1.逻辑回归是怎么防止过拟合的?为什么正则化可以防止过拟合?(大家用自己的话介绍下)
答:正则化可以防止过拟合;因为正则化可以起到约束的作用,防止模型越变越复杂,越变越大,过拟合的出现就是因为模型的复杂度过高,而正则化的约束效果可以很好的预防过拟合。
2.用logiftic回归来进行实践操作,数据不限。
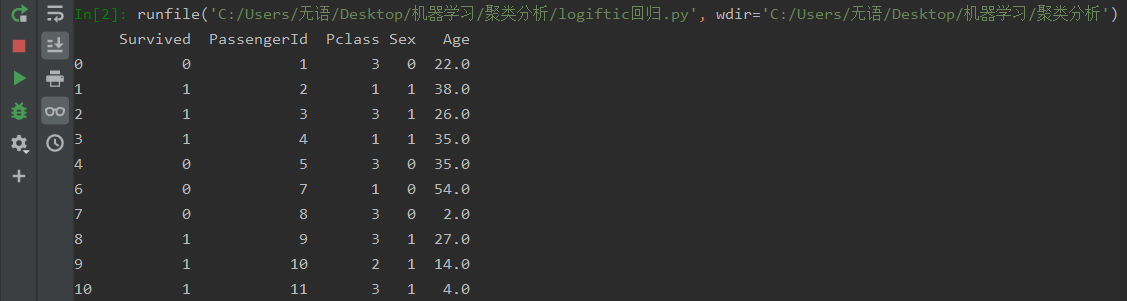
在找数据的过程中突然发现项目里面的data有以前上课使用的泰坦尼克号生还率数据,所以就直接使用该数据作为本次的实验数据了,代码如下:
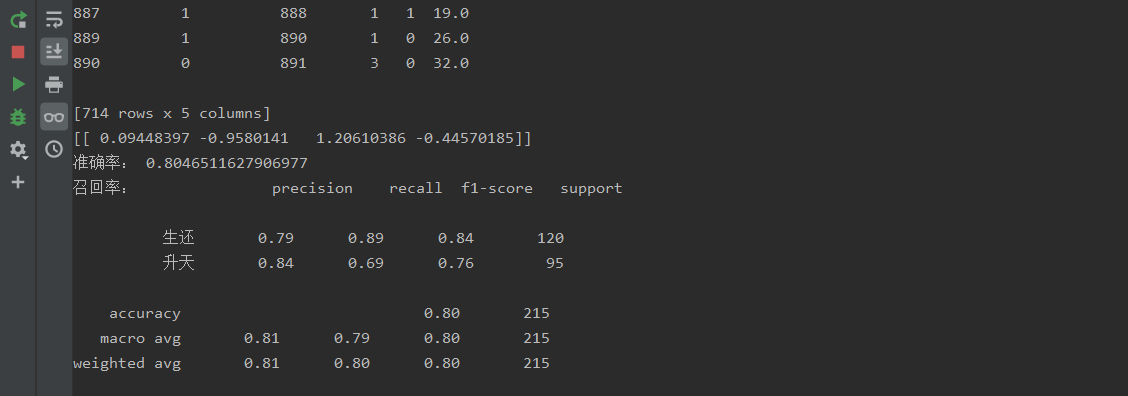
import pandas as pd from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.metrics import classification_report from sklearn.linear_model import LogisticRegression def logistic(): # 读取数据 data = pd.read_csv('./data/titanic_data.csv') # 数值型转换,性别女为0 男为1,有缺失值的行直接删除 data.loc[data['Sex'] == 'male', 'Sex'] = 0 data.loc[data['Sex'] == 'female', 'Sex'] = 1 data = data.dropna() print(data) # 数据分析 x_train, x_test, y_train, y_test = train_test_split(data.iloc[:, 1:], data.iloc[:, 0], test_size=0.3) # 特征值和目标值进行标准化处理(需要分别处理),实例标准化API std = StandardScaler() x_train = std.fit_transform(x_train) x_test = std.transform(x_test) # 逻辑回归预测 lg = LogisticRegression() lg.fit(x_train, y_train) print(lg.coef_) lg_predict = lg.predict(x_test) print('准确率:', lg.score(x_test, y_test)) print('召回率:', classification_report(y_test, lg_predict, target_names=['生还', '升天'])) if __name__ == '__main__': logistic();
运行结果图如下: