介绍
本篇文章是对Innodb存储引擎的概念进行一个整体的概括,innodb存储引擎的概念是mysql数据库中最关键的几个概念之一,涉及的内容非常的广;由于个人的理解能力有限如果有不对的地方还见谅。

MySQL对应InnoDB版本
MySQL 5.1》InnoDB 1.0.X
MySQL 5.5》InnoDB 1.1.X
MySQL 5.6》InnoDB 1.2.X
后台线程
1.Master Thread
负责将缓冲池中的数据异步刷新到磁盘,保证数据的一致性;包括刷新脏页、合并插入缓冲、undo页的回收。
2.IO Thread
innodb存储引擎中大量使用了AIO(Async IO)来处理写IO请求来提高数据库的并发性能,共有四类IO线程,分别是:insert buffer thread、log thread、read thread、write thread。其中read thread和write thread分别有四个线程,可以通过innodb_read_io_threads和innodb_write_io_threads来配置。
SHOW VARIABLES LIKE 'innodb_%io_threads' 或者 SHOW ENGINE INNODB STATUS G;
3.Purge Thread线程
purge Thread线程用来回收事务提交后其被分配的undo页,默认是开启的,可以通过innodb_purge_threads=1配置多个Purge Thread线程。
show variables like 'innodb_purge_threads';
配置2个Purge thread,只能修改配置文件配置,不能在线修改
innodb_purge_threads=2
4.Page Cleaner Thread
用于多版本控制功能中回收delete和update操作产生的脏页,用来执行将脏页刷新到磁盘。
5.Binlog Dump线程
当配置了复制后,会在主服务器生成一个binlog Dump线程来读取二进制修改记录。
6.lock线程
用于锁控制和死锁检测
内存
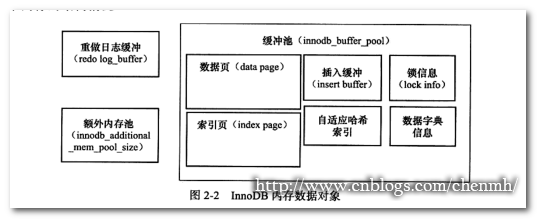
不要理解以为内存中就只有innodb buffer,还包括重做日志缓冲、额外的内存池(目前还不知道比如join buffer、order buffer、key buffer、table cache buffer等是在缓冲池内部还是独立于缓冲池在内存中)
1.缓存池
缓存的数据主要有数据页、索引页、重做日志页(undolog)、节点信息、系统数据、插入缓冲、自适应哈希索引、数据字典、锁信息等
查看缓冲池的大小,单位字节,转化为MB需要/1024/1024 show variables like 'innodb_buffer_pool_size';
默认innodb有8个缓冲池,可以通过配置innodb_buffer_pool_instances
查询
show engine innodb status G;
或者
SELECT * FROM information_schema.innodb_buffer_pool_status;
读操作:
数据是以页为存储单位,在缓冲池中缓存了很多数据页,当第一次读取时首先将页从磁盘读取到缓存池中,当下一次再去读相同的数据页时如果该也在缓存池中就直接从缓冲池中读取而不需要再去磁盘读,最理想的方式是将所有的磁盘数据都缓存到缓冲池中但是这得内存足够大才行。
修改操作
innodb存储引擎对数据的修改也是先修改缓冲池中的数据页(如果存在),然后根据一定的频率刷新到磁盘来修改数据文件,这涉及到checkpoint机制,
插入操作(insert buffer)
因为数据是按照聚集索引的顺序排列的,所有针对聚集索引的插入一般会非常快,而非聚集索引的插入就不一定是顺序的,这个时候需要离散的访问非聚集索引页,插入的性能往往会很差,有一种情况可能例外就是非聚集索引的时间字段,而时间往往是顺序的,这种情况会比较快,针对非聚集索引的这种情况就引入了插入缓冲。
innodb中引入了插入缓冲(insert buffer),insert buffer只针不唯一的非聚集索引,对于非聚集索引的插入和更新操作不是每次直接插入到索引文件中,而是先判断插入的非聚集索引页是否存在缓冲池中,如果存在则直接插入缓冲池的非聚集索引文件中,否则先放入到一个insert buffer对象当中,但是给人的感觉它已经插入到了索引文件中,但是实际并没有,然后再以一定的频率插入到索引文件当中,在这个过程中如果存在多个相同的索引页的插入会合并插入,大大的提高了非聚集索引的插入性能,
因为每次插入是先插入到缓冲池当中不去查找索引页来判断记录的唯一性,因为去做判断需要去离散查找,所以插入缓冲不针对唯一性的非聚集索引。
在密集写操作的情况下,插入缓冲会占用过多的缓冲池的内存,默认最大可以占到50%,源代码中的IBUF_POOL_SIZE_PER_MAX_SIZE=2,如果将其修改为3,则最大只能使用1/3的缓冲池的内存。
2.LRU List、Free List、Flush List
innodb缓冲池中的页默认大小为16KB,缓冲池通过LRU(Latest Recent Used 最新少使用)算法来进行管理,将最频繁的使用的页放在LRU列表的前端,而最近少使用的页放在尾端,当缓存池中的空间不足的时会先删除尾端的页来释放空间。LRU有一个midpoint位置,默认在LRU的37%的位置,左边表示old列表,右边表示new列表(热点数据),新插入缓冲池中的页先放在midpoint的位置,如果新插入的页一来就移动到new列表的话可能会导致new列表中的某些活动也被移除到old列表中,比如表扫描操作一次性可能需要访问很多的数据页而这些数据页可能以后很少被使用,新插入的页何时才会被被放入new列表中呢,为了解决这个问题innodb引入了innodb_old_blocks_time参数,该参数用来控制新插入的数据页在mid位置多久后才被加入到new列表中。
查看midpoint的位置,如果觉得热点数据空间需要更多可以将该值设小 show variables like 'innodb_old_blocks_pct'
查询innodb_old_blocks_time值,单位毫秒,默认是1000毫秒即1秒
show variables like 'innodb_old_blocks_time'
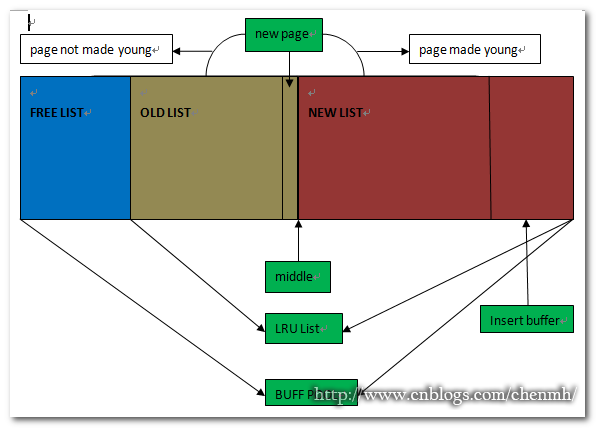
查看缓冲池中所有页的信息,包括空闲页,所有的数据页*16KB其实也就是缓冲池的总大小. select * from information_schema.INNODB_BUFFER_PAGE; 查看LUR列表的信息,包括new list和old list但是不包括free list,表中的字段记录了当前的数据页的信息,包括缓冲池ID,页的类型(数据页、索引页、undo log、other),表名,索引名,是否是old list的页,是否属于压缩页(可以将原本16K的页压缩为1K、2K、4K、8K),压缩页的大小,是否属于脏页。 select POOL_ID,LRU_POSITION,SPACE,PAGE_TYPE,FLUSH_TYPE,NEWEST_MODIFICATION,OLDEST_MODIFICATION,INDEX_NAME,DATA_SIZE,COMPRESSED_SIZE,COMPRESSED,IS_OLD from information_schema.INNODB_BUFFER_PAGE_LRU;
OLDEST_MODIFICATION>0表示脏页的数量也就是(modified db pages)
IS_OLD='YES'代表OLD List页
COMPRESSED<>0代表压缩页
flush list:值的就是LRU中的脏页,flust list存在于New List中,即OLDEST_MODIFICATION>0(modified db pages)
3.日志缓冲(log buffer):对应innodb日志文件
查看重做日志缓冲 show variables like 'innodb_log_buffer_size%';
InnoDB存储引擎首先将重做日志信息先放入到重做日志缓冲中,然后按照一定的频率将其刷新到重做日志文件当中。默认缓冲大小是8M,8M基本可以满足需求,不需要配置太大的重做日志缓冲。
刷新机制:
1.Master Thread 每一秒将重做日志缓冲刷新到重做日志文件;
2.每个事务提交时会将重做日志缓冲刷新到重做日志文件;
3.当重做日志缓冲池剩余空间小于1/2时
注意:innodb_log_buffer_size的大小应该要比最大的事务大小要打,否则事务还未提交innodb_log_buffer_size就已经写满就需要进行刷新操作,会造成一个事务需要多次进行磁盘日志刷新操作,导致效率低。
4.额外的内存
平时我们的服务器MySQL进程所使用的内存会比配置的InnoDB缓冲池的内存要大,那是因为MySQL除了缓冲池中缓存的内存额外还需要一部分内存用来控制缓冲池内部的一些资源信息,比如LRU、锁资源、等待等。
CheckPoint机制
为了解决CPU和磁盘直接速度的问题采用了缓冲池,所以对数据的操作都是先在缓冲池中完成,缓冲池中的数据页往往比磁盘上的数据页要新,我们将在缓冲池中已经修改但是还未应用到磁盘的数据页叫“脏页”,数据页最终还是需要更新到磁盘中,中间会涉及到CheckPoint机制。
同时为了解决因为突然服务器停机导致缓冲池中还未来得及刷新到磁盘的脏页丢失的问题,加入了重做日志文件(重做日志文件默认是配置2个,默认名称是ib_logfile开头,重做日志文件默认大小是48M,两个重做日志文件采取循环写的方式),当事务提交时先写重做日志,当发生服务器停机后可以通过重做日志来完成恢复(服务器重启之后自己默认会恢复),所以得保证重做日志文件有剩余空间,默认机制是当重做日志文件空间达到75%-90%时就刷新一部分脏页到磁盘同时清空对应的重做日志空间。
每次刷新多少页到磁盘:
Sharp Checkpoint:数据库关闭时将所有脏页都刷新回磁盘,默认方式,参数:innodb_fast_shutdown=1
Fuzzy Checkpoint:刷新部分脏页,具体分为以下四种情况
1.Master Thread Checkpoint
Master Thread每隔几秒钟从缓冲池中将脏页刷新回磁盘
2.FLUSH_LRU_LIST CheckPoint
在5.6版本之后需要保证LRU默认存在1024个可用页,如果可用页不足1024页刷新部分脏页回磁盘,通过参数“innodb_lru_scan_dapth”配置。
3.Async/Sync Flush Checkpoint
指的是因为重做日志文件空间不足导致的同步或异步刷新脏页回磁盘,当重做日志空间已使用的空间达到75%-90%就触发异步刷新,如果超过90%就触发同步刷新,一般不会触发同步刷新操作,除非重做日志文件太小并且进行LOAD DATA的BULK INSERT操作。
4.Dirty Page too much
保证缓冲池中脏页的比例,当缓冲池中的脏页比例达到75%时就触发刷新脏页操作,通过参数“innodb_max_dirty_pages_pct”配置。
总结
innodb存储引擎的概念非常的多,随便一个知识点都不止一篇文章可以写下,所以本篇只是会整体做一个描述后面会针对每一个知识点进行更细的分析。
|
备注: 作者:pursuer.chen 博客:http://www.cnblogs.com/chenmh 本站点所有随笔都是原创,欢迎大家转载;但转载时必须注明文章来源,且在文章开头明显处给明链接。 《欢迎交流讨论》 |