一、搭建方法
在虚拟机上搭建集群的方法通常有两种
1.类似于真实的机器上部署,首先要进行密钥授权使各台机器之间能够免密码相互访问,然后在主节点上将各个软件配置好,分发各个从节点。
2.采用虚拟机克隆的方式,先进行软件的配置,然后将master的公钥授权自己,这样克隆出来的多个虚拟机之间都能够免密码登录
本文采用虚拟机克隆的方式创建Spark集群,其他的方式也是与这种方式类似
二、准备
物理机是win10操作系统,首先需要VMware软件,拟搭建具有三个节点的Spark集群,三台主机名名别是master, slave1, slave2
所需要使用的软件及版本
- Ubuntu 14.04
- jdk-8u221 (强烈建议不要使用最新版jdk, 使用jdk8)
- Scala 2.13.1
- Hadoop 3.2.1
- spark-2.4.4-bin-hadoop2.7.tgz
三、系统环境配置
这部分也是准备工作,包括
1.新建名为hadoop的用户,并创建密码,添加管理员权限
2.密钥授权,可以让集群的所有节点相互免密访问
3.修改主机名
4.主机名映射为IP,因为在软件的配置过程当中,通常会使用主机名,而不是直接使用IP,所以采用主机名和IP绑定的方式能够更方便的进行修改以适应各种环境。
操作步骤
1.新建用户,命令如下:
sudo useradd -m hadoop -s /bin/bash
sudo passwd hadoop
sudo adduser hadoop sudo
完成之后,需要注销当前用户,使用hadoop用户登录
2.密钥授权,首先要安装openssh-server,然后生成公钥,将公钥添加进授权认证文件
sudo apt-get install openssh-server
cd ~/.ssh/
ssh-keygen -t rsa
cat id_rsa.pub >> authorized_keys
3.修改主机名
sudo vim /etc/hostname
将主机名修改为master,之后克隆的主机名分别改为slave1,slave2
4.主机名与ip绑定,当然这一步在最后做,因为现在还没有克隆虚拟机,只有一台master机器。
首先通过ifconfig命令查看当前IP,然后编辑hosts文件
sudo vim /etc/hosts
我添加的内容如下
# Spark group
192.168.40.128 master
192.168.40.129 slave1
192.168.40.130 slave2
四、软件安装与配置
a. 软件下载安装
Java下载安装
在 https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html 中下载JDK8,下载完解压到/home/hadoop/Spark目录下并重命名,这个目录就作为整个Spark集群的工作空间
命令如下:
tar -zxf ~/Downloads/jdk-8u221-linux-x64.tar.gz -C ~/Spark
cd ~/Spark
mv jdk1.8.0_221 JDK
然后配置环境变量,命令为sudo vim /etc/profile,添加内容如下
export WORK_SPACE=/home/hadoop/Spark/
export JAVA_HOME=$WORK_SPACE/JDK/
export JRE_HOME=$WORK_SPACE/JDK/jre
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib
Scala, Hadoop, Spark下载安装的方式相同,完成之后结果如下
hadoop@master:~/Downloads$ ls ~/Spark
hadoop JDK scala spark
/etc/profile的内容如下
export WORK_SPACE=/home/hadoop/Spark/
export JAVA_HOME=$WORK_SPACE/JDK/
export JRE_HOME=$WORK_SPACE/JDK/jre
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib
export SCALA_HOME=$WORK_SPACE/scala
export PATH=$PATH:$SCALA_HOME/bin
export SPARK_HOME=/home/hadoop/Spark/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
配置完之后可以通过java -version命令和 scala -version命令验证是否配置正确。
b. Hadoop配置
这部分配置需要配置7个文件,在 home/hadoop/Spark/hadoop/etc/hadoop/ 目录下,分别是
hadoop-env.sh //BASH脚本,配置需要的环境变量,以运行Hadoop,这里配置Java路径
yarn-env.sh //BASH脚本,配置需要的环境变量,以运行YARN,这里配置Java路径
workers //配置从节点 可以是主机名或者IP地址 这个文件在Hadoop旧版本文件名可能为slaves,新版本改为了workers
core-site.xml //Hadoop Core的配置项,例如HDFS、MapReduce和YARN常用的I/O设置等
hdfs-site.xml //Hadoop守护进程的配置项,包括namenode、辅助namenode和datanode等
maprd-site.xml //MapReduce守护进程的配置项,包括作业历史服务器
yarn-site.xml //YARN守护进程的配置项,包括资源管理器、web应用代理服务器和节点管理器
详细配置如下
1.hadoop-env.sh
export JAVA_HOME=/home/hadoop/Spark/JDK
2.yatn-env.sh
export JAVA_HOME=/home/hadoop/Spark/JDK
3.workers
master
slave1
slave2
4.core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<!-- HDFS的名称节点的地址 主机是NameNode的主机名称或IP地址,端口是NameNode监听RPC的端口,如果没有指定,默认是8020 -->
<value>hdfs://master:9000/</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<!-- 临时目录 -->
<value>file:/home/hadoop/Spark/hadoop/tmp</value>
</property>
</configuration>
5.hdfs-site.xml
首先要新建name和data目录,命令为
$cd ~/Spark/hadoop
$mkdir dfs
$mkdir dfs/name
$mkdir dfs/data
然后配置xml文件
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<!-- 第二名称节点地址 -->
<value>master:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<!-- NameNode存储永久性的元数据的目录列表 -->
<value>file:/home/hadoop/Spark/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<!-- data存储永久性的元数据block块的目录列表 -->
<value>file:/home/hadoop/Spark/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<!-- 总结点数量 -->
<value>3</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<!-- 开启hdfs的web访问接口。默认端口是50070-->
<value>true</value>
</property>
</configuration>
6.maprd-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<!-- 支持MapReduce运行的框架的名称 -->
<value>yarn</value>
</property>
</configuration>
7.yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<!-- 节点管理器运行的附加服务列表 默认情况下,不指定附加服务-->默认情况下,不指定附加服务
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<!-- 运行资源管理器的PRC服务器的主机名和端口。-->
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<!--yarn总管理器调度程序的IPC通讯地址-->
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<!--yarn总管理器的IPC通讯地址-->
<value>master:8035</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<!--yarn总管理器的IPC管理地址-->
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<!--yarn总管理器的web http通讯地址-->
<value>master:8088</value>
</property>
</configuration>
c. Spark配置
Spark只需要配置两个文件分别是spark-env.sh和slaves,配置目录在安装目录的conf文件夹内,为~/Spark/spark/conf
1.spark-env.sh
export JAVA_HOME=/home/hadoop/Spark/JDK
export SCALA_HOME=/home/hadoop/Spark/scala
export HADOOP_HOME=/home/hadoop/Spark/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_HOME=/home/hadoop/Spark/spark
HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
#SPARK_LOCAL_IP为当前节点的IP,当克隆完虚拟机后需要在其他机器上做修改
SPARK_LOCAL_IP=master
YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
SPARK_DRIVER_MEMORY=512M
SPARK_MASTER_HOST=master
SPARK_MASTER_PORT=7077
SPARK_WORKER_CORES=1
SPARK_WORKER_MEMORY=512M
SPARK_WORKER_PORT=7077
2.slaves
slave1
slave2
完成以上配置后,大部分工作已经完成,接下来只需要配置完Spark之后,就可以将这台虚拟机克隆出两个从节点,配置hosts文件,就可以启动了。
五、虚拟机克隆
将虚拟机克隆之后,还需要做件事
1.修改克隆出的节点的主机名分别为slave1,slave2,命令为sudo vim /etc/hostname
2.通过ifconfig查看每台机器的IP,将主机名和IP绑定,命令为sudo vim /etc/hosts
3.修改Spark配置文件spark-env.sh的SPARK_LOCAL_IP为当前机器的主机名
六、启动集群
以上步骤全部完成之后就可以启动集群了,依次启动HDFS,YARN,Spark
1.启动HDFS, 首先要格式化名称节点,命令为sbin/hdfs namenode -format,然后启动hdfs,启动命令为 ~/Spark/hadoop/sbin/start-dfs.sh,启动完成后,使用jps查看启动的进程
在master上应该看到4个进程, 过程如下
hadoop@master:~$ ~/Spark/hadoop/sbin/start-dfs.sh
Starting namenodes on [master]
Starting datanodes
Starting secondary namenodes [master]
hadoop@master:~$ jps
3858 SecondaryNameNode
3638 DataNode
4008 Jps
3484 NameNode
在从节点上
hadoop@slave1:~$ jps
3099 Jps
2991 DataNode
2.启动YARN框架,启动命令为~/Spark/hadoop/sbin/start-yarn.sh
在master上应该看到6个进程,过程如下
hadoop@master:~$ ~/Spark/hadoop/sbin/start-yarn.sh
Starting resourcemanager
Starting nodemanagers
hadoop@master:~$ jps
4145 ResourceManager
3858 SecondaryNameNode
4308 NodeManager
3638 DataNode
4651 Jps
3484 NameNode
在从节点上
hadoop@slave1:~$ jps
3191 NodeManager
3304 Jps
2991 DataNode
3.启动Spark集群,启动命令为~/Spark/spark/sbin/start-all.sh
在master上过程如下
hadoop@master:~$ ~/Spark/spark/sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /home/hadoop/Spark/spark/logs/spark-hadoop-org.apache.spark.deploy.master.Master-1-master.out
slave1: starting org.apache.spark.deploy.worker.Worker, logging to /home/hadoop/Spark/spark/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-slave1.out
slave2: starting org.apache.spark.deploy.worker.Worker, logging to /home/hadoop/Spark/spark/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-slave2.out
hadoop@master:~$ jps
4145 ResourceManager
3858 SecondaryNameNode
4308 NodeManager
3638 DataNode
3484 NameNode
4749 Jps
4685 Master
从节点进程如下
hadoop@slave1:~$ jps
3191 NodeManager
3417 Jps
3371 Worker
2991 DataNode
至此,Spark集群已经搭建完成。
七、踩坑经历
1.先说最大的坑,JDK版本问题
我最初是从oracle官网下载的最新的JDK,也是就JDK13,启动HDFS没有问题,但是在启动YARN时却发生了问题,如下图所示,启动脚本没有报错,但是resourcemanager和nodemanager并没有被启动。
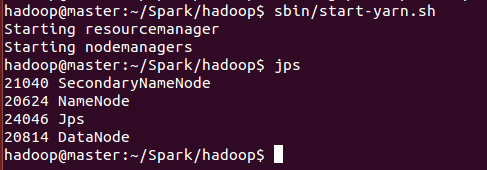
最开始没有报错,于是我期初把这个问题忽视了,继续启动Spark,当然是怎么也启动不了,发生如下错误
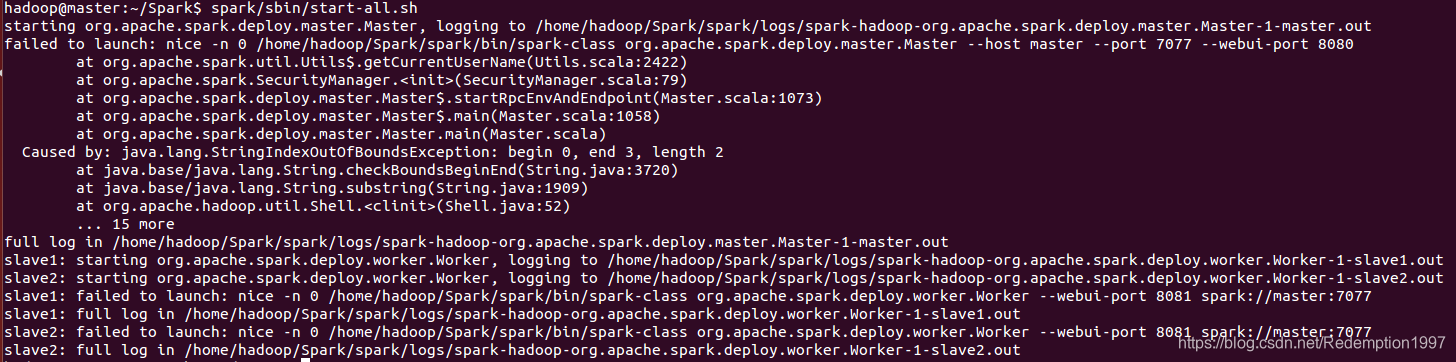
于是百度查找各种解决办法无果。因为YARN没有启动,而Spark是运行在YARN之上的,所以当然无法启动了
后来才想通是YARN的问题,于是查看了logs下的日志,发现了如下图的问题

无法调用javax.activation.DataSource, 然后继续百度,据说了JDK9及以上的版本禁用了javax,解决办法是卸载新版JDK,重新安装JDK8,之后,终于顺利启动了,所以,一定要使用JDK8。
2.启动DFS后,没有datanode
这个问题是由于在第一次格式化之后,启动并使用了hadoop,后来又重新执行了格式化命令,这时namenode的clusterID会重新生成,而datanode的clusterID 保持不变,所以会导致datanode和namenode的clusterID不一致的问题,解决问题的办法之一是更改dfs/data/current/VERSION中的ID与dfs/name/current/VERSION中的ID保持一致,当然还有一种解决办法是删除tmp、dfs/name、dfs/data三个目录,然后重新建这三个目录,然后格式化HDFS,再重新启动。(当然使用这种方法一定要确认数据是否备份,否则自己手贱删数据最后想剁手)
坑就写这些吧,还有一些小坑简单说一下,在配置xml文件时,
另外一个经验,出现错误不要第一时间百度,首先看日志文件,分析出错的具体原因,因为不同的原因可能导致同一个错误,所以百度出来的解决办法可能只适用别人,并不适合你遇到的问题。