1.理解分类与监督学习、聚类与无监督学习。
简述分类与聚类的联系与区别。
联系:都是对数据进行分类划分处理;
区别:分类是已经有了标签的情况下把相类似的一些样本给整合起来,而聚类则是在无标签样本的情况下通过算法运算后再进行整合从而得出新的类别,总的来说他们的区别在于标签是否已经存在,机器学习以前是否已经拥有分类。
简述什么是监督学习与无监督学习。
监督学习:对有标签的样本数据进行特征选择就是监督学习,对应上面的分类;
无监督学习:对无标签的样本数据进行学习判断从而整合出不同类别就是无监督学习,对应上面的聚类。
2.朴素贝叶斯分类算法 实例
利用关于心脏病患者的临床历史数据集,建立朴素贝叶斯心脏病分类模型。
有六个分类变量(分类因子):性别,年龄、KILLP评分、饮酒、吸烟、住院天数
目标分类变量疾病:
–心梗
–不稳定性心绞痛
新的实例:–(性别=‘男’,年龄<70, KILLP=‘I',饮酒=‘是’,吸烟≈‘是”,住院天数<7)
最可能是哪个疾病?
上传手工演算过程。
|
性别 |
年龄 |
KILLP |
饮酒 |
吸烟 |
住院天数 |
疾病 |
|
|
1 |
男 |
>80 |
1 |
是 |
是 |
7-14 |
心梗 |
|
2 |
女 |
70-80 |
2 |
否 |
是 |
<7 |
心梗 |
|
3 |
女 |
70-81 |
1 |
否 |
否 |
<7 |
不稳定性心绞痛 |
|
4 |
女 |
<70 |
1 |
否 |
是 |
>14 |
心梗 |
|
5 |
男 |
70-80 |
2 |
是 |
是 |
7-14 |
心梗 |
|
6 |
女 |
>80 |
2 |
否 |
否 |
7-14 |
心梗 |
|
7 |
男 |
70-80 |
1 |
否 |
否 |
7-14 |
心梗 |
|
8 |
女 |
70-80 |
2 |
否 |
否 |
7-14 |
心梗 |
|
9 |
女 |
70-80 |
1 |
否 |
否 |
<7 |
心梗 |
|
10 |
男 |
<70 |
1 |
否 |
否 |
7-14 |
心梗 |
|
11 |
女 |
>80 |
3 |
否 |
是 |
<7 |
心梗 |
|
12 |
女 |
70-80 |
1 |
否 |
是 |
7-14 |
心梗 |
|
13 |
女 |
>80 |
3 |
否 |
是 |
7-14 |
不稳定性心绞痛 |
|
14 |
男 |
70-80 |
3 |
是 |
是 |
>14 |
不稳定性心绞痛 |
|
15 |
女 |
<70 |
3 |
否 |
否 |
<7 |
心梗 |
|
16 |
男 |
70-80 |
1 |
否 |
否 |
>14 |
心梗 |
|
17 |
男 |
<70 |
1 |
是 |
是 |
7-14 |
心梗 |
|
18 |
女 |
70-80 |
1 |
否 |
否 |
>14 |
心梗 |
|
19 |
男 |
70-80 |
2 |
否 |
否 |
7-14 |
心梗 |
|
20 |
女 |
<70 |
3 |
否 |
否 |
<7 |
不稳定性心绞痛 |
推算过程:

3.使用朴素贝叶斯模型对iris数据集进行花分类。
尝试使用3种不同类型的朴素贝叶斯:
- 高斯分布型
- 多项式型
- 伯努利型
并使用sklearn.model_selection.cross_val_score(),对各模型进行交叉验证。
代码如下:
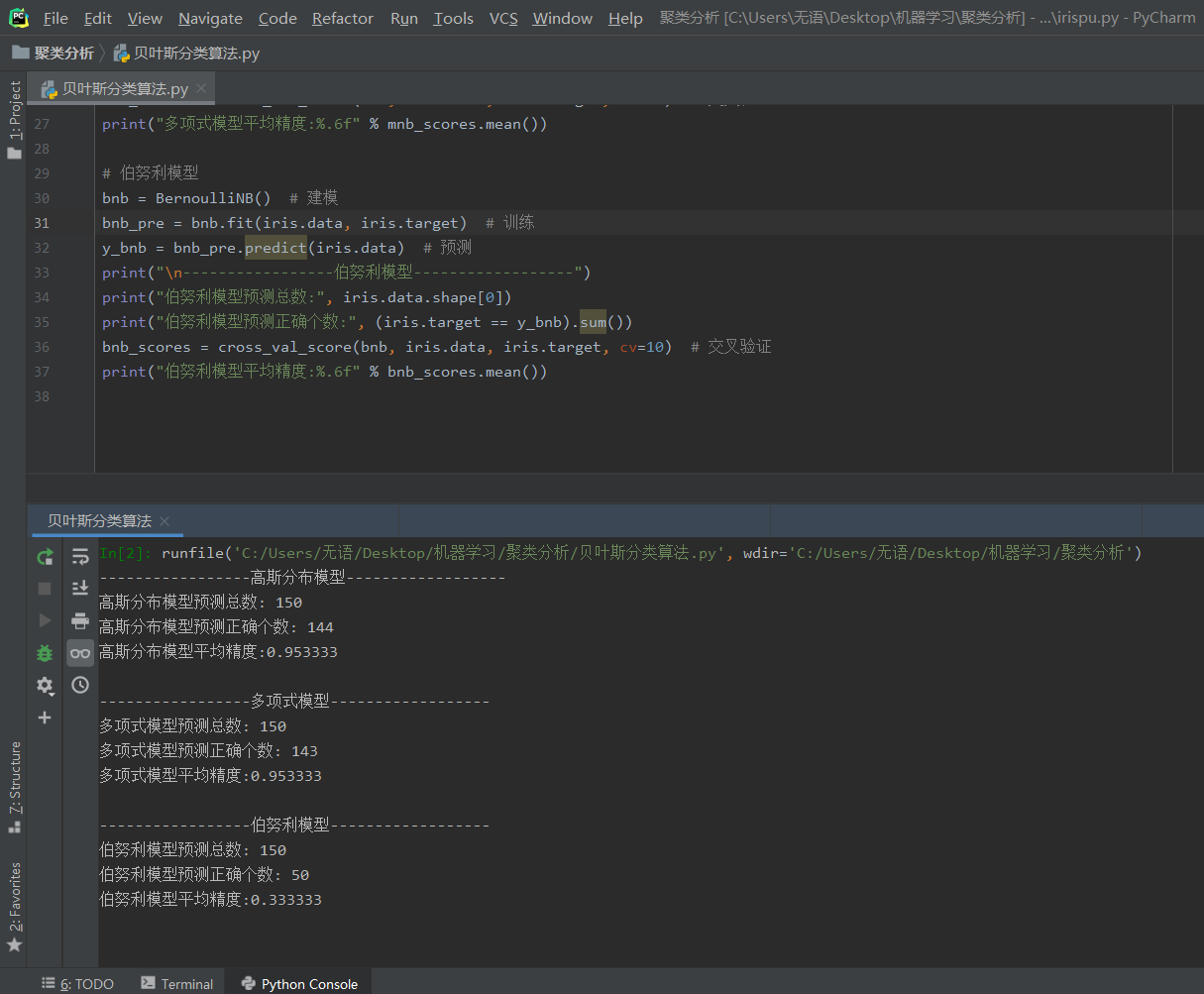
from sklearn.datasets import load_iris from sklearn.naive_bayes import GaussianNB from sklearn.naive_bayes import MultinomialNB from sklearn.naive_bayes import BernoulliNB from sklearn.model_selection import cross_val_score iris = load_iris() # 获取鸢尾花数据 # 高斯分布模型 gnb = GaussianNB() # 建模 gnb_pre = gnb.fit(iris.data, iris.target) # 训练 y_gnb = gnb_pre.predict(iris.data) # 预测 print("-----------------高斯分布模型------------------") print("高斯分布模型预测总数:", iris.data.shape[0]) print("高斯分布模型预测正确个数:", (iris.target == y_gnb).sum()) gnb_scores = cross_val_score(gnb, iris.data, iris.target, cv=10) # 交叉验证 print("高斯分布模型平均精度:%.6f" % gnb_scores.mean()) # 多项式模型 mnb = MultinomialNB() # 建模 mnb_pre = mnb.fit(iris.data, iris.target) # 训练 y_mnb = mnb_pre.predict(iris.data) # 预测 print(" -----------------多项式模型------------------") print("多项式模型预测总数:", iris.data.shape[0]) print("多项式模型预测正确个数:", (iris.target == y_mnb).sum()) mnb_scores = cross_val_score(mnb, iris.data, iris.target, cv=10) # 交叉验证 print("多项式模型平均精度:%.6f" % mnb_scores.mean()) # 伯努利模型 bnb = BernoulliNB() # 建模 bnb_pre = bnb.fit(iris.data, iris.target) # 训练 y_bnb = bnb_pre.predict(iris.data) # 预测 print(" -----------------伯努利模型------------------") print("伯努利模型预测总数:", iris.data.shape[0]) print("伯努利模型预测正确个数:", (iris.target == y_bnb).sum()) bnb_scores = cross_val_score(bnb, iris.data, iris.target, cv=10) # 交叉验证 print("伯努利模型平均精度:%.6f" % bnb_scores.mean())
运行结果图如下: