介绍
主从延时在主从环境中是一个非常值得关注的问题,有时候我们可以通过show slave status命令查看Seconds_Behind_Master值来分析主从的延时情况;但是由于该值是来自binlog文件语句的完成时间,当一条SQL执行时间很长的时候那么该值可能就不准确了,那么有没有什么工具可以很准确的分析主从的延时情况呢? 在PT系列工具里面的pt-heartbeat工具很好的解决了这个问题。
原理
pt工具在主库上面创建一张测试表,以一秒的频率去更新这个的记录并把当前时间写入到字段中,通过分析主从同步过来的时间和当前时间做对比得出时间差。
方法
1.在主库上创建后台update进程
pt-heartbeat -uroot -proot -D chenmh --create-table --update --daemonize
-u:连接主库的用户
-p:连接主库的用户密码
-D:主库上存在的数据库,这个数据库随便指定,但是必须存在
--create-table:默认会在主库指定的数据库中创建一个“heartbeat”表

2.监控从库
pt-heartbeat -uroot -proot -D chenmh --table=heartbeat --master-server-id=10 --monitor -h 192.168.137.20 --interval=1
这里面的参数除了--master-server-id是主库的serverid,其它的都是指从库,特别注意--master-server-id一定不能写错否则结果就是错误的,记录了日志之后就可以对该值做监控预警了
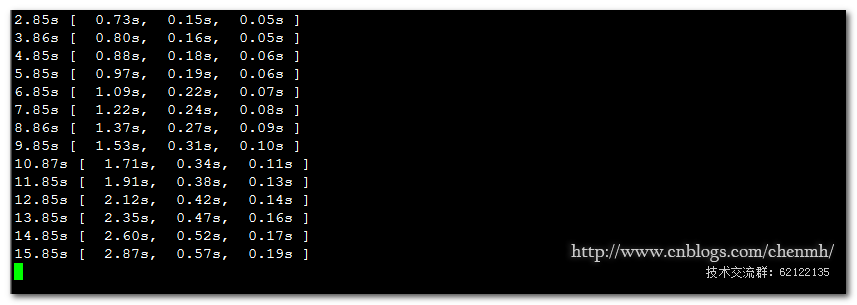
3.写入监控日志做预警分析
pt-heartbeat -uroot -proot -D chenmh --table=heartbeat --master-server-id=10 --monitor -h 192.168.137.20 --interval=1 --file=/tmp/heart.log
cat /tmp/heart.log |awk -F "s" '{print $1}'

4.停止后台更新操作
pt-heartbeat --stop
当你停止了后台更新进程会在/tmp目录下面产生一个pt-heartbeat-sentinel文件,下次再启动该后台进程之前必须先删除该文件,否则无法启动。
rm -rf /tmp/pt-heartbeat-sentinel
参数
Usage: pt-heartbeat [OPTIONS] [DSN] --update|--monitor|--check|--stop 其中--update, --moniter,--check,--stop都是单独使用的,并且--update, --monitor, and --check are mutually exclusive
--daemonize and --check are mutually exclusive.他们之间还是存在互斥。
Options: --ask-pass 使用密码进行mysql连接时给予提示
--charset=s -A 默认的字符选项 --check 执行一次从库的监控就结束 --check-read-only 如果是只读的服务器那么使用该选项会保持插入
--config=A 使用逗号分隔,如果指定了,那么该参数作为命令行的第一个选项
--create-table 如果表不存在创建表heartbeat
--daemonize 创建后台的更新shell
--database=s -D 指定连接的数据库
--dbi-driver=s Specify a driver for the connection; mysql and Pg are supported (default mysql) --defaults-file=s -F 通过提供的文件进行mysql连接
--file=s 输出最新的 --monitor监控信息到指定的文件
--frames=s 设置时间周期(default 1m,5m,15m) --help 显示帮助信息 --host=s -h 指定连接的host --[no]insert-heartbeat-row 在使用--tables的时候默认是插入一条记录到表heartbeat前提是表中不存在该记录行 --interval=f 指定更新和监控heartbeat表的频率默认是1S
--log=s 当使用daemonized进行后台更新操作时输出所有的信息到指定的该文件 --master-server-id=s 指定主的server-id
--monitor 监控从服务器的参数选项 --password=s -p 指定密码 --pid=s 创建pid文件 --port=i -P 指定连接时使用的端口
--print-master-server-id 打印输出master-server-id
--recurse=i Check slaves recursively to this depth in --check mode --recursion-method=a Preferred recursion method used to find slaves ( default processlist,hosts) --replace 使用replace替换--UPDATE操作
--run-time=m 指定监控的时长,单位有: s=seconds, m=minutes, h=hours, d=days; 如果比指定默认是以秒为单位一直监控下去
--sentinel=s Exit if this file exists (default /tmp/pt- heartbeat-sentinel) --set-vars=A Set the MySQL variables in this comma-separated list of variable=value pairs --skew=f 指定执行从库检查的延时时长默认是0.5
--socket=s -S 指定连接时使用的socket文件
--stop 停止后台更新进程并生成--sentinel指定的文件 --table=s 指定更新的表(默认是heartbeat) --update 更新主的heartbeat表,这个参数是后台进程必须的参数也可以用--replace替代 --user=s -u 指定用户名
--utc 忽略系统时间仅使用UTC --version 显示版本信息 --[no]version-check Check for the latest version of Percona Toolkit, MySQL, and other programs (default yes)
总结
可以通过这个监控的输出文件信息做一个邮件报警,有兴趣可以去写这样的一个shell
|
备注: 作者:pursuer.chen 博客:http://www.cnblogs.com/chenmh 本站点所有随笔都是原创,欢迎大家转载;但转载时必须注明文章来源,且在文章开头明显处给明链接。 《欢迎交流讨论》 |