之前我们创建索引,查询数据,都是使用的默认的分词器,分词效果不太理想,会把text的字段分成一个一个汉字,然后搜索的时候也会把搜索的句子进行分词,所以这里就需要更加智能的分词器IK分词器了。
1. ik分词器的下载和安装,测试
第一: 下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases ,这里你需要根据你的Es的版本来下载对应版本的IK,这里我使用的是6.3.2的ES,所以就下载ik-6.3.2.zip的文件。
第二: 解压-->将文件复制到 es的安装目录/plugin/ik下面即可,完成之后效果如下:
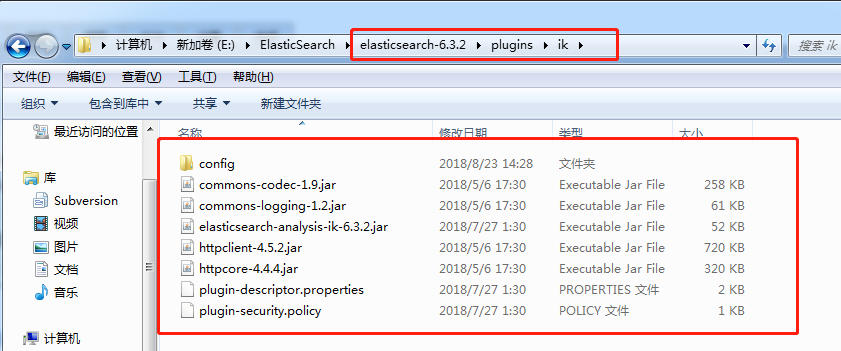
到这里已经完成了,不需要去elasticSearch的 elasticsearch.yml 文件去配置。
第三:重启ElasticSearch
第四:测试效果
未使用ik分词器的时候测试分词效果:
POST book/_analyze { "text": "我是中国人" } //结果是: { "tokens": [ { "token": "我", "start_offset": 0, "end_offset": 1, "type": "<IDEOGRAPHIC>", "position": 0 }, { "token": "是", "start_offset": 1, "end_offset": 2, "type": "<IDEOGRAPHIC>", "position": 1 }, { "token": "中", "start_offset": 2, "end_offset": 3, "type": "<IDEOGRAPHIC>", "position": 2 }, { "token": "国", "start_offset": 3, "end_offset": 4, "type": "<IDEOGRAPHIC>", "position": 3 }, { "token": "人", "start_offset": 4, "end_offset": 5, "type": "<IDEOGRAPHIC>", "position": 4 } ] }
使用IK分词器之后,结果如下:
POST book_v6/_analyze { "analyzer": "ik_max_word", "text": "我是中国人" } //结果如下: { "tokens": [ { "token": "我", "start_offset": 0, "end_offset": 1, "type": "CN_CHAR", "position": 0 }, { "token": "是", "start_offset": 1, "end_offset": 2, "type": "CN_CHAR", "position": 1 }, { "token": "中国人", "start_offset": 2, "end_offset": 5, "type": "CN_WORD", "position": 2 }, { "token": "中国", "start_offset": 2, "end_offset": 4, "type": "CN_WORD", "position": 3 }, { "token": "国人", "start_offset": 3, "end_offset": 5, "type": "CN_WORD", "position": 4 } ] }
对于上面两个分词效果的解释:
1. 如果未安装ik分词器,那么,你如果写 "analyzer": "ik_max_word",那么程序就会报错,因为你没有安装ik分词器
2. 如果你安装了ik分词器之后,你不指定分词器,不加上 "analyzer": "ik_max_word" 这句话,那么其分词效果跟你没有安装ik分词器是一致的,也是分词成每个汉字。
2. 创建指定分词器的索引
索引创建之后就可以使用ik进行分词了,当你使用ES搜索的时候也会使用ik对搜索语句进行分词,进行匹配。
PUT book_v5 { "settings":{ "number_of_shards": "6", "number_of_replicas": "1", //指定分词器 "analysis":{ "analyzer":{ "ik":{ "tokenizer":"ik_max_word" } } } }, "mappings":{ "novel":{ "properties":{ "author":{ "type":"text" }, "wordCount":{ "type":"integer" }, "publishDate":{ "type":"date", "format":"yyyy-MM-dd HH:mm:ss || yyyy-MM-dd" }, "briefIntroduction":{ "type":"text" }, "bookName":{ "type":"text" } } } } }
关于ik分词器的分词类型(可以根据需求进行选择):
ik_max_word:会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合;
ik_smart:会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”。如下:
POST book_v6/_analyze { "analyzer": "ik_smart", "text": "我是中国人" } //结果 { "tokens": [ { "token": "我", "start_offset": 0, "end_offset": 1, "type": "CN_CHAR", "position": 0 }, { "token": "是", "start_offset": 1, "end_offset": 2, "type": "CN_CHAR", "position": 1 }, { "token": "中国人", "start_offset": 2, "end_offset": 5, "type": "CN_WORD", "position": 2 } ] }