这里主要是一些简单的ElasticSearch的搜索功能,复杂的搜索,比如过滤,聚合等以后单独在写
1. 搜索全部
GET book/_search
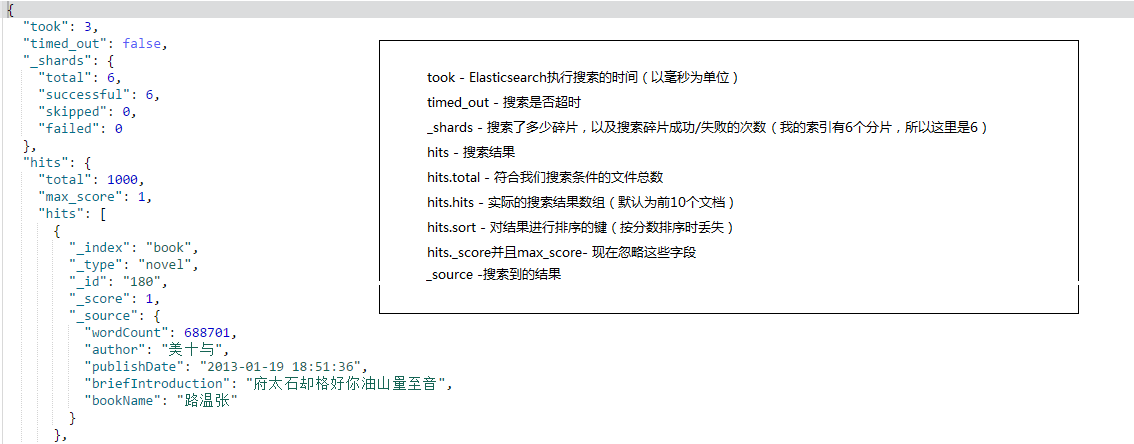
直接搜索全部,下面是对搜索结果的详细介绍:默认情况下,是查询出来10条数据,并且按照score的由高到低顺序排列的(因为搜索全部,这里没有score,当条件搜索的时候,会出现。)
2. 单条件搜索
条件查询分为两类:
- match:match查询的时候,elasticsearch会根据你给定的字段提供合适的分析器,将查询语句分词之后去匹配含有分词之后词语的。
- term:不进行分词,直接完全匹配查询。
- 需要注意的是:如果你搜索的字段是keyword类型,那么无论match和term都是一样的,都不进行分词。
//match进行查询 GET book/novel/_search { "query": { "match": { "author": "美十与" } } } //term进行查询 GET book/novel/_search { "query": { "term": { "author": { "value": "己平" } } } }
解释:查询,需要符合条件:author = “美十与”的结果。这里还有:match_all等其余的方法。
其中 :match_all的是一个空查询,就是查询索引类型下的所有文档。可以查询出所有文档之后在进行过滤等。
3. 多条件查询
GET book/novel/_search { "query": { "bool": { "must": [ { "match": { "wordCount": "8343705",
"author": "123"
} } ], "must_not": [ { "match": { "author": "天回" } } ] } } }
其中:bool可以用来实现多条件查询,bool包含的属性如下:
must:表示必须匹配的属性,匹配这些条件才能被包含进来
must_not:表示不能匹配这些条件才能被包含进来。
should :如果满足这些语句中的任意语句,将增加 _score ,否则,无任何影响。它们主要用于修正每个文档的相关性得分。
filter :必须 匹配,但它以不评分、过滤模式来进行。这些语句对评分没有贡献,只是根据过滤标准来排除或包含文档。
需要特别注意的是: match不支持多条件查询,会提示 [match] query doesn't support multiple fields, found [author] and [wordCount]"。
一个复杂查询的例子(未经验证)
{ "bool": { "must": { "match": { "email": "business opportunity" }}, "should": [ { "match": { "starred": true }}, { "bool": { "must": { "match": { "folder": "inbox" }}, "must_not": { "match": { "spam": true }} }} ], "minimum_should_match": 1 } }
4. 排序,分页
GET book/novel/_search { "query": { "match": { "author": "天为回" } }, "from": 0, "size":10, "sort": [ { "wordCount": { "order": "desc" } } ] }
其中:from:表示分页开始的条数(也是从0开始),size表示你要查询的数量。
sort:排序的字段,根据哪个字段进行如何排序,上面例子:根据wordCount字段倒序排列。