这两天看了《SQL必知必会》第四版这本书,并照着书上做了不少实验,也对以前的概念有得新的认识,也发现以前自己有得地方理解错了。我采用的数据库是SQL Server2012.数据库中有一张比赛成绩表,表里有四个字段。下面变列出我新学到的知识。
这个是数据库的全部记录

1.order by
语句: select * from Scores order by name , Score desc
执行结果:

①order by在执行排序功能时,会先对排序字段按abcd这样的顺序进行,汉字的话是按拼音的首字母,默认是正序。
②例子中先按name字段进行正序排序,当name相同时,又按score倒叙排,例如拜仁两条数据,胜的开头字母是s,负的是f,因为是倒叙,所以胜的那条数据排在前面。
2.通配符 _ 和 %
通配符 _表示的是匹配单个字符,而%则是匹配多个字符。具体写法两者无差别。
select * from Scores where name like '拜_' select * from Scores where name like '拜%'
注意:①通配符%看起来像是可以匹配任何东西, 但有个例外, 这就是NULL。 子句where name like '%' 不会匹配产品名称为NULL的行。
②不要过度使用通配符。 如果其他操作符能达到相同的目的,应该使用其他操作符。
在确实需要使用通配符时, 也尽量不要把它们用在搜索模式的开始处。 把通配符置于开始处, 搜索起来是最慢的。
3.拼接字段 +
语句: select name+ '('+ Score +')' as ac from Scores
执行结果:

拼接字段就算把两个字段合成一个字段的查询出来。
4.文本处理函数
①SQL中有很多内置函数,这个表是常用的文本处理函数。

语句: select upper(name) from Scores
select len(name) from Scores
select left(name,1) from Scores
执行结果:


②其中对于SOUNDEX()解释一下,SOUNDEX是一个将任何文本串 转换为描述其语音表示的字母数字模式的算法。
select soundex(date) from Scores

select * from Scores where soundex(name) =soundex('张三')

5.日期和时间处理函数
日期和时间采用相应的数据类型存储在表中,每种DBMS都有自己的特殊形式。 日期和时间值以特殊的格式存储,以便能快速和有效地排序或过滤,并且节省物理存储空间。
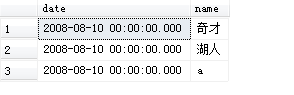
语句: select date,name from Scores where DATEPART(DD,Date)=10 --查询10号的数据
执行结果:
6.聚合函数
聚合函数是对某些行进行函数运算,并返回一个值,下图是常用的聚合函数。
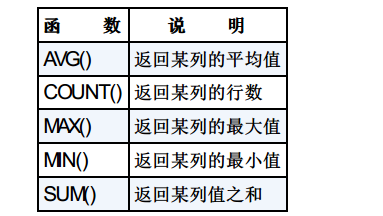
说明:①五个函数都忽略列值为NULL的行。
②使用COUNT(*)对表中行的数目进行计数,不管表列中包含的是空值(NULL)还是非空值,都会计算到总数中。
③使用COUNT(column) 对特定列中具有值的行进行计数, 忽略NULL值。
7.分组函数Group By和having
① 当需要统计球队的胜场次数时,这个时候就需要用到分组函数Group By,用到Group By之后,过滤条件就不能用where了,而要用到having。
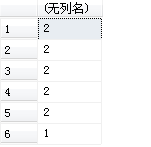
语句: select name,COUNT(*) as 场次 from Scores group by name --查询球队名和比赛场次信息
结果:

语句:select name,COUNT(*) as 场次 from Scores group by name having COUNT(*)>1 --查询球队名和比赛场次大于1场的信息
结果:

注意:分组查询中,slect的内容必须是group by的字段或聚合函数,不能是其他。例如将date字段放在select中,便出现错误。

②where和having 差别是:where过滤行, 而having过滤分组。
这里有另一种理解方法, WHERE在数据分组前进行过滤, HAVING在数据分组后进行过滤。 这是一个重要的区别, WHERE排除的行不包括在分组
中。 这可能会改变计算值, 从而影响HAVING子句中基于这些值过滤掉的分组。
语句: select name,COUNT(*) as 场次 from Scores where id<4 group by name having COUNT(*)>1 --在id小于4的数据中查询出球队名和比赛场次大于1场的信息
结果:

8.SELECT子句顺序
SQL 语句的执行顺序跟其语句的语法顺序并不一致,上图是SQL语句的语法顺序。而执行顺序确是:From----->Where----->Group By---->Having----->Select----->Order By
①From 才是 SQL 语句执行的第一步,并非 Select 。数据库在执行 SQL 语句的第一步是将数据从硬盘加载到数据缓冲区中,以便对这些数据进行操作。
② Select 是在大部分语句执行了之后才执行的,严格的说是在 From 和 Group By 之后执行的。理解这一点是非常重要的,这就是你不能在 Where中使用在 Select 中设定别名的字段作为判断条件的原因。