从官网可以知道的是 MLib是针对RDD数据集的,而ML是针对Dataframe格式的。 ML是对MLib的高级封装,目前来说,MLib已经不再进行功能更新了,好像都不更新了!具体去官网了解。
由于官网推荐的是学习和使用 spark dataframe,而且,现实生活中很多数据格式、python库、其它编程语言类库都是偏向于将数据解析成二维表的形式的,所以,我打算学习ML库。虽然MLib比较稳定、bug少、比较细,但是感觉rdd比较复杂,因为我习惯了pandas的二维表操作。ML是MLib的高级封装。
说了那么多,其实是因为复习考试无聊了,想写写文章!不,是想搬搬文章,这是一篇我之前翻译之后写在Jupyter notebook 里面的文章。
Spark中的高级分析工具,包括
- 数据预处理
- 监督学习
- 无监督学习
- 推荐系统
- 图计算
高级分析是指各种旨在解决核心问题的技术,这些核心问题是基于数据得出见解并做出预测或推荐。机器学习的最佳本体是基于您希望执行的任务构建的。最常见的任务包括:
- 监督学习–包括分类和回归;目标是根据不同的特征预测每个数据点的标签。
- 无监督学习–无监督学习,包括聚类、异常检测和主题建模,目标是发现数据中的结构
- 推荐系统–比如基于用户行为向用户推荐产品的推荐引擎
- 图形分析任务,例如在社交网络中搜索模式
在高层次上,MLlib(或者ML)听起来可能与您可能听说过的许多其他机器学习包类似,比如用于Python的scikit-learn或用于执行类似任务的各种R包。那么,为什么要用MLlib呢?在一台机器上执行机器学习的工具有很多,虽然有几个很好的选项可供选择,但是这些单机工具在可训练的数据大小或处理时间方面都有限制。这意味着单机工具通常是ML的补充。当使用spark的机器学习库的时候,面对大数据集以及时间限制等方面将表现出惊人的优势。
有两个关键的用例需要利用Spark的扩展能力。首先,希望利用Spark进行预处理和特征生成,以减少从大量数据生成培训和测试集所需的时间。然后,可以利用单机学习库对这些给定的数据集进行训练。其次,当输入数据大小或模型大小变得太困难或不方便放在一台机器上时,使用Spark来做繁重的工作。Spark使分布式机器学习变得非常简单。
所有这些的一个重要警告是,虽然训练模型和数据准备很简单,但是仍然需要记住一些复杂性,特别是在部署一个经过训练的模型时。例如,Spark没有提供从模型提供低延迟预测的内置方法,因此我们可能希望将模型导出到另一个服务系统或自定义应用程序来实现这一点。MLlib(或者ML)通常被设计成允许检查和将模型导出到其他可能的工具。
在MLlib中有几种基本的“结构化”类型:转换器(transformers)、估计器(estimators)、评估器(evaluators)和管道(pipelines)。 所谓结构,意思是当你定义一个端到端机器学习管道时,你会考虑这些类型。它们将提供公共(通用)语言来定义什么属于管道的什么部分。下图说明了在Spark中开发机器学习模型时要遵循的总体工作流。
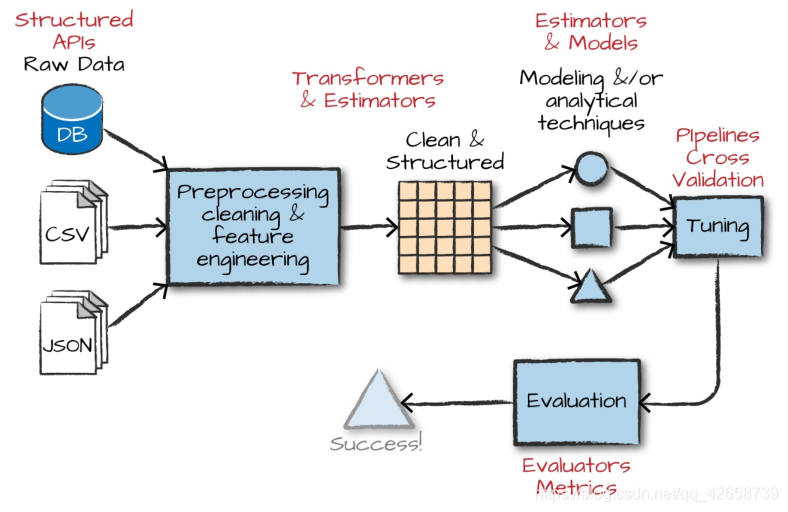
转换器(transformers) 是以某种方式转换原始数据的函数。这可能是创建一个新的交互变量(来自其他两个变量),将一个列规范化,或者简单地将一个整数更改为一个Double类型,以便输入到模型中。transformer的一个示例是将字符串分类变量转换为可以在MLlib中使用的数值。Transformers主要用于预处理和特征工程。转换器以一个数据dataframe作为输入,并生成一个新的数据dataframe作为输出,如下图所示。

估计器(estimators) 是两种东西中的一种。首先,估计器可以是一种用数据初始化的转换器。例如,要规范化数值数据,我们需要使用有关要规范化的列中的当前值的一些信息来初始化转换。这需要两次传递数据—初始传递生成初始化值,而第二次实际将生成的函数应用于数据。在Spark的术语中,允许用户从数据中训练模型的算法也称为估计器。
评估器(evaluators) 允许我们看到一个给定的模型如何根据我们指定的标准执行,就像一个接受者操作特征(ROC)曲线。在我们使用评估器从我们测试的模型中选择最佳模型之后,我们可以使用该模型进行预测。
从较高的层次上,我们可以逐个指定每个转换、估计和评估,但是将步骤指定为管道中的阶段 通常更容易。这个管道类似于scikit-learn的管道概念。
底层数据类型
除了用于构建管道的结构类型之外,可能还需要在MLlib中使用几个较低级别的数据类型(Vector是最常见的)。每当我们将一组特性传递给一个机器学习模型时,我们必须将其作为一个由双精度数组成的向量来完成。这个向量可以是稀疏的(其中大多数元素为零),也可以是密集的(其中有许多惟一的值)。向量以不同的方式创建。要创建密集向量,可以指定所有值的数组。为了创建一个稀疏向量,我们可以指定非零元素的总大小、索引和值。正如您可能已经猜到的,当大多数值为0时,稀疏是最好的格式,因为这是一种更压缩的表示。下面是一个如何手动创建矢量的例子:
[ 解释在注释中 ]
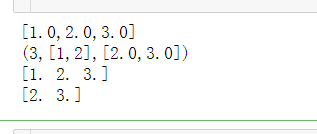
from pyspark.ml.linalg import Vectors #大部分操作与numpy的数组操作相同,只是其结构略微不一样罢了 # 创建矢量的方式 # 方式一:直接定义值组成向量,采取默认索引 #创建一个矢量(向量),当成数组矩阵对待即可,创建的形式: [1.0,2.0,3.0] denseVec = Vectors.dense(1.0, 2.0, 3.0) print(type(denseVec)) print(type(denseVec.toArray())) #转换成numpy的数组 print(type(denseVec.array)) #denseVec.array是直接将其转换为numpy数组,而且是以临时变量的形式 # 方式二:定义大小,索引、和值;创建的形式:(3,[1,2],[2.0,3.0]) size = 3 idx = [1, 2] # 非零元素在向量中的位置 values = [2.0, 3.0] sparseVec = Vectors.sparse(size, idx, values) print(type(sparseVec))
查看一下:
print(denseVec) print(sparseVec) print(denseVec.values) print(sparseVec.values)#取值
注意: 有些类似的数据类型指的是可以在数据流中使用的数据类型,而另一些数据类型只能在RDD中使用。RDD实现属于mllib包,而DataFrame实现属于ml。
更多关于Vectors的操纵方法: http://spark.apache.org/docs/2.3.3/api/python/search.html?q=Vectors
直达Vectors的操纵方法:http://spark.apache.org/docs/2.3.3/api/python/pyspark.ml.html?highlight=vectors#pyspark.ml.linalg.Vectors