之所以要写这样的一篇博文的目的是对于大多数搞IT的人来说,一般都会对这个topic很感兴趣,因为底层架构直接关乎到一个公有云平台的performance,其实最主要的原因是我们的客户对此也非常感兴趣,毕竟很多客户以前都是做网络存储系统出身,他们对底层架构的兴趣甚至超过了Azure所提供的功能,基于以上原因,所以笔者感觉有必要初步分析一下Azure的底层架构。
在分析Azure的底层架构之前,我觉得有必要说一下Azure的所使用的硬件,其实在初期,Azure的cpu使用过AMD的,但是现在Azure的cpu都是Intel Xeon E系列,x86架构,RS全部为cisco的设备,负载均衡器都为F5的
接下来我们来分析Azure的底层架构,我们都知道,在传统的网络架构中,我们都采用pod架构,如下图,这种架构是基于L2来做的,先由接入层到核心层,核心层连路由网关,或者在中间有firewall

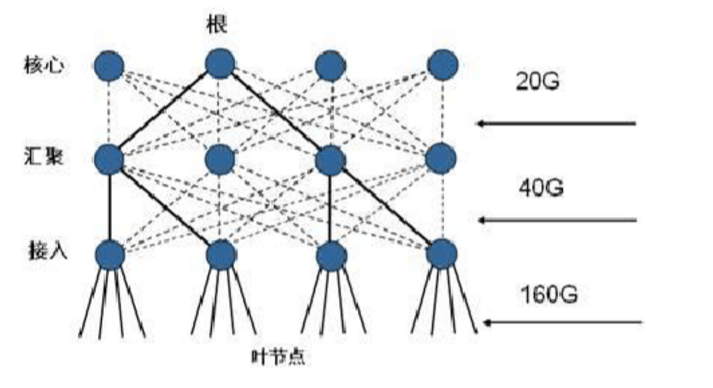
但是我们知道,这种传统的基于大量二层+少量三层的架构有致命的缺陷,就是stp与vlan的限制,我们知道交换机在处理广播报文的方式是泛洪,为防止形成广播风暴,必须运行stp来block掉某个端口,这样就会有造成如下的缺点,低效的路径,造成大量闲置带宽,维护成本高昂,可靠性很低,在运行stp的架构中数据中心最多可接入百台双网卡服务器,远不能满足大型数据中心的要求,第二点,就是传统vlan的数量限制(4096个,远不能满足数据中心的大规模组网),同时基于IP子网的区域划分限制了需要二层连通性的应用负载的部署,TOR交换机mac表耗尽,以及多租户场景都无法满足,此外虚拟化技术的发展,使得虚拟机在二层域的动态迁移中显得非常困难,以及收敛比等问题,这时就急需一种新的网络架构,fabric架构应运而生
fabric架构应用了大量的新兴的技术,实现了大二层,运用了trill vxlan等技术,架构图如下
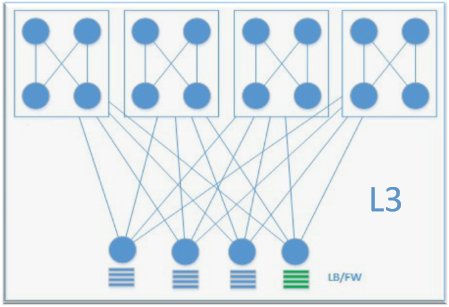

fabric架构有相对于传统的网络架构,fabric架构将多台物理的交换机看成一台巨大的逻辑交换机,不受stp限制,互相之间都可以通信,节约物理链路的带宽,优化了收敛比,可以实现二三层飘移,同时没有ARP广播和未知单播泛洪等现象,像传统的路由网络一样可以扩展,任意服务器可以在任意vlan,vlan可以扩展到全网, 任意位置都可以做任意vlan路由,同一vlan网关要一致,任意vlan内和任意vlan之间都可以做类似三层路由的方式通信 ,提供更灵活的拓扑,节点小型化,分布扁平化等优点 。
以上就是笔者粗浅地对比了两种架构,有兴趣的读者可以自行百度,这里就不再展开细说,接下来我们重点来看Azure的底层架构,并且这里隐去RS部分,只看计算单元,首先附上两张图,第一张是Azure的计算单元的实物图,另一张是本人手绘的Azure的计算单元图,废话不多说,上图

实物图

手绘图
Azure是将计算单元分成一个个独立的cluster,在这里笔者想提醒一句,在老的portal里面,以前有一个地缘组的概念affinity group,很多人不明白这一概念,以为只是中国东部数据中心和中国北部数据中心的别名,这一认识是完全错误的,地缘组的概念其实不是这样,在我们的Azure数据中心内部,是由若干个容器组成,每个容器包含了群集/机架,每个容器都有特定的服务与功能,包括计算和存储,举个例子来说,当你建了一台vm,然后你又给该vm建立了存储账户,假如我们在建立这两个服务的时候计算资源放在数据中心的内部,而存储资源放到了数据中心外围,显而易见这不是我们想预见的结果,最好的结果是能放在同一数据中心比较靠近的位置,最好能在同一群集里,所以就有了地缘组的概念,放在同一地缘组的云资源会放在同一数据中心比较靠近的地方,甚至同一个群集里,这样的好处是能够降低时延,但是Azure已经逐步淡化这一概念,在这里笔者只是想提醒大家一下,以后再碰到这个概念不要混淆。
从上面的图中我们可以看出,一个cluster中包含了20个chassis,每个chassis有96台机器,每个chassis上都有几台SLB,在以前,Azure的SLB(负载均衡器)都由虚拟机来做,但是后来微软发现用虚拟机来做SLB性能并不理想,所以全部用物理机来做,在SLB外面附着一些VIP(在这里你可以将它看成一个SLB的公网IP地址,关于Azure的几种IP地址,笔者会在后续的博文中详细介绍,这里先不展开叙述),每个chassis上面还有一个FC(Fabric Controller),管理这个chassis上资源的分配,千万不要小看它,它是一个chassis的核心部位,每个chassis上包含了不同类别的虚拟机,可能有只有A系列的虚拟机,如A0-A4或者A1-A7,也或者包括了D系列,Dv2系列虚拟机,甚至还有F系列虚拟机(G系列与H系列虚拟机在国内仍没有preview,只有global账户才能建立)。
但是我们会发现一个重要的问题,并不是每个chassis上都包含所有系列的虚拟机,有的甚至只有A0—A4或者A1—A7的虚拟机(这都是Azure初建数据中心的老的chassis,现在可能只有很少的一部分了),还记得在上面的博客中笔者提醒大家在建虚拟机的时候先建立D系列虚拟机,然后再降为A系列虚拟机,就是这个原因造成的,当我们在建立vm的时候,FC会去看哪个chassis上的资源比较闲置,然后扔给最不忙的那个chassis ,如果你先选建立一个A系列虚拟机,FC有可能碰巧将它扔在了某个只有A系列虚拟机的chassis上,等你再想做纵向扩展的时候会发现虚拟机不能D系列了,就是这个原因造成的,所以我竭力建议大家先建高配的虚拟机,然后再降为低配的虚拟机。
但是就是这样就结束了嘛,其实远不是这样,其实在Azure最老某些的cluster里面只有A系列虚拟机,这就相当可怕了,因为这样你不仅不能纵向扩展,也不能横向扩展,为什么?所谓横向扩展就是建立可用性集,然后将多台虚机加入同一可用性集,以实现HA,同一可用性集的虚拟机的意思就是在同一cluster而不在同一chassis上面,这样既提供高可用有提供了冗余(不在同一chassis的目的是为了防止该chassis出问题而导致整个可用性集里的虚拟机全部挂掉),但是你整个cluster里面都只有A系列虚拟机,那你横向扩展只能扩展多台A系列虚拟机,这就是某些客户碰到的问题,说先建立了某两台A系列的虚拟机,并且加入了某个可用性集,但是后来发现再建了一台D系列的虚拟机不能加入这个可用性集了,就是这个原因造成的,因为那两台虚拟机很有可能被扔进了某个只有A系列的虚拟机的cluster里造成的,但是反过来如果我们先建立一台D系列虚拟机,并且加入某个可用性集,再去A系列虚拟机加入该可用性集,这样就一定不会出问题,因为第一台D系列虚拟机决定了你的cluster,这句话一定要理解,所以我们在建立虚拟机的时候一定要记得先建立高配置的虚拟机,然后再降为低配的!!!