本以为学会了Python 就已经天下无敌, 果然, 我还是太傻太天真了. 业务中几乎就没有用 Python 来直接连接数据库进行操作, 当然我是说数据这块哈. 哎, 难受, 还是用的 sql 这种方式. 但有个问题在于, sql 没有类似于编程语言那样来用个数据结构存储存储中间过程, 于是呢, 在写 "套娃" 就是 sql 嵌套的时候, 可难受了, 一不小心就会写乱, 阅读体验也不好, 但, 又没有其他的办法, 只能去多加练习去适应哦.
表关系
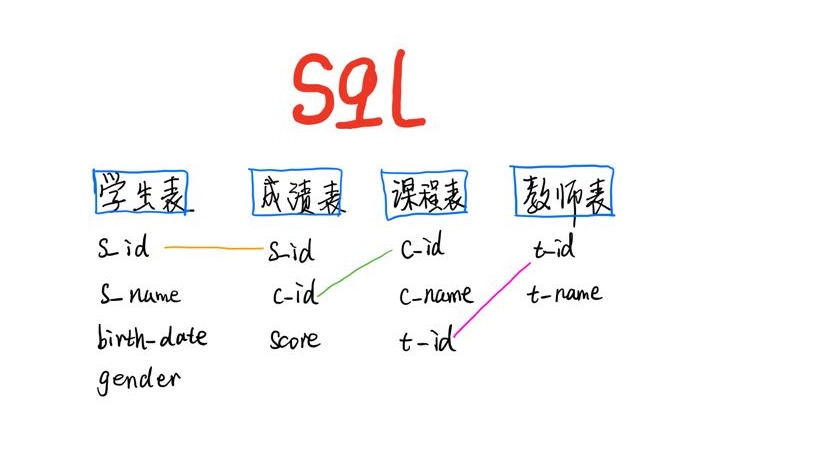
反复练习, 只能这样去提高理解了, 果然是唯手熟尔, 对此我深信不疑.
需求 01
-- 查询 没有学全所有课程的学生学号, 姓名
分析
student 表 left join score 表, 然后在 group by s_id 再 having 选课数量 < 实际有多少门课
-- 先看看总体情况
select
st.*,
sc.*
from student as st
left join score as sc
on st.s_id = sc.s_id
tips: 一定要用 left join 这样才不会漏掉有学生压根就没有选过课的情况
+------+-----------+------------+--------+------+------+-------+
| s_id | s_name | birth_date | gender | s_id | c_id | score |
+------+-----------+------------+--------+------+------+-------+
| 0001 | 王二 | 1989-01-01 | 男 | 0001 | 0001 | 80 |
| 0001 | 王二 | 1989-01-01 | 男 | 0001 | 0002 | 90 |
| 0001 | 王二 | 1989-01-01 | 男 | 0001 | 0003 | 99 |
| 0002 | 星落 | 1990-12-21 | 女 | 0002 | 0002 | 60 |
| 0002 | 星落 | 1990-12-21 | 女 | 0002 | 0003 | 80 |
| 0003 | 胡小适 | 1991-12-21 | 男 | 0003 | 0001 | 80 |
| 0003 | 胡小适 | 1991-12-21 | 男 | 0003 | 0002 | 80 |
| 0003 | 胡小适 | 1991-12-21 | 男 | 0003 | 0003 | 80 |
| 0004 | 油哥 | 1996-10-01 | 男 | NULL | NULL | NULL |
+------+-----------+------------+--------+------+------+-------+
果然, left join 就能把 "油哥" 这个兄弟, 一门课都不选的特例, 也给筛选出来了哦.
然后, "没有选全" , 也就是 group by 学生id, count(课程号) < 总课程数 了呗. 组内筛选用 having.
select
st.*,
sc.*
from student as st
left join score as sc on st.s_id = sc.s_id
group by st.s_id having
count(distinct sc.c_id) < (select count(distinct c_id) from course);
+------+--------+------------+--------+------+------+-------+
| s_id | s_name | birth_date | gender | s_id | c_id | score |
+------+--------+------------+--------+------+------+-------+
| 0002 | 星落 | 1990-12-21 | 女 | 0002 | 0003 | 80 |
| 0004 | 油哥 | 1996-10-01 | 男 | NULL | NULL | NULL |
+------+--------+------------+--------+------+------+-------+
这样不就, 获取到了 s_id 了吗, 然后在外面给套上一层, 就搞定了哦.
select
s_id as "学号",
s_name as "姓名"
from student where s_id in (
select
st.s_id -- 只要学号即可
from student as st
left join score as sc on st.s_id = sc.s_id
group by st.s_id having
count(distinct sc.c_id) < (select count(distinct c_id) from course)
);
+--------+--------+
| 学号 | 姓名 |
+--------+--------+
| 0002 | 星落 |
| 0004 | 油哥 |
+--------+--------+
2 rows in set (0.00 sec)
需求 02
查询 至少有一门课, 与学号为 "0001" 的学生, 所学课程相同, 的学生学号和姓名.
分析
先看 0001 这个老铁选了哪些课, 然后从 score 中查出 选个这个课有哪些学生学号 不就行了嘛
select c_id from score where s_id = "0001";
+------+
| c_id |
+------+
| 0001 |
| 0002 |
| 0003 |
+------+
这个兄弟, 把 1,2,3 号课程都给选上了, 果然是学霸, 目测.
然后再看, score 中 也选择了这些课的学号有哪些.
select
s_id,
c_id
from score
where c_id in (
select c_id from score where s_id = "0001"
);
+------+------+
| s_id | c_id |
+------+------+
| 0001 | 0001 |
| 0003 | 0001 |
| 0001 | 0002 |
| 0002 | 0002 |
| 0003 | 0002 |
| 0001 | 0003 |
| 0002 | 0003 |
| 0003 | 0003 |
+------+------+
8 rows in set (0.00 sec)
这样就把跟 0001 同学有选相关的课程的所有兄弟的, 学号, 课号给 拉出来了. 然后, 需要再对学号进行去重, 同时呢, 还需要将 0001 自己给排除掉哦
select
s_id as "学号",
s_name as "姓名"
from student where s_id in (
select distinct s_id from score
where c_id in (
select c_id from score where s_id = "0001"
)
-- 排除自己
and s_id != "0001"
);
+--------+-----------+
| 学号 | 姓名 |
+--------+-----------+
| 0002 | 星落 |
| 0003 | 胡小适 |
+--------+-----------+
2 rows in set (0.00 sec)
当然, 也可以用 inner join 的方式, 当数据量比较大的时候, 感觉用 join 的方式会更加快一点哦
select
a.s_id as "学号",
a.s_name as "姓名"
from student as a
-- 内连接查出的学号
inner join (
select distinct s_id from score
where c_id in (
select c_id from score where s_id = "0001"
)
-- 排除自己
and s_id != "0001") as b
on a.s_id = b.s_id;
+--------+-----------+
| 学号 | 姓名 |
+--------+-----------+
| 0002 | 星落 |
| 0003 | 胡小适 |
+--------+-----------+
2 rows in set (0.00 sec)
小结
- 灵活应用 join, group by + having 这样的子查询的方式, "面向过程" 写sql, 就是一点点查出来.
- 当考虑数据量的时候, 如果先用的子查询, 在查询效率上, 可能也应多考虑 join 来进行配合使用
- 感觉sql 其实和面向过程的编程是一样的, 查一个表就取个别名, 然后继续查, 拼接, 或者套娃啥的, 感觉熟练了就会好还多的, 还是需要不断练习哦.