第8章 进程的切换和系统的一般执行过程
1 进程调度的时机
1.1 硬终端与软中断
进程调度的时机都与中断相关,中断有很多种,都是程序执行过程中的强制性转移,转移到操作系统内核相应的处理程序。中断在本质上都是软件或者硬件发生了某种情形而通知处理器的行为,处理器进而停止正在运行的指令流(当前进程),对这些通知做出相应反应,即转去执行定义的中断处理程序(内核代码)。
硬中断:硬中断就是CPU的两根引脚(可屏蔽中断和不可屏蔽中断)。CPU在执行每条指令后检测这两根引脚的电平,如果是高电平,说明有中断请求,CPU就会中断当前程序的执行去处理中断。一般外设都是以这种方式与CPU进行信号传递的,如时钟、键盘、硬盘等。
软中断/异常(Exception):包括除零错误、系统调用、调试断点等在CPU执行指令过程中发生的各种特殊情况统称为异常。异常会导致程序无法继续执行,而跳转到CPU预设的处理函数。
异常分为如下3种:
● 故障(Fault):故障就是没有问题了,但可以恢复到当前指令。例如除0错误、缺页中断等。
● 退出(Abort):简单说是不可恢复的严重故障,导致程序无法继续运行,只能退出了。例如连续发生故障(double fault)。
● 陷阱(Trap):程序主动产生的异常,在执行当前指令后发生。例如系统调用(int 0x80)以及调试程序时设置断点的指令(int 3)都属于这类。
1.2 进程调度时机
Linux 内核通过 schedule 函数实现进程调度,schedule 函数在运行队列中找到一个进程,把CPU分配给它。所以调用 schedule 函数一次就是调度一次,调用 schedule 函数的时候就是进程调度的时机。
一般来说,CPU 在任何时刻都处于以下3种情况之一。
● 运行于用户空间,执行用户进程上下文。
● 运行于内核空间,处于进程(一般是内核线程)上下文。
● 运行于内核空间,处于中断(中断处理程序ISR,包括系统调用处理过程)上下文。
中断上下文代表当前进程执行,所以中断上下文中的 get_current 可获取一个指向当前进程的指针,是指向被中断进程或即将运行的就绪进程的,相应的硬件上下文件切换信息也存储于该进程的内核堆栈中。由于中断的级别不同,有不可屏蔽中断、可屏蔽中断、陷阱(系统调用)、异常等。为了整个系统的运行效率,中断上下文中调用其他内核代码有一定的限制。
内核线程以进程上下文的形式运行在内核空间中,本质上还是进程,但它有调用内核代码的权限,比如主动调用schedule() 函数让出CPU等。
进程调度时机如下:
● 用户进程通过特定的系统调用主动让出CPU。
● 中断处理程序在内核返回用户态时进行调度。
● 内核线程主动调用 schedule 函数让出CPU。
● 中断处理程序主动调用 schedule 函数让出CPU,涵盖以上第一种和第二种情况。
用户态进程只能被动调度,无法实现主动调度,仅能通过陷入内核态的某个时机点进行调度,即在中断处理过程中进行调度。内核线程可主动,也可被动调度。
Linux内核中没有操作系统原理中定义的线程概念。从内核的角度看,不管是进程还是内核线程都对应一个task_struct 数据结构,本质上都是线程。Linux 系统在用户态实现的线程库pthread 是通过在内核中多个进程共享一个地址空间实现的。
2 调度策略与算法
调度算法就是从就绪队列中选一个进程,一般来说就是挑最重要、最需要(最着急)、等了最长时间的(排队)等,和人类排队抢资源很相似。
2.1 进程的分类
这里选取两种和调度相关的分类方式。
进程的分类 1:
● I/O消耗型进程。典型的像需要大量文件读写操作的或网络读写操作的,如文件服务器的服务进程。这种进程的特点就是CPU负载不高,大量时间都在等待读写数据。
● 处理器消耗型进程。典型的像视频编码转换、加解密算法等。这种进程的特点就是CPU占用率为100%,但没有太多硬件进行读写操作。
进程的分类 2:
● 交互式进程。此类进程有大量的人机交互,因此进程不断地处于睡眠状态,等待用户输入,典型的应用比如编辑器VIM。此类进程对系统响应时间要求比较高,否则用户会感觉系统反应迟缓。
● 批处理进程。此类进程不需要人机交互,在后台运行,需要占用大量的系统资源,但是能够忍受响应延迟,比如编译器。
● 实时进程。实时进程对调度延迟的要求最高,这些进程往往执行非常重要的操作,要求立即响应并执行。
根据进程的不同分类,Linux 采用不同的调度策略。当前Linux系统的解决方案是,对于实时进程,Linux 采用FIFO(先进先出)或者Round Robin(时间片轮转)的调度策略。对其他进程,当前Linux采用CFS(Completely Fair Scheduler)调度器,核心思想是“完全公平”。
2.2 调度策略
Linux 系统中的几种调度策略为SCHED_NORMAL、SCHED_FIFO、SCHED_RR。其中SCHED_NORMAL 是用于普通进程的调度类,而SCHED_FIFO 和SCHED_RR 是用于实时进程的调度类,优先级高于SCHED_NORMAL。内核中根据进程的优先级来区分普通进程与实时进程,Linux内核进程优先级为0~139,数值越高,优先级越低,0为最高优先级。实时进程的优先级取值为0~99;而普通进程只具有nice 值,nice 值映射到优先级为100~139。子进程会继承父进程的优先级。
SCHED_FIFO 和 SCHED_RR
实时进程的优先级是静态设定的,而且始终大于普通进程的优先级。因此只有当就绪队列中没有实时进程的情况下,普通进程才能够获得调度。实时进程采用两种调度策略:SCHED_FIFO 和 SCHED_RR。SCHED_FIFO采用先进先出的策略,对于所有相同优先级的进程,最先进入就绪队列的进程总能优先获得调度,直到其主动放弃CPU。SCHED_RR 采用更加公平的轮转策略,比FIFO 多一个时间片,使得相同优先级的实时进程能够轮流获得调度,每次运行一个时间片。
SCHED_NORMAL
Linux-2.6 之后的内核版本中,SCHED_NORMAL 使用的是Linux-2.6.23 版本内核中引入的CFS 调度管理程序。每个进程能够分配到的CPU 时间占有比例跟系统当前的负载(所有处于运行态的进程数以及各进程的优先级)有关,同一个进程在本身优先级不变的情况下分到CPU 时间占比会根据系统负载变化而发生变化,即与时间片没有一个固定的对应关系。
CFS 算法对交互式进程的响应较好,由于交互式进程基本处于等待事件的阻塞态中,执行的时间很少,而计算类进程在执行的时间会比较长。如果计算类进程正在执行时,交互式进程等待的事件发生了,CFS就会判断出交互式进程在之前时间段内执行的时间很少,因此系统总是能及时响应交互式进程。
2.3 CFS调度算法
CFS即为完全公平调度算法,其基本原理是基于权重的动态优先级调度算法。每个进程使用CPU的顺序由进程已使用的CPU虚拟时间(vruntime)决定,已使用的虚拟时间越少,进程排序就越靠前,进程再次被调度执行的概率也就越高。每个进程每次占用CPU 后能够执行的时间(ideal_runtime)由进程的权重决定,并且保证在每个时间周期(_sched_period)内运行队列里的所有进程都能够至少被调度执行一次。
3 进程上下文切换
3.1 进程执行环境的切换
为了控制进程的执行,内核必须有能力挂起正在CPU 中运行的进程,并恢复执行以前挂起的某个进程。这种行为被称为进程切换,任务切换或进程上下文切换。
进程上下文包含了进程执行需要的所有信息。
● 用户地址空间:包括程序代码、数据、用户堆栈等。
● 控制信息:进程描述符、内核堆栈等。
● 硬件上下文,相关寄存器的值。
进程切换就是变更进程上下文,最核心的是几个关键寄存器的保存与变换。
● CR3 寄存器代表进程页目录表,即地址空间、数据。
● ESP寄存器(内核态时)代表进程内核堆栈(保存函数调用历史),struct thread、进程控制块、内核堆栈存储于连续8KB 区域中,通过ESP获取地址。
● EIP寄存器及其他寄存器代表进程硬件上下文,即要执行的下条指令(代码)及环境。
这些寄存器从一个进程的状态切换到另一个进程的状态,进程切换就算完成了。
在实际代码中,每个进程切换基本由两个步骤组成:
● 切换页全局目录(CR3)以安装一个新的地址空间,这样不同进程的虚拟地址如0x8048400 就会经过不同的页表转换为不同的物理地址。
● 切换内核态堆栈和硬件上下文,因为硬件上下文提供了内核执行新进程所需要的所有信息,包含CPU 寄存器状态。
3.2 核心代码分析
schedule() 函数选择一个新的进程来运行,并调用 context_switch 进行上下文的切换。context_switch 首先调用 switch_mm 切换CR3,然后调用宏 switch_to 来进行硬件上下文切换。context_switch 部分关键代码及分析摘录如下。
地址空间切换:
地址空间切换的关键代码在load_cr3 ,将下一进程的页表地址装入CR3。从这里开始,所有虚拟地址转换都使用 next 进程的页表项。当然因为所有进程对内核地址空间是相同的,所以在内核态时,使用任意进程的页表转换的内核地址都是相同的。
static inline void context_switch(struct rq *rq,struct task_struct *prev, struct task_struct *next)
{
...
if (unlikely(!mm)) { /* 如果被切换进来的进程的mm为空切换,内核线程mm为空 */
next->active_mm = oldmm; /* 将共享切换出去进程的active_mm */
atomic_inc(&oldmm->mm_count); /* 有一个进程共享,所有引用计数加一 */
/* 将per cpu变量cpu_tlbstate状态设为LAZY */
enter_lazy_tlb(oldmm, next);
} else /* 普通mm不为空,则调用switch_mm切换地址空间 */
switch_mm(oldmm, mm, next) ;
...
/* 这里切换寄存器状态和栈 */
switch_to(prev, next, prev) ;
...
static inline void switch_mm(struct mm_struct *prev, struct mm_struct *next, struct task_struct *tsk)
{
...
if (!cpumask_test_and_set_cpu(cpu, mm_cpumask(next))) {
load_cr3(next->pgd); //地址空间切换
load_LDT_nolock(&next->context);
}
}
#endif
堆栈及硬件上下文:
该部分是内联汇编代码,如下所示:
pushf1
push %ebp // s0 准备工作
prev->thread.sp=%esp //s1
%esp=next->thread.sp //s2
prev->thread.ip=$1f //s3
push next->thread.ip //s4
jmp _switch_to //s5
1f:
popl %%ebp //s6,与s0对称
popf1
进程切换关键环节如下图所示:
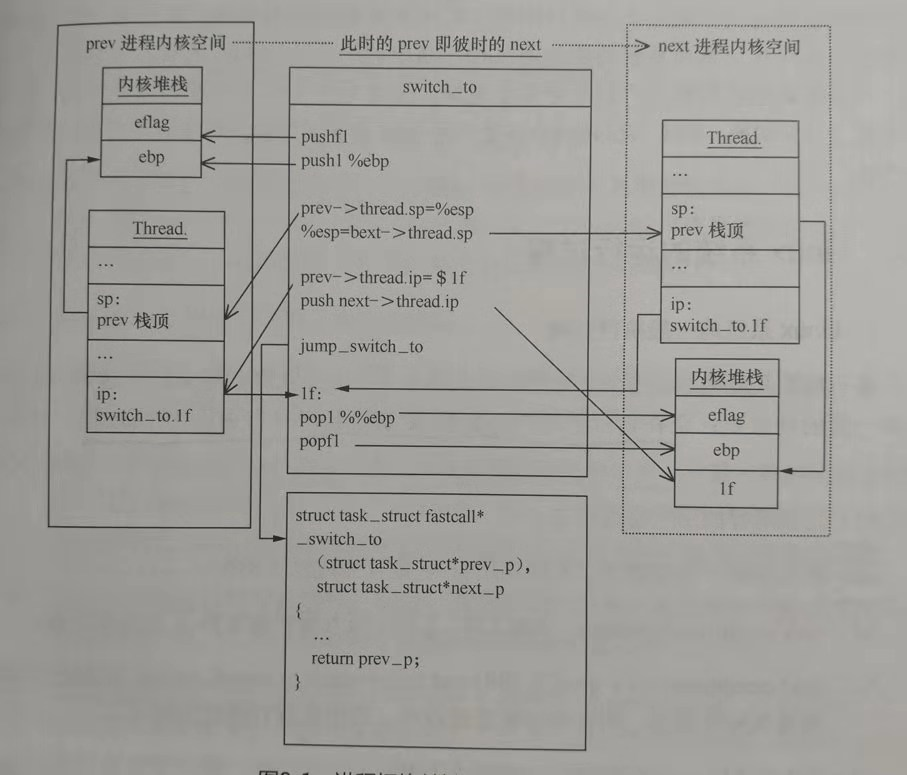
从伪代码中可以看出,s0 两句在prev 的堆栈中压入了EFLAG 和 EBP寄存器。
(1)s1将当前的ESP寄存器保存到prev->thread.sp 中。
(2)s2将ESP寄存器替换为 next->thread.sp。
(3)s3保存$1f 这个位置对应的内存地址到 prev->thread.ip。
(4)s4在堆栈上压了$1f 这个地址,此刻是next 进程的堆栈。
(5)s5是一条jmp,跳转到一个 c 函数_switch_to。
(6)s6,当到达此处就说明是一个相当正常的下一进程在运行了,对称地把 s0 压得数据弹出。
接下来的部分就要靠对函数调用堆栈的理解了,其实堆栈存储了进程所有的函数调用历史,所以剩下的只要顺着堆栈返回上一级函数即可。由于_switch_to 是被schedule() 函数调用的,而schedule() 函数又在其他系统调用函数中被调用,比如sys_exit() 中,所以先返回到next 进程上次切换让出 CPU 时的schedule() 函数中,然后返回到调用 schedule() 的系统调用处理过程中,而系统调用又是在用户空间通过int 0x80触发的,所以通过中断上下文返回到系统调用被触发的地方,接着执行用户空间的代码。这样就回到了next进程的用户空间代码。
进程上下文切换时需要保存要切换你进程的相关信息(如 thread.sp 与 thread.ip),这时中断上下文的切换是不同的。中断是在一个进程当中从进程的用户态到进程的内核态,或从进程的内核态返回到进程的用户态,而切换进程需要在不同的进程间切换。
4 Linux系统的运行过程
Linux 系统的一般执行过程
(1)正在运行的用户态进程X。
(2)发生中断(包括异常、系统调用等),硬件完成以下动作。
● save cs:eip/ss:esp/eflags:当前CPU上下文压入用户态进程x的内核堆栈。
● load cs:eip(entry of a specific ISR)and ss:eip(point to kernel stack); 加载当前进程内核堆栈相关信息,跳转到中断处理程序,即中断执行路径的起点。
(3)SAVE_ALL保存现场, 此时完成了中断上下文切换,即从进程X的用户态到进程X的内核态。
(4)中断处理过程中或中断返回前调用了schedule 函数,其中的switch_to 做了关键的进程上下文切换。将当前用户进程X的内核堆栈切换到选出的next进程(本例假定为进程Y)的内核堆栈,并完成了进程上下文所需的EIP等寄存器状态切换。
(5)标号1,即上述代码第50行“1: ”(地址为swich_to中的“$1f"),之后开始运行用户态进程Y(这里Y曾经通过以上步骤被切换出去,因此可以从标号1继续执行)。
(6) restore_al,恢复现场,与(3)中保存现场相对应。
(7)iret - pop cs:eip/ss:esp/eflags,从Y进程的内核堆找中弹出(2)中硬件完成的压栈内容。此时完成了中断上下文的切换,即从进程Y的内核态返回到进程Y的用户态。
(8)继续运行用户态进程Y。
如上过程在Linux系统中反复执行,其中的关键点如下:
● 中断和中断返回有CPU硬件上下文的切换。
● 进程调度过程中有进程上下文的切换,而进程上下文的切换包括:从一个进程的地址空间切换到另一个进程的地址空间;从一个进程的内核堆栈切换到另一个进程的内核堆栈;还有诸如EIP寄存器等寄存器状态的切换。
Linux 系统执行过程中的几种特殊情况:
● 通过中断处理过程中的调度时机,内核线程之间互相切换。比如两个内核线程之间切换,CS段寄存器没有发生变化,没有用户态和内核态的切换。
● 用户进程向内核线程的切换。内核现场不需要从内核态返回到用户态,也就是说省略了恢复现场和iret恢复CPU上下文。
● 内核线程向用户进程的切换。内核线程主动调用schedule函数,只有进程上下文的切换,不需要发生中断和保存现场。它比最一般的情况更简略,但用户进程从内核态返回到用户态时依然需要恢复现场和iret恢复CPU上下文。
● 创建子进程的系统调用在子进程中的执行起点及返回用户态的过程较为特殊。如fork一个子进程时,子进程不是从switch_to 中的标号1开始执行的,而是从ret_from_fork 开始执行的,在源代码中可以找到语句“next ip =ret from fork"。
● 加载一个新的可执行程序后返回到用户态的情况也较为特殊。比如execve系统调用加载新的可执行程序,在 execve系统调用处理过程中修改了中断上下文,即在execve系统调用内核处理函数内部修改了中断保存现场的内容,也就是返回到用户态的起点为新程序的elf_entry或者ld动态连接器的起点地址。
5 Linux系统构架与执行过程概览
任何计算机系统都包含一个基本的程序集合,称为操作系统。操作系统是一个集合,即包含用户态也包含内核态的组件,Linux操作系统的整体构架如下图所示:

图中中间为内核实现,内核向上为用户提供系统调用接口,向下调用硬件服务接口。其自身实现了进程管理等功能,在内核外还提供了如系统命令、编译器、解释器、函数库等基础设施。对底层来说,与硬件交互管理所有的硬件资源。对上层来说,为用户程序(应用程序)提供一个良好的执行环境。
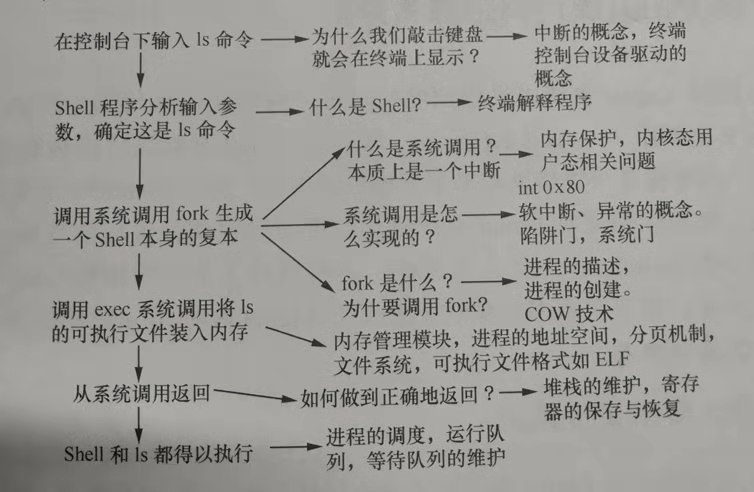
接下来,将以ls命令的执行过程来分析整个系统的运行。当用户输入ls并按回车键后,在Linux操作系统中发生的如下图所示:
6 进程调度相关源代码跟踪和分析
6.1 配置运行MenuOS系统
6.2 配置 gdb 远程调试和设置断点
6.3 使用 gdb 跟踪分析schedule()函数
在调试模式下重新运行 MenuOS 系统可以看到 MenuOS 运行到 schedule 函数停下来,如下图所示:

schedule 函数的作用非常重要,是进程调度的主体函数。其中 pick_next_task 函数是schedule 函数中重要的函数,负责根据调度策略和调度算法选择下一个进程,pick_next_task 函数断点截图如下所示:
context_switch 函数是schedule 函数中实现进程切换的函数,context_switch 函数断点截图如下图所示:

由于switch_to 内部是内嵌汇编代码,无法跟踪调试。