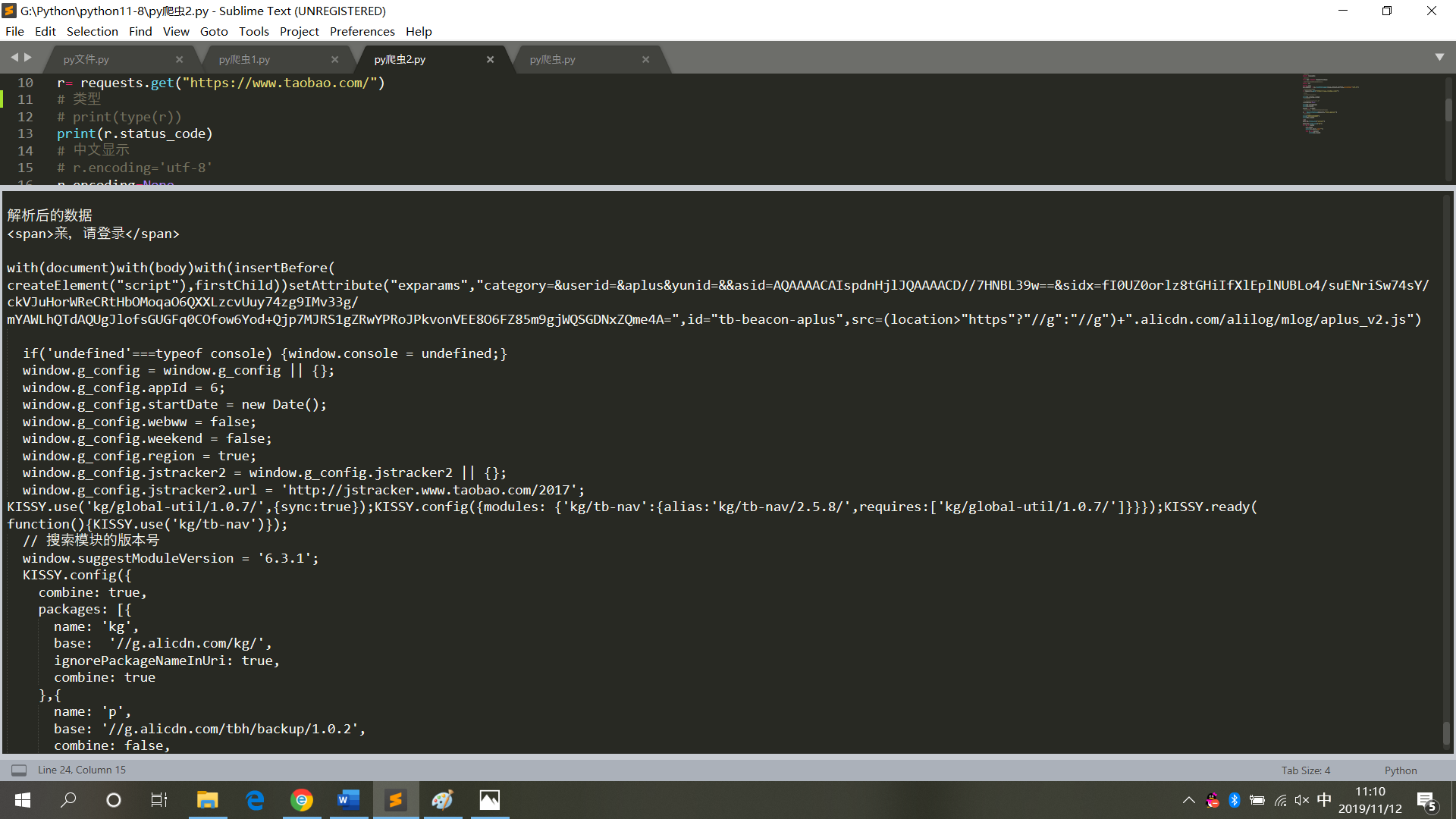
图6
7.小结
在对网页代码进行爬取操作时,不能频繁操作,更不要将其设置成死循环模式(每一次爬取则为对网页的访问,频繁操作会导致系统崩溃,会追究其法律责任)。
所以在获取网页数据后,将其保存为本地文本模式,再对其进行解析(不再需要访问网页)。