1. 序列构成的数组:
容器序列:list, tuple, collections.deque可以存放不同类型的数据。
扁平序列:str, bytes, bytearray, memoryview, array.array只能容纳一种类型。
可变序列: list,bytearray,array.array, collections.deque, memoryview
不可变序列: tupe, str, bytes
2. 列表推导:构建列表的方法。eg: codes = [ord(symbol) for symbol in symbols]:
只用列表推导来创建新的列表,并且保持简短。
3. 生成器表达式: 虽然列表推导来初始化元组,数组或其他数据类型,但生成器表达式是更好的选择,生成器表达式遵守了迭代器协议,可以逐个产出元素,而不是先建立一个完整的列表,然后将这个列表传递到某个构造函数里。eg: tuple(ord(symbol) for symbol in symbols) 如果生成器表达式是一个函数调用过程中的唯一参数,则不需要额外用括号把它围起来。 eg: array.array('I', (ord(symbol) for symbol in symbols)) array构造方法需要两个参数,因此括号是必须的,第一个参数指定了数组中数字的存储方式,
4.元组tuple:元组不仅仅是不可变列表,还可以用于没有名字段的记录。元组其实是对数据的记录:元组中每个元素的存放都存放了记录中一个字端的数据,外加这个字段的位置。
元组拆包的时候,被可迭代对象中的元素数量必须要跟接受这些元素的元组的空档数一致。除非用*来表示忽略多余的元素。
os.path.split()函数就会返回以路径和最后一个文件名组成的元组(path,last_part)。 _占位符可以帮我们取得所需要的数据。
1 import os 2 _,filename = os.path.split('/home/hhhh/.ssh/idrsa.pub') 3 print(filename)
5.
*args表示任何多个无名参数,它是一个tuple
**kwargs表示关键字参数,它是一个dict
>>>a, b, *rest = range(5)
>>>(0, 1, [2, 3, 4])
6.嵌套元组拆包:
7.具名元组:colletions.namedtuple可以用来构建一个带字段名的元组和一个有名字的类
1 from collections import namedtuple 2 3 City = namedtuple('city','name country population coordinates') 4 tokyo = City('Tokyo','JP',36.933,(35.342432,139.3424234)) 5 print(tokyo)
具名元组除了继承来的属性,还有一些专有属性:_fields类属性,类方法 _make(iterable)和实例方法 _asdict()。
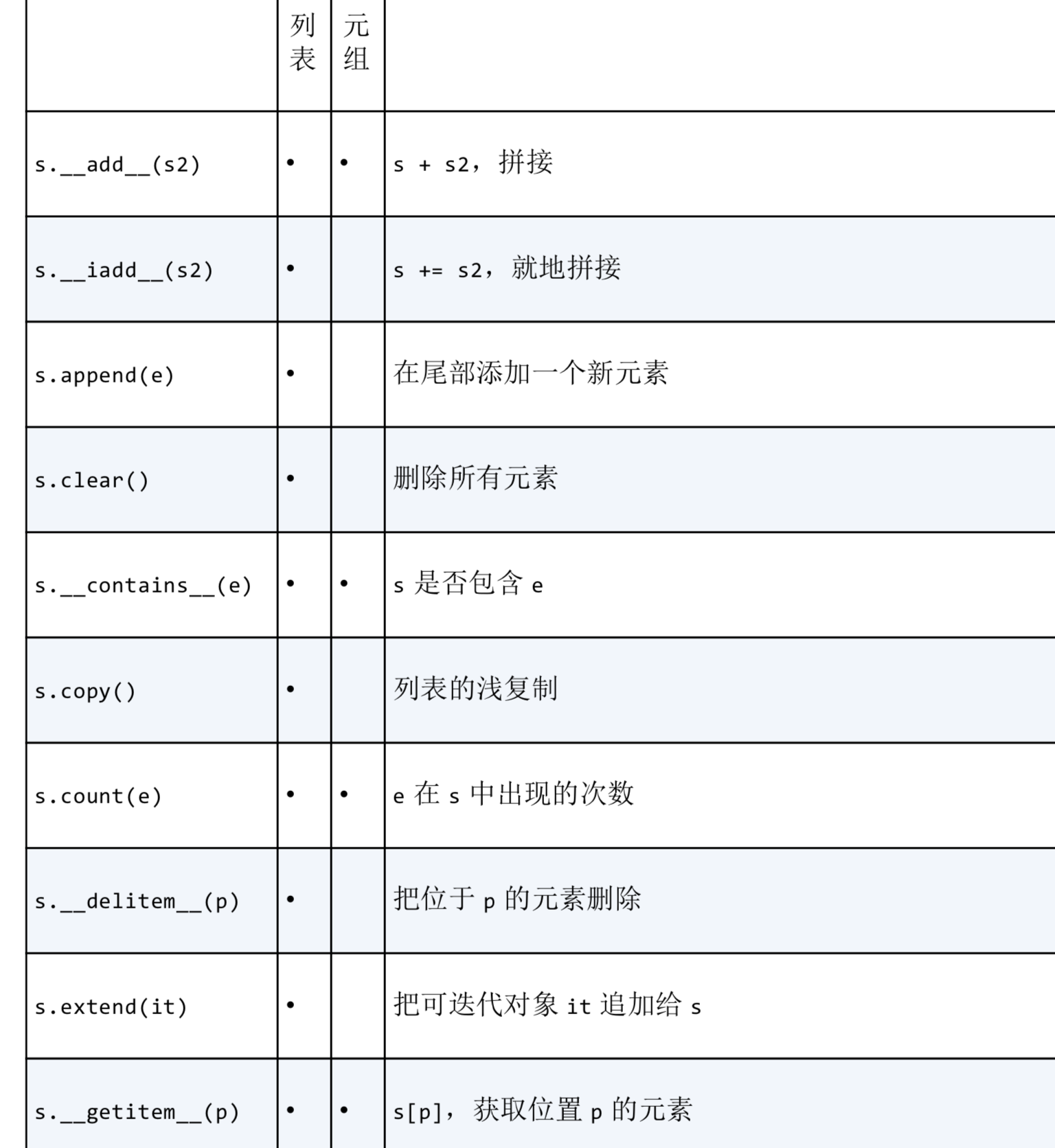
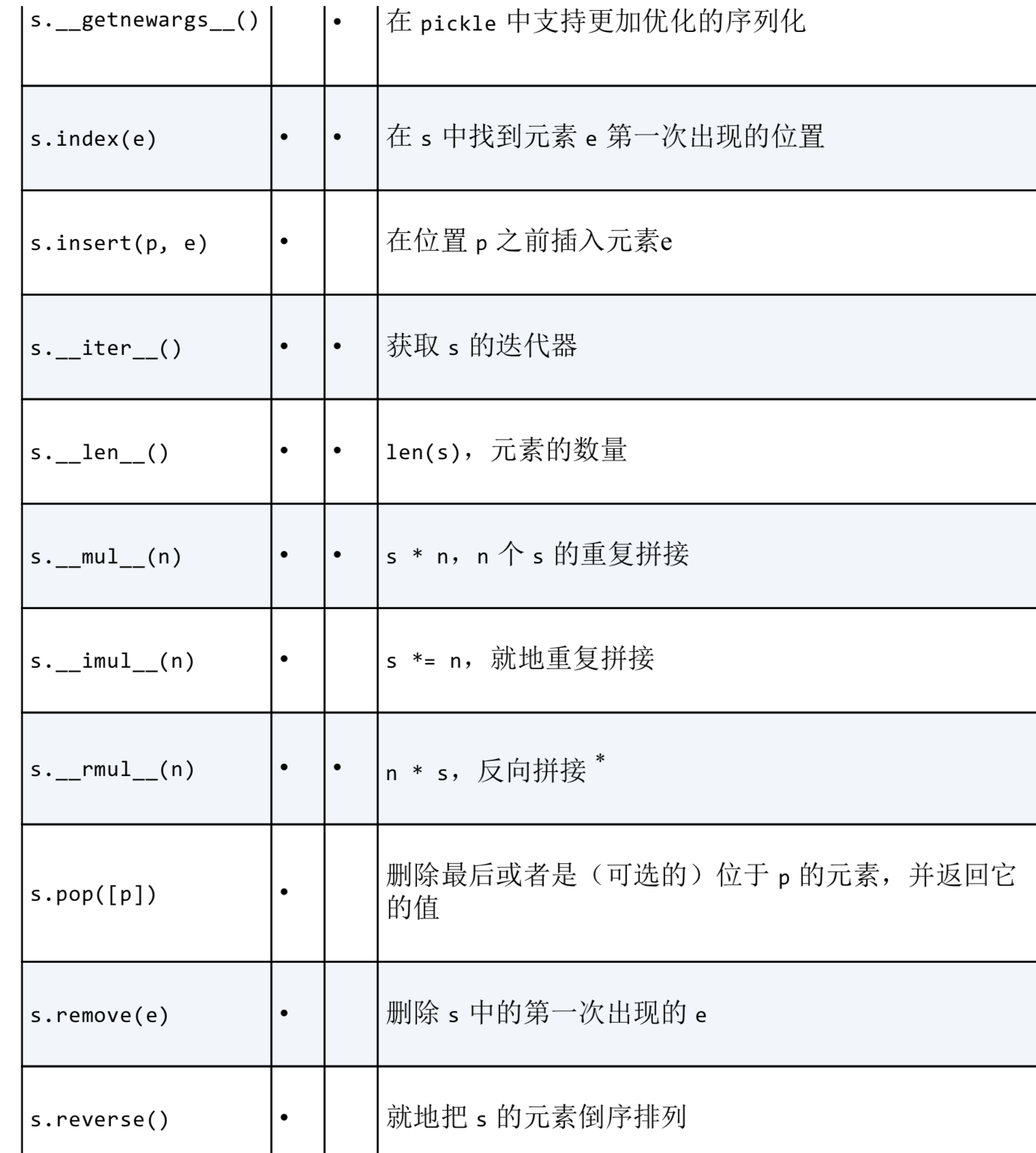
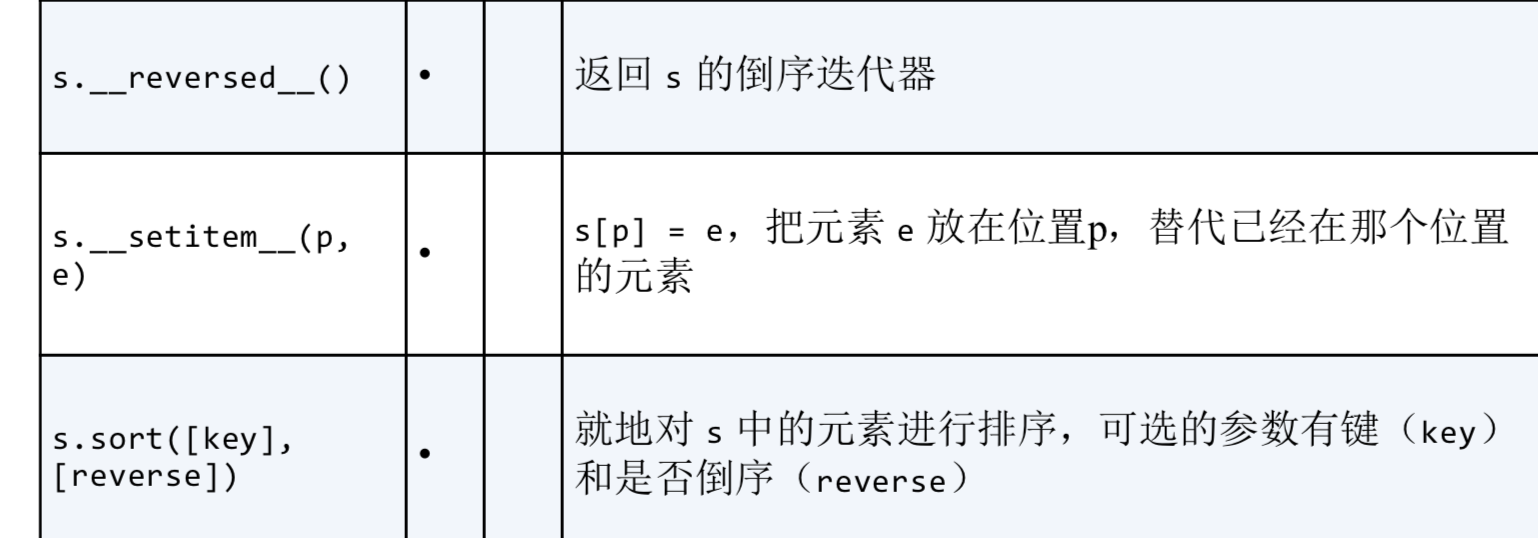
8. 元组的方法和属性:
8. 切片:
list tuple str 都支持切片。
l = [10,20,30,40,50,60]
l[:2] = [10,20]//在下标为2的地方分割
l[2:] = [30,40,50,60]
s[a:b:c] 可以在对s在a,b之间以c为间隔取值,c可以为负值(意味着反向取值)
s = 'bicycle'
s[::3] = 'bye'
s[::-1] = 'elcycib'
s[::-2] = 'eccb'
1 >>> t = (1,2,[30,40]) 2 >>> t[2] +=[50,60] 3 Traceback (most recent call last): 4 File "<stdin>", line 1, in <module> 5 TypeError: 'tuple' object does not support item assignment 6 >>> t 7 (1, 2, [30, 40, 50, 60])
虽然报错,但依旧可以打出t的值。所以不要把可变对象放进元组中。
9. list.sort和内置函数sorted:
list.sort会就地排序列表(如果一个函数或者方法对对象进行的是就地改动,那他的返回值应该是None,好让调用者知道传入的参数发生了改变,但没有产生新的对象),不会将原列表复制一份,不会新建一个列表。
sorted会新建一个列表作为返回值,这个方法可以接受任何形式的可迭代对象作为参数,甚至包括不可变序列或生成器,不管sorted接受怎样的参数,最后都返回一个列表。
reverse和key是这两种方法里面可选的关键字参数:
reverse:如果选定为True,被排序元素会以降序输出(默认值为False)
key: 只有一个参数的函数,此函数会被应在序列的每一个元素上,比如说key=str.lower来实现忽略大小写的排序,key=len基于字符串长度的排序。

10. bisect管理已排序的序列:
bisect包含两个主要函数:bisect和insort,都利用二分查找在有序序列中查找或插入元素。
bisect(haystack,needle)在haystack里搜索needle的位置。
1 DEMO: bisect 2 haystack -> 1 4 5 6 8 12 15 20 21 23 23 26 29 30 3 31 @ 14 | | | | | | | | | | | | | |31 4 30 @ 14 | | | | | | | | | | | | | |30 5 29 @ 13 | | | | | | | | | | | | |29 6 23 @ 11 | | | | | | | | | | |23 7 22 @ 9 | | | | | | | | |22 8 10 @ 5 | | | | |10 9 8 @ 5 | | | | |8 10 5 @ 3 | | |5 11 2 @ 1 |2 12 1 @ 1 |1 13 0 @ 0 0

11. bisect.insort插入新元素:
insort(seq,item)把变量插入序列seq中,并保持seq的升序顺序
12. 数组在存放大量的浮点数时,效率比列表的效率快得多,因为数组存储的不是浮点对象,而是数字的机器翻译(字节表述),如果要频繁的对序列进行先进先出操作,双端队列(deque)应该会更快。
13. 利用.append和.pop,我们可以把列表当作栈或者队列来使用,但是在删除第一个元素或者第一个元素之前添加一个元素等很耗时间,因为会移动里表里面所有的元素。
14. collections.deque类(双线队列)是一个线程安全,可以快速在两端添加或者删除元素的数据类型。
1 from collections import deque 2 3 dp = deque(range(10),maxlen=10)#一旦设定就不能修改 4 print(dp) 5 dp.rotate(3)#队列内旋转操作接受一个参数n,当n>0队列的最右边n个元素会被移动到队列的左边。n<0最左边的n个元素会被移动到右边。 6 print(dp) 7 dp.rotate(-4) 8 print(dp) 9 dp.appendleft(-1)#对一个已满的队列做头部添加操作,尾元素会被删掉 10 print(dp) 11 dp.extend([11,22,33])#尾部添加元素的操作挤掉-1,1,2 12 print(dp) 13 dp.extendleft([10,20,30,40])#会把迭代器里的元素诸葛添加到双向列表的左边(迭代器里的元素会逆序出现在队列里) 14 print(dp)