我们都知道,相较于传统的数据中心,Pulic cloud也有劣势,比如说数据库的HA,很多熟悉公有云平台的读者都知道,因为出于安全性性考虑以及一些技术条件的限制,很多本地数据中心的mysql HA方法在云上并不适用,笔者大致地归纳了一下,主要有如下这三个瓶颈造成:
1.不能共享存储的问题
2.不支持组播问题
3.VIP的问题
关于第一个问题,很多用过Azure的读者会不禁要问,不对啊?我记得Azure是提供Azure file service服务的啊,确实,但是玩过的人都知道file service只能解决部分问题,而且有性能的瓶颈,所以在本次方案中,没有选用该方法;
关于第二个问题,我们都知道,公有云平台都是禁止组播与广播的,然而集群软件是需要组播进行同步的,这也就是为什么Oracle在云平台做不了RAC,就是这个原因,不过据说有方式可以实现,就是组播一出来就改为单播的方式去响应,有兴趣的读者可以去百度看看;
关于第三个问题,VIP在cluster的解决方案中,可以解决前端应用连接字符串的问题,但是云上是不支持组播与广播的的,所以ARP类似的协议都不能支持,造成传统的VIP模式不再适用
基于以上因素的考量,我们选择Azure ILB+DRBD+Corosync+pacemaker来实现HA,以此来解决以上部署中遇到的问题。
好,废话不多说,先贴一张架构图。
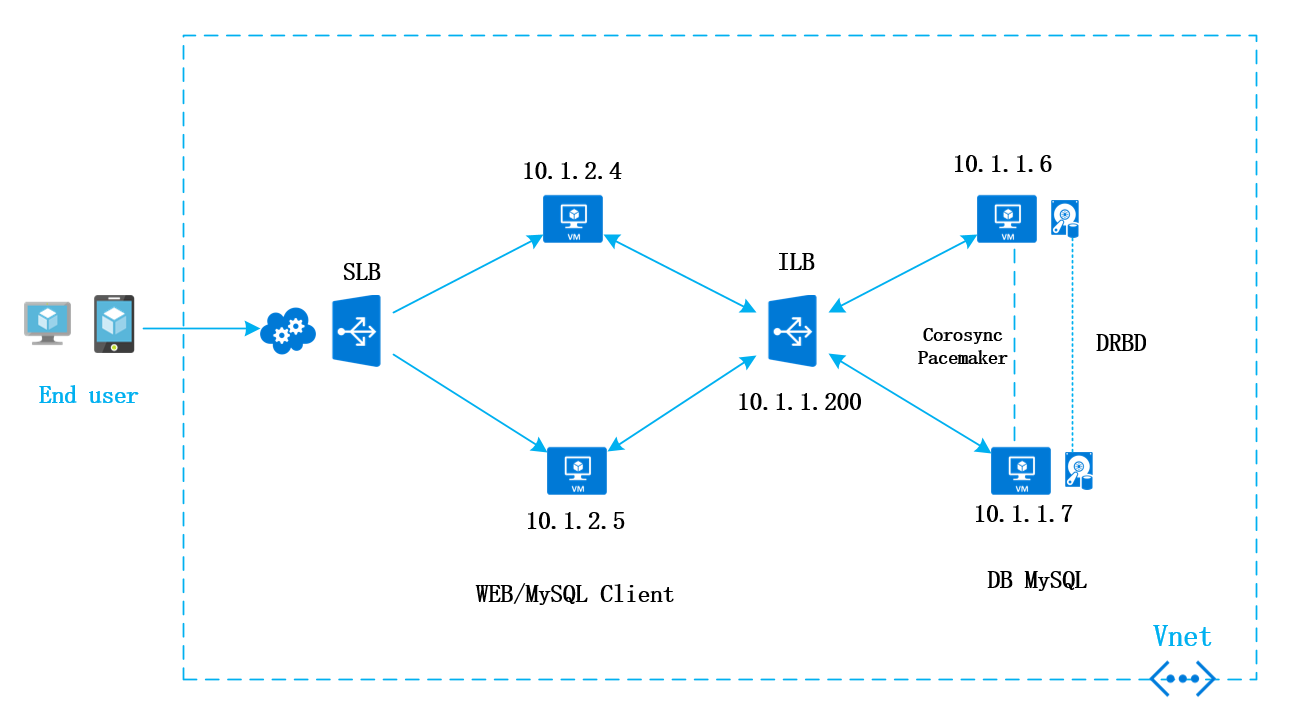
web服务器通过mysql client访问ILB,ILB转发3306端口到后台的mysql
从上面的架构图看以看出来
接下来我们来分析各个软件与机制的功能与作用
1:Azure ILB :WEB前端可以通过MySQL客户端访问Azure ILB的固定IP地址10.1.1.200端口3306,ILB会把mysql的相应的请求转发给相应mysql服务器,但是,无论mysql的服务迁移到哪一台服务器上,前端不需要在应用层面做任何改动,也就是说不需要改动然后连接字符串,用这种方式实现on-premise环境中VIP相同的效果。
2.DRBD:DRBD相当于网络级别的RAID1,在DRBD主节点上写入任何数据,都会通过网络马上同步到副节点。通过DRBD的公牛,可以实现两边数据的同步,这样就类似于共享存储的功能。
3.Corosync:其实所谓的Corosync和Pacemaker是Heartbeat的升级版。Corosync进行底层Message的通信,Pacemaker进行集群的选举和服务的编排。传统的Corosync是采用Multicast实现多台Cluster服务器的message通讯。但在新版本中支持Full Mesh的UDP Unicast,解决Azure不支持组播的问题。
4.Pacemaker:Pacemaker是整个集群的大脑,它决定做什么,以及何时做。这个集群的服务通过一个叫CRM的软件进行对Pacemaker的编排。在本方案中,Pacemaker需要完成如下几个工作:
第一,先要选择DRBD的master节点
第二,挂载DRBD的分区到指定目录
第三,启动MySQL的服务
第四,保证DRBD,File,MySQL三个服务在同一台master服务器上,这一点非常重要
第五,保证DRBD,File,MySQL三个服务按顺序启动
一般正常情况下,Pacemaker把编排好的各种服务在master上顺序启动时,在master上mysql写入任何数据,都会通过DRBD更新到slave服务器的DRBD secondary磁盘上,由于slave服务器上的mysql服务部位启动,所以它的3306端口不对外提供服务,这样ILB就会认为slave服务器没有对外提供服务,就不会将其加入到负载均衡集中,因此ILB只会把mysql的请求全部发给master服务器,如下图所示。

但是当主库出现问题的时候,这里就是10.1.1.6出现故障或需要执行重启动作的时候,这个时候Pacemaker和Corosync会把master迁移到10.1.1.7上,Pacemaker会在10.1.1.7启动之前上编排各种服务,mysql服务会在这台服务器上启动,这时3306端口会对外提供服务,这时候ILB会把10.1.1.7加入到负载均衡集中,这样所有前端的mysql请求都会发到这台服务器上,如下图所示。
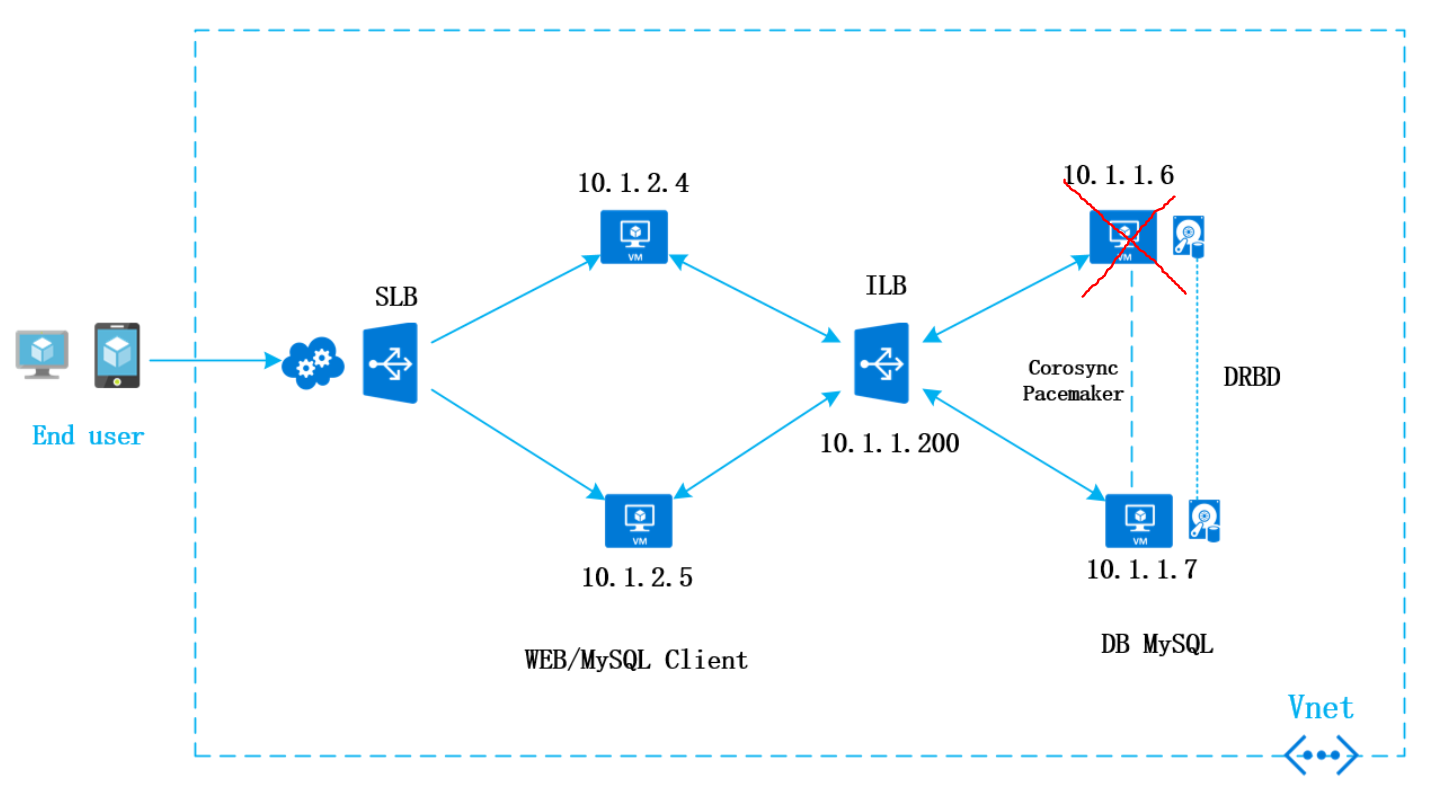
这样的话,无论10.1.16还是10.1.1.7出现故障,整个系统都不需要人为地进行干预,系统都会自动切换到那台仍然活着的服务器上,对外继续提高服务。
讲到这里,我们仔细想想,这样真的就万无一失了嘛?好像还缺点什么,对就是“脑裂”问题,在实现Cluster的时候,往往最需要回避的问题就是脑裂问题,因为脑裂的问题带来的危害比out-of-service的危害还大,在刚刚场景中,细心的读者会发现,前面的方案中防止脑裂都是通过DRBD Corosync以及Pacemaker等软件自身机制实现的,但是在最后一个场景中,当10.1.1.6出现问题时,我们会把10.1.1.7加入到ILB中,但此时10.1.1.6仍然在ILB中!!!即使它出了故障,如果说在10.1.1.7在执行前端mysql的请求的时候,10.1.1.6的突然活过来了了,那TM就尴尬了,这时候就会产生脑裂。
基于这种情况的考虑,我们需要对ILB的做一些策略,来防止脑裂的发生,最好的情况就是任何时候Pacemaker选择某一台服务器作为master的时候,在Pacemaker服务的编排中,加入对ILB的控制,把另一台服务器从ILB中,且不考虑它是否活着,这样可以最大程度地阻止脑裂,最极端的情况就是两台服务器都认为自己是master,后一台启动Pacemaker的服务器会把另外一台服务器从ILB中移除,永远保证ILB中只有一台服务器,保证前端通过ILB只能访问到一台mysql服务器。