第四章 建议学习时间2小时 课程共10章
学习方式:详细阅读,并手动实现相关代码
学习目标:此教程将教会大家 安装Node、搭建服务器、express、mysql、mongodb、编写后台业务逻辑、编写接口,最后完成一个完整的项目后台,预计共10天课程。
node.js事件机制
node.js是单线程,但是通过事件和回调支持并发,可以实现非常高的性能。
node.js所有的API都是通过异步调用。第一堂课的时候,我们写过一个同步和异步的示例(如下),当初说到:同步代码先执行完成,然后才执行异步代码。
setTimeout(function(){ console.log(1000000000); },0); for(var i=0; i<1000; i++){ console.log(i); }
而对于异步的多个代码,它们的执行顺序是怎样的呢?试试下面的代码:
今天的代码我们放到一个新的文件夹 中,为了完成下面的文件读取,我们需要提前准备一个a.txt的文件(注意:文件格式最好是uft-8)
main.js中写入如下代码:
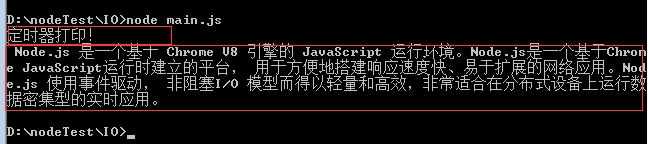
var fs = require("fs"); //node 内置模块可直接引入 fs:文件系统操作模块 fs.readFile("./a.txt","utf-8",function(err,data){ //读取文件 if(err) throw err; console.log(data); }); setTimeout(function(){ console.log("定时器打印!"); },0);
使用 node 运行 main.js后,你会发现定时器的先打印,(增加定时器的触发时间,你会发现,打印的顺序会改变。)
具体的异步代码执行顺序,是由node.js内部机制控制的,我们很难准确预知。这里给大家介绍一下node.js的事件模型:
Node.js 使用事件驱动模型,当web server接收到请求,就把它关闭然后进行处理,然后去服务下一个web请求。
当这个请求完成,它被放回处理队列,当到达队列开头,这个结果被返回给用户。
这个模型非常高效可扩展性非常强,因为webserver一直接受请求而不等待任何读写操作。(这也被称之为非阻塞式IO或者事件驱动IO)
在事件驱动模型中,会生成一个主循环来监听事件,当检测到事件时触发回调函数。

回调函数
回调函数就是将一个函数作为另一个函数的参数传入,作为另一个函数内部执行的函数。
我们上面示例中的文件读取方法中,第三个参数是一个回调函数,当文件读取完成,就会自动调用这个函数。
fs.readFile("./a.txt","utf-8",function(err,data){ //读取文件
if(err) throw err;
console.log(data);
});
上面的回调是封装好的,那么我们自己来写一个回调函数的实现样子:
创建 一个js文件,写入如下代码:

function fn01(data,callback){ if(data){ callback("",data); }else{ var err = new Error("错误了"); callback(err) } } fn01("aa",function(err,data){ if(err){ console.log("错误"+err); }else{ console.log(data); } })
上面代码是回调函数的标准模型,我们在调用 fn01的时候,传入了两个参数,第一个是字符串,第二个是一个回调函数,当参数传入以后。我们来看fn01的主方法,方法中检测第一个参数的存在情况来,然后执行callback方法,也就是执行了当参数传入的那个方法。
异步IO操作
我们前面讲的文件读取的方式是一次性全部读取,当文件过大的时候,一次性读取不仅缓慢,而且影响用户体验,那么怎么实现分步读取呢,
这就得使用到异步IO的操作,像水流一样流出一段取得一段。
具体实现:
我们创建一个文件读取流,先上代码
var fs = require("fs"); var data = ""; //声明一个空字符串来存读取的数据 var rs = fs.createReadStream("a.txt"); rs.setEncoding("utf-8"); //监听当有数据流入的时候 rs.on("data",function(chunc){ data += chunc; //将读取的数据拼接到data上。 console.log("..."); //读的过程中,我们打印三个点。 }); rs.on("end",function(){ console.log("没有数据了") });
我们将 a.txt中的内容增加,以让读取时间变长,
代码中,创建main3.js写入上面的代码,使用 reateReadStream创建读取流对象,在对象上使用on监听“data”读取数据的事件,每读取一段数据,就会触发这个事件,当读取完毕, 就会触发“end”事件。
执行main3.js,我们就可以看到下面打印的结果,从打印的多行"..."中,我们就可以看出,读取了多次才读完。

将读取到的数据,慢慢的写入 b.txt中
修改mai3.js中的代码为如下,增加了下面代码的 4/10/16行,4行表示建立一个写入流(如果写入的文件不存在,会自动创建一个文件),10行表示往文件写入东西,16行表示关闭写入流。
1 var fs = require("fs"); 2 3 var rs = fs.createReadStream("a.txt"); 4 var ws = fs.createWriteStream("b.txt"); //写入流 5 rs.setEncoding("utf-8"); 6 7 //监听当有数据流入的时候 8 rs.on("data",function(chunc){ 9 console.log("..."); //读的过程中,我们打印三个点。 10 ws.write(chunc,"utf-8"); //向文件写入东西 11 }); 12 13 14 rs.on("end",function(){ 15 console.log("没有数据了"); 16 ws.end(); //关闭写入流 17 });
这样我们异步的读取和写入文件就实现了
好,今天就讲这么多,明天将讲解:express 路由。