我的rbac组件,是想用到任何一个,项目中的。 so 问题来了。
- 问题: 拿到一个项目。 怎样获取到,当前项目中, 所有的URL 以及 每个URL的别名name, 还有是有 namespace 命名空间。
- 实现思路:
1. 先要确定我们 根级 路由在哪里。 就是和项目文件同名的包中, 的 urls.py 中的 urlpatterns=[....] 这个路由的位置在我们的settings中是有进行配置的
ROOT_URLCONF = 'learn_formset.urls' 当然这个是可以进行修改的。
那个怎么才能获得,这个 urlpatterns 列表中的所有的对象呢?
直接导入的话,也是可以的。 但是更好的是 通过settings 中 ROOT_URLCONF 的字符串来进行导入。
Django中有一个模块就是来做这件事的, from django.utils.module_loading import import_string 这个模块就是用来根据一个字符串来导入相应的模块。
他的返回值,就是一个模块对象 <class 'module'> 。 可以通过 点 语法。获取到其中的 urlpatterns 列表。
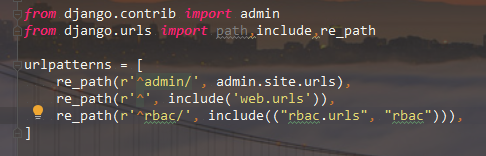
看一看,打印 urlpatterns 里面的没一个数据, 能得到啥:


from django.conf import settings from django.utils.module_loading import import_string def get_all_url_dict(): ''' 递归获取项目中,所有的url 保存到字典 :return: ''' md = import_string(settings.ROOT_URLCONF) # <class 'module'> for item in md.urlpatterns: print(item) # <URLResolver <URLPattern list> (admin:admin) '^admin/'> # <URLResolver <module 'web.urls' from 'D:\crm_learn\web\urls.py'> (None:None) '^'> # <URLResolver <module 'rbac.urls' from 'D:\crm_learn\rbac\urls.py'> (rbac:rbac) '^rbac/'> def multi_permissions(request): ''' 批量操作权限 :param request: :return: ''' # 获取项目中,所有的URL get_all_url_dict() return HttpResponse("OK")
可以看到的是,每一个item 都是一个 URLResolver 对象。这表示这是一个 路由分发的url。
但是 还有一种是 对应的视图函数的。URLPattern 对象。表示他对应的是一个 视图函数。
看代码吧! 这是 Django 2.0 版本的。 和 1 版本有不小的改动。
from collections import OrderedDict from django.conf import settings from django.utils.module_loading import import_string from django.urls.resolvers import URLResolver, URLPattern def check_url_exclude(url): '''自定制,过滤一下。 以 xxx 为前缀的 url''' exclude_url = [ "/admin/.*", "/login/", ] for regex in exclude_url: if re.match(regex, url): return True def recursion_urls(pre_namespace, pre_url, urlpatterns, url_ordered_dict): ''' 递归获取,所有的url :param pre_namespace: namespace前缀,用于拼接name (namespace:name) :param pre_url: url的前缀, 用于拼接url :param urlpatterns: 路由关系列表 :param url_ordered_dict: 用于保存递归中获取的所有的路由 :return: ''' for item in urlpatterns: if isinstance(item, URLPattern): # 表示一个 非路由分发。将路由添加到字典中 if not item.name: # 判断这个url 有没有,name别名 continue
name = item.name if pre_namespace: # 判断当前这个url是不是有namespace前缀。也就是:是否是某一个命名空间中的 name别名 name = "%s:%s" % (pre_namespace, item.name) url = (pre_url + str(item.pattern)).replace("^", "").replace("$", "") if check_url_exclude(url): # 在这里进行自定制的过滤。 过露出我不想要的 哪些url continue url_ordered_dict[name] = {"name": name, "url": url} elif isinstance(item, URLResolver): # 表示这是一个路由分发。 这里就需要递归了
namespace = pre_namespace if pre_namespace: # 如果有前缀 if item.namespace: # 自己有没有namespace namespace = "%s:%s" % (pre_namespace, item.namespace)# 把之前的pre_namespace 和当前的 item.namespace 拼接。 传给下一次的递归函数。继续进行拼接 else: if item.namespace: namespace = item.namespace recursion_urls(namespace, pre_url + str(item.pattern), item.url_patterns, url_ordered_dict) # 进入下一次循环之前,pre_url + str(item.pattern) 要拼接上这一次循环的 url。 # item.url_patterns这一次是 URLResolver 对象的 url_patterns。 中间要加一个 _ 烦得很。 第一次是通过导入拿到的 模块对象。 # 但是 递归中的不是 模块对象。是一个URLResolver对象。 所以要加一个 _ 。下划线 def get_all_url_dict(): ''' 获取项目中,所有的url 保存到字典(前提是,每个url必须有name别名) :return: ''' url_ordered_dict = OrderedDict() md = import_string(settings.ROOT_URLCONF) recursion_urls(None, "/", md.urlpatterns, url_ordered_dict) # 递归的去获取所有的路由。 # 第一次循环时,肯定是从 根路由开始, 所以没有前缀 传一个None. # "/" 也是因为,第一次循环时。 所有的url 都没有前导 的 "/" 手动的加上。 # md.urlpatterns 要循环的这个列表。 # url_ordered_dict 保存所有url 的字典。 return url_ordered_dict def multi_permissions(request): ''' 批量操作权限 :param request: :return: ''' # 获取项目中,所有的URL all_url_dict = get_all_url_dict() print(all_url_dict) return HttpResponse("OK")
这里是1.0版本的。 主要是,几个关键的参数获取的位置上。 有些不同!
from collections import OrderedDict from django.conf import settings from django.utils.module_loading import import_string from django.urls.resolvers import RegexURLResolver, RegexURLPattern def recursion_urls(pre_namespace, pre_url, urlpatterns, url_ordered_dict): for item in urlpatterns: if isinstance(item, RegexURLPattern): # 表示一个 非路由分发。将路由添加到字典中 if not item.name: # 判断这个url 有没有,name别名 continue if pre_namespace: # 判断当前这个url是不是有namespace前缀。如果有就说明是通过路由分发过来的, # 就要加上, 他上级的名称空间 name = "%s:%s" % (pre_namespace, item.name) else: name = item.name url = pre_url + str(item._regex) url_ordered_dict[name] = {"name": name, "url": url.replace("^", "").replace("$", "")} elif isinstance(item, RegexURLResolver): # 表示这是一个路由分发。 这里就需要递归了 if pre_namespace: # 如果有前缀 if item.namespace: # 自己有没有namespace namespace = "%s:%s" % (pre_namespace, item.namespace) else: namespace = pre_namespace # 把之前的pre_namespace 和当前的 item.namespace 拼接。 传给下一次的递归函数。继续进行拼接 else: if item.namespace: namespace = item.namespace else: namespace = None recursion_urls(namespace, pre_url + str(item._regex.pattern), item.url_patterns, url_ordered_dict) def get_all_url_dict(): url_ordered_dict = OrderedDict() md = import_string(settings.ROOT_URLCONF) recursion_urls(None, "/", md.urlpatterns, url_ordered_dict) return url_ordered_dict def multi_permissions(request): # 获取项目中,所有的URL all_url_dict = get_all_url_dict() print(all_url_dict) return HttpResponse("OK")
我的这个, 中间做了一个限制, 就是 必须要确保每一个。 url 必须要有一个别名。 没有别名的就直接跳过了。
因为,如果使用我的rbac 组件 我需要这个别名, 进行按钮粒度的控制。 必须要有。
但是我没有让他报错, 因为还是有一些,是不需要起别名的。
然后就是把它放到,一个固定的地方了。 放到rbac这个app 哪里都行。 用的时候就导入 get_all_url_dict() 就行了