http://www.cnblogs.com/Jusfr/p/5256791.html
事件总线(EventBus)及其演进过程必须提到内存模型、传统的队列模型、发布-订阅模型。
- 内存模型:进程内模型,事件总线(EventBus)在内部遍历消费者(Consumer)列表传递数据;
- 队列模型:消息或事件持久化到传统消息队列(Queue)即返回,以实时性降低换取吞吐能力提升;
- 发布-订阅模型:事件源(EventSource)得到强化,出现如分布式、持久化、消费复制/分区等特性;
文中使用了“术语(单词)”的形式引入概念,用词可能有差异,只是力求表义清楚,下文描述将直接使用单词。
内存模型
内存模型可以很好地解耦,举例来说,版本初期我们有 IUserService 负责用户创建,逻辑如下:
interface IUserService {
void CreateNewUser(String name);
}
class UserService1 : IUserService {
public void CreateNewUser(String name) {
Console.WriteLine("User "{0}" created", name);
}
}现在希望在用户创建后,进行一次消息服务调用,发送欢迎辞。为了解决这个需求,需要添加和实现新的 MessageService , 并添加依赖,在 CreateNewUser() 方法某入插入调用逻辑,于是代码变这样:
interface IMessageService {
void NotifyWelcome(User user);
}
class UserService2 : IUserService {
private readonly IMessageService _messageService;
public UserService2(IMessageService messageService) {
_messageService = messageService;
}
public void CreateNewUser(String name) {
var user = new User { Name = name };
Console.WriteLine("User "{0}" created", user.Name);
_messageService.NotifyWelcome(user); //添加消息服务调用
}
}目前看起来好像没啥问题,因为代码简单,但是当逻辑越来越复杂时情况就变得不一样了,比如我们希望用户创建后将数据写入索引,需要依赖 ISearchService;比如希望调用报表服务 IReportService 添加每日新增用户数;
public void CreateNewUser(String name) {
var user = new User { Name = name };
Console.WriteLine("User "{0}" created", user.Name);
_messageService.NotifyWelcome(user); //添加消息服务调用
_searchService.SaveIndex(user) //添加搜索服务调用
_reportService.CounterNewUser(user); //添加报表服务调用;
}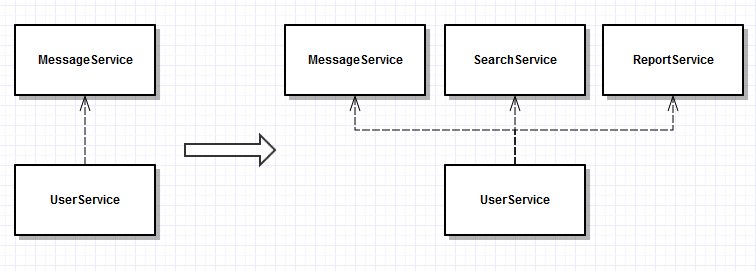
如此多的依赖实在时重负难堪,当然你可以说这些应该异步处理、应该放到后端队列,没错。现实中需要同步处理的逻辑并不少见,而规模尚小时引入队列将带来额外的开发测试、部署监控成本。使用 EventBus 的内存模型可以比较优雅地处理此问题,以下是实现思路。
场景和实现思路
引入 EventBus 作为共同依赖,IUserService 视为生产者,IMessageService 视为对用户创建事件感兴趣的 Consumer ,其消费逻辑调用 NotifyWelcome() 方法。EventBus 内部维护了一份 EventType-Consumer 列表,遍历列表分发 Event 实例;ISearchService 、IReportService 等类似,同样注册到 EventBus 内即可。
abstract class Event {
}
interface IConsumer {
void Proceed(Event @event);
}
class EventBus {
private readonly HashSet<IConsumer> _consumers = new HashSet<IConsumer>();
//... 更多细节
public void Publish(Event @event) {
foreach (var consumer in _consumers) {
consumer.Proceed(@event);
}
}
}
class UserService3 : IUserService {
private readonly EventBus _eventBus;
public UserService3(EventBus eventBus) {
_eventBus = eventBus;
}
public void CreateNewUser(String name) {
var user = new User { Name = name };
Console.WriteLine("User "{0}" created", user.Name);
var @event = ... //创建消息
_eventBus.Publish(@event); //交由 EventBus 发布
}
}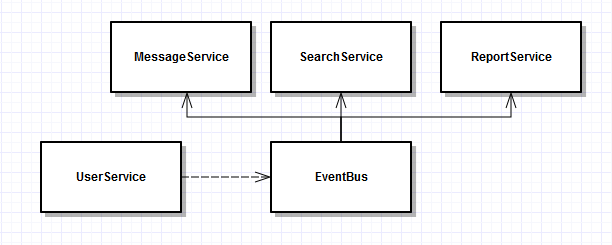
在此过程中,Consumer 并不知道谁创建了 Event,不同的 Producer 对各 Consumer 的依赖统一变更为对 EventBus 的依赖,内存模型达到了解耦目的。
队列模型
在内存模型的场景中,我们确认这些业务需要由异步进程处理。从 MSMQ 到各种第3方实现方案众多,但真实业务中 while(true) 循环有太多问题,比较棘手的像
- 异常处理:消息处理中发生异常,但短时间内重试可能解决不了问题;
- 多消费者:大家都有消费程序,可能监听相同队列;
对于异常,常规做法是使用监听时间依次延长的多个异常队列,定时检查并出队处理;
多消费者麻烦一点,由于传统队列出队即消息的特性,这意味着要么数据写多份大家各自消费,要么消费者集中管理遍历调用。
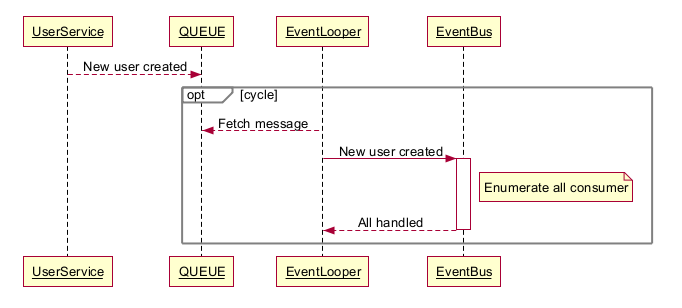
- 异常队列谁来监听和分发?
- 如果数据写多份,生产者如何得知消费者数量?写入性能损失怎样?动态添加消费者时怎么办?消费者又如何路由到自己的队列上?
- 如果数据写一份,消费者同步调用还是异步调用?等待所有的消费逻辑完成既可能存在短板,某消费者出现异常时又如何进行进度区分?
发布-订阅模型及各 EventSource 的诸多特性提供了解决思路。
发布-订阅模型
本文是 Kafka 系列文章之一,故使用 Kafka 作为 EventSource 描述和参考,其他队列并未过多涉及请有限参考。
队列模型虽然存在许多问题,但应用与业务规模并不庞大时仍可一用。我们可以使用宿主代为监听列队和消息分发、插件式寄宿消费程序,使消费者可以专注于业务;由于消费者短板效应无法避免,可以在业务层面妥协,尽量聚合高效、有限的消费者等等。
在应用与业务继续扩展时,发布订阅模型的事件总线变得不可或缺,甚至流式处理框架也不可避免地提上日程,使用 Kafka 对前文问题作出解答。
- Kafka 基于文件系统,消息移除是基于时间和磁盘的策略,并不会轻易丢失数据,消费者出现异常也不用担心;
- Kafka 将 Consumer 的当前位置的管理职责交由消费者负责,只是提供了可选的 OffsetCommit 和 OffsetFetch API,这带来了极大的便利性和一定的复杂度;你可以从任何位置开始消费,也没有重复消费限制,附加的是需要合适的 Offset 策略;
- Kafka 提供了 Topic Partition + Consumer Group 并定义了发布-订阅语义,可以配合堵塞式 API 保障消息处理的低延迟。
关于推与拉
Kafka 遵循传统的 Pull 模式,由消费者决定数据流速,毕竟写入速率远高于消费的情况下,消费者实际是处于过载状态。个人的理解的推拉(Push/Pull 或 Publish/Subscribe)并不是主要差异而只是受制于事件源(EventSource)的实现细节。
关于 Chuye.Kafka
Chuye.Kafka 是 Kafka 0.9版本 API 的 .NET 实现,其 Consumer、Producer 是 low levl API 的轻度封装,使用它实现 EventBus 并没有过多障碍,消费者分组管理、状态监控和异常策略才是重点。