这是2016年的最后一篇博客,年初定的计划是写12篇博客,每月一篇,1/3转载,2/3原创,看来是实现不了了! -- 题外话。今天要写的东西是C语言中的预处理器,我们常说的宏定义的用法。为什么要写这个东西呢,原因很简单:之前对预处理了解不深。如果你对C语言只是了解或者是仅仅在大学中学习过C语言,说到预处理估计你只知道下面这条语句:(因为我就是这种情况,哈哈!)
1 #define name value
我再学习预处理直接的驱动力是看了php的源码,开头一大推的宏定义器,之前'掌握'的一点#define的用法太少了,根本看不懂源码中宏的处理逻辑和运行的路径。所以再学习预处理器很有必要,里面好多东西其实并不难,只是你没有接触到,等你学习了,就感觉容易了。
一、宏定义和使用中的坑
这小节采用先给代码再说明的形式,这样你可以看看每个代码的运行结果是否和你预期的一致!
宏是什么,宏就是#define机制把指定的参数替换的文本中,这样的实现方式就是宏。使用宏定义可以抽出频繁调用的函数,加快执行的速度。定义如下:#define name(参数) 执行体... “参数”可以是使用逗号分隔的参数列表,这些参数可以被应用到执行体中,必须要注意的是“参数”的左括号必须和宏名字紧邻,不然编辑器会报错,或者被解释成执行体中的一部分。比如你写了一个 TEST(a) a * a 调用执行的时候写上 TEST(1) 实际执行的是替换后的 1 * 1。
凡事都有利弊,宏定义固然使用方便,并且有着函数不可比拟的执行速度,但是宏定义中存在不少的坑,下面就说一说这个坑。看下面的代码:

1 #include <stdio.h>
2
3 #define TEST(a) a * a
4
5 int main() {
6 int b = TEST(2);
7 int c = TEST(1+2);
8 printf("b=%d, c=%d", b, c);
9 printf("
");
10 }
没有执行的情况下,你感觉得到的结果是多少呢!好多人不加思索的说:b=4,c=9。如果真是这样,就不存在坑了,实际打印出来是:b=4, c=5 ,为什么c的值和预想的会有偏差,其实你把执行体中的值替换一下试试,就不难发现问题了,当输入1+2的时候,宏替换成了 1+2*1+2,当然就是5了。好了明白了,那你学会了吗?学会了再看一个:
1 #include <stdio.h>
2
3 #define TEST(a,b) ((a) > (b) ? (a) : (b))
4
5 int main() {
6 int zyf = 1;
7 int abc = 2;
8 int ret = TEST(zyf++, abc++);
9 printf("zyf=%d,abc=%d,ret=%d", zyf, abc, ret);
10 printf("
");
11 }
输出多少呢,如果是 zyf=2,abc=3,ret=3 就错了,实际结果是:zyf=2,abc=4,ret=3 。道理和前面的一样,只看替换后的结果才能真正看到答案。
这样的问题防不胜防,怎样才能解决呢,其实办法很简单,错误的原因是执行的顺序和我们预想的不一样,那添加小括号应该可以解决这种问题。 比如 (a) * (a)。这样其实也不是最万全的办法,比如你看这个:ADD(a) (a) + (a) ,如果这样调用:ADD(2) * 5 ,这样又不行了,被替换成了 (a) + (a) * 5 执行顺序和预想的还是不一样,所以还要在最外层加上括号:((a) + (a)),这样就解决了。
二、预定义符号
C语言中有几个预定义的符号,还是有必要和大家说上一说,先看一段代码:
1 #include <stdio.h>
2 #include <stdlib.h>
3 #define VAR_DUMP printf(
4 "[
file:%s
"
5 " line:%d
"
6 " time:%s %s
"
7 " value:%d
]",
8 __FILE__, __LINE__, __DATE__, __TIME__, value
9 )
10 int main() {
11 int value = 1;
12 VAR_DUMP;
13 printf("
");
14 }
是不是和你在大学学习的有点不一样,最简单的宏定义可以使用#define name value 的方式,当然也可以把值写成一个函数,运行的时候直接替换函数。这个宏定义是封装了调试方法,是打印变量内容能像PHP中var_dump()或者print_r()函数一样,打印出变量的内容。
从这段代码中能学习到几点内容:
1、使用#define可以使任何文本替换到程序中,在主程序中你可以随意使用VAR_DUMP。
2、宏定义不以分号结束,如果非常长的宏定义,你可以在末尾加上反斜杠来分行,保持代码易读性。
3、你可以定义频繁调用的函数为宏定义,这样可以加快执行的速速,具体原因后面会说到。
4、C语言有几个预定的符号需要我们知道,很多时候特别有用:
__FILE__ 预编译的文件名
__LINE__ 文件当前行的行号(执行到这一行)
__DATE__ 文件编译的日期
__TIME__ 文件编译的具体时间
__STDC__ 是否遵循ANSI C (不常用)
最后附上运行结果,如图:

三、宏替换的过程
在程序的编译阶段,宏先被执行替换,一般要涉及下面的步骤:
1、调用宏的地方看是否 进行了 #define定义,如果是就进行替换。
2、把替换的文本信息插入到替换的位置,其中参数被替换成了实际的值。
3、#define可以包含其他定义的#define定义的东西,需要注意的是不能出现递归的情况。
因为替换存在临近字段自动结合,所以可以使用一些巧妙的方案:
1 #include <stdio.h>
2 #include <stdlib.h>
3
4 #define VAR_DUMP(A,B)
5 printf("Value of " #B " is " A "
", B)
6
7 int main(){
8 int x = 1;
9 VAR_DUMP("%d", x+2);
10 }
四、条件编译和其他宏用法
在大型的C程序中你能看到许多的条件编译,比如可以根据当前的环境加载不同的宏配置,或者在编译的时候加上直极预设的编译条件。这些东西的实现都离不开条件编译。
1、条件嵌套,#if #endif 原型:
1 #if condition 2 执行体 3 #endif
可以根据condition来确定执行体要不要执行,以此来控制在不同的环境下编译成不同的系统。看下面的代码,当把DEBUG定义成非0值时,MAX宏定义是存在的,当定义成0时,程序就会报错。
1 #include <stdio.h>
2
3 #define DEBUG 0
4 #if DEBUG
5 #define MAX(a) ((a) * (a))
6 #endif
7
8 int main() {
9 int b = MAX(2);
10 int c = MAX(1+2);
11 printf("b=%d, c=%d", b, c);
12 printf("
");
13 }
当然#if 也可以与#elif嵌套使用,这样就和我们在函数里使用if else一样了,下面是一段php源码中的一段话,你能看到编译php指定不同的参数,检查不同的环境等等都可以通过预处理中的条件编译开完成。
1 #ifndef PHP_H
2 #define PHP_H
3
4 #ifdef HAVE_DMALLOC
5 #include <dmalloc.h>
6 #endif
7
8 #define PHP_API_VERSION 20100412
9 #define PHP_HAVE_STREAMS
10 #define YYDEBUG 0
11
12 #include "php_version.h"
13 #include "zend.h"
14 #include "zend_qsort.h"
15 #include "php_compat.h"
16 #include "zend_API.h"
17
18 #undef sprintf
19 #define sprintf php_sprintf
20
21 /* PHP's DEBUG value must match Zend's ZEND_DEBUG value */
22 #undef PHP_DEBUG
23 #define PHP_DEBUG ZEND_DEBUG
24
25 #ifdef PHP_WIN32
26 # include "tsrm_win32.h"
27 # include "win95nt.h"
28 # ifdef PHP_EXPORTS
29 # define PHPAPI __declspec(dllexport)
30 # else
31 # define PHPAPI __declspec(dllimport)
32 # endif
33 # define PHP_DIR_SEPARATOR '\'
34 # define PHP_EOL "
"
35 #else
36 # if defined(__GNUC__) && __GNUC__ >= 4
37 # define PHPAPI __attribute__ ((visibility("default")))
38 # else
39 # define PHPAPI
40 # endif
41
42 # define THREAD_LS
43 # define PHP_DIR_SEPARATOR '/'
44 # define PHP_EOL "
"
45 #endif
46
47 #ifdef NETWARE
48 /* For php_get_uname() function */
49 #define PHP_UNAME "NetWare"
50 #define PHP_OS PHP_UNAME
51 #endif
52
53 #if HAVE_ASSERT_H
54 #if PHP_DEBUG
55 #undef NDEBUG
56 #else
57 #ifndef NDEBUG
58 #define NDEBUG
59 #endif
60 #endif
61 #include <assert.h>
62
63 #else /* HAVE_ASSERT_H */
64 #define assert(expr) ((void) (0))
65 #endif /* HAVE_ASSERT_H */
66
67 #define APACHE 0
68 #if HAVE_UNIX_H
69 #include <unix.h>
70 #endif
71
72 #if HAVE_ALLOCA_H
73 #include <alloca.h>
74 #endif
75
76 #if HAVE_BUILD_DEFS_H
77 #include <build-defs.h>
78 #endif
79 . . .
2、是否已经被定义
被定义:#if define() 或者是#ifdef
不被定义:#if !define() 或者是#ifndef
前者的写法虽然没有后者精炼,但是前者有更多的使用场景,比如下面这种,可以进行嵌套执行。
1 #if defined(DEBUG) 2 #ifdef DEBUGTWO 3 #define TEST(a) a * a 4 #endif 5 #endif
3、移除一个宏定义,当不再使用一个宏定义后,可以使用undef来把不需要的宏移除,原型:
1 #undef name
五、宏命名规则和与函数区别
从前面的使用中我们可以看到,宏的使用规则和函数真是一模一样,但是本质上还是有区别的,在使用中怎样区别宏和函数,涉及到代码规范和代码的可读性问题。标准的宏使用应该使用大写字母,这样在程序中任意地方使用宏都会知道这是一个宏定义。比如前面用到的 #define TEST(a) ((a) * (a))。
宏与函数区别有以下几点:
1、执行速度上,宏定义更快,函数因为需要调用栈,存在调用,返回,保存现场的系统开销,所以比宏要慢。
2、代码长度上,宏在代码长度上实际是增长的,每一处的使用宏都会把name替换成宏内容如果大量使用,会是代码显著增长,函数代码只有一份,比较节省代码空间。
3、参数类型上,宏没有参数类型,只要可以 使用都行。函数不一样,函数有参数类型确定性。正式因为这样,有些宏能巧妙的利用这一点,完成函数不能完成的任务,看下面代码(书上看的),巧妙的利用传递类型无限制的特点自动开辟想要的各种类型空间:
1 #include <stdio.h>
2 #include <stdlib.h>
3
4 #define CREATE_P(nums, type) ((type *) malloc((nums) * sizeof(type)))
5
6 int main(){
7 int nums = 2;
8 CREATE_P(nums, int);
9 }
4、宏定义和函数的使用场景,宏定义一般在程序的开头,函数转化成宏定义一定要考虑成本问题,短小精炼的函数转化成宏使用时最好的,功能负责的函数转化成宏就有点得不偿失了。
六、文件包含
1、本地文件包含和库文件包含
文件包含在大型系统中必然会用到,大型系统宏定义巨多无比,不可能把所有的宏定义都复制到每个文件中,那么文件包含就能解决这种问题。
实际上编辑器支持两种文件包含,一种是我们经常会用的库文件的包含,比如上面我们看到的:#include <stdio.h>,还有一种是本地文件包含,说白了就是我们自己写的文件,包含的原型如下:
1 #include <filename> 2 #include "filename"
这两种方式都可以进行文件的包含,不同的是第一种是库文件的包含,标准的C库函数都会以.h扩展名结尾,第二种是本地文件包含,当编辑器看到第二种方式时,优先查找本路径下得本地库文件,如果没有找到就会像包含库文件那样在指定的路径下去找,这时第二种和第一种就差不多了。第二种包含方式在编码习惯上也是比较好的,别人看你的代码很容易知道这个文件是库函数还是你自己写的。
1、嵌套文件包含
大型系统中不仅有大量的文件包含,还会有大量的嵌套文件包含,看下面的例子:
a.h,b.h,c.h,define.c文件,其中a,b,c,define文件的内容如下:
1 a.h:
2 #include "c.h"
3 void var_dumpa(){
4 test obja;
5 obja.a[1] = 2;
6 printf("obja.a[1]: %d
", obja.a[1]);
7 }
8
9 b.h:
10 #include "c.h"
11 void var_dumpb(){
12 test objb;
13 objb.a[1] = 2;
14 printf("objb.a[1]: %d
", objb.a[1]);
15 }
16
17 c.h:
18 #include <stdlib.h>
19 #include <stdio.h>
20
21 typedef struct test{
22 int a[10];
23 }test;
24
25 define.c:
26 #include <stdio.h>
27 #include "a.h"
28 #include "b.h"
29
30 int main() {
31 var_dumpa();
32 var_dumpb();
33 printf("
");
34 }
ab文件包含c文件,define.c文件文件引用a,b文件后会引发一个错误:typedef struct test类型错误,因为c.h文件被包含了两次,像这种情况在大型系统中会经常遇到,或者说,你会发现重复引用库文件也不会报错,由此可见,库文件一定是使用了解决办法。其实解决这种错误的方案就是采用条件编译,当这个文件引入到另一个文件中后我们可以设置一个宏定义,比如:
1 #include <stdlib.h>
2 #include <stdio.h>
3
4 #ifndef PATH_C_H
5 #define PATH_C_H 1
6 typedef struct test{
7 int a[10];
8 }test;
9 #endif
因为每次编译编译器都会读入整个头文件,如果把所有的文件都加上这个条件编译的话,那交叉引用文件产生的重复宏编译问题就解决了,运行如下:
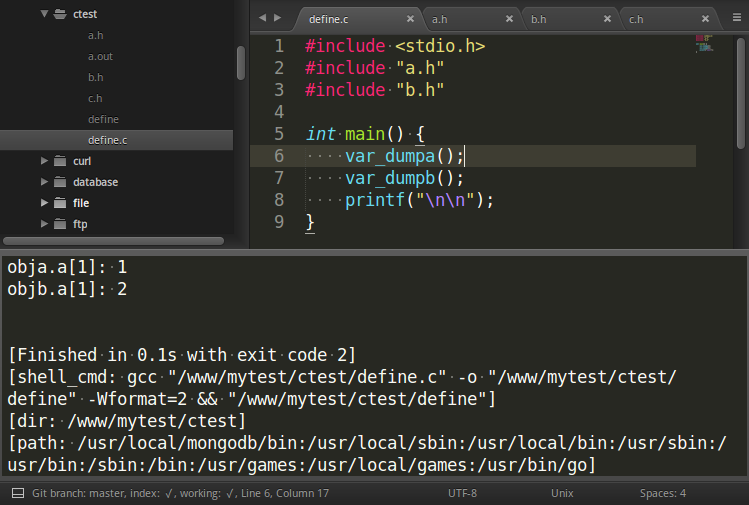
好了,就写这么多吧,重新梳理了对宏定义的认识和基本的使用。时间仓促,出错的地方请大婶们一定指出,万分感谢!