dui
1 from urllib.request import urlopen 2 from bs4 import BeautifulSoup 3 import re 4 import random 5 import datetime 6 7 pages = set() 8 random.seed(datetime.datetime.now()) 9 10 #获取当前页面所有内链的表 11 def getInternalLinks(bsObj,includeUrl): 12 internalLinks = [] 13 #找出所有以"/"开头的链接 14 for link in bsObj.findAll("a",href = re.compile("^(/|.*"+includeUrl+")")): 15 if link.attrs['href'] is not None: 16 if link.attrs['href'] not in internalLinks: 17 internalLinks.append(link.attrs['href']) 18 19 return internalLinks 20 21 #获取当前页面所有外链的表 22 def getExternalLinks(bsObj,excludeUrl): 23 externalLinks = [] 24 #找出所有以'http'和'www'开头且不包含当前URL的链接 25 for link in bsObj.findAll("a", 26 href=re.compile("^(http|www)((?!"+excludeUrl+").)*$")): 27 if link.attrs['href'] is not None: 28 if link.attrs['href'] not in externalLinks: 29 externalLinks.append(link.attrs['href']) 30 31 return externalLinks 32 33 def splitAddress(address): 34 addressParts = address.replace("http://","").split("/") 35 return addressParts 36 37 38 def getNextExternalLink(param): 39 pass 40 41 42 def getRandomExternalLink(startingPage): 43 html = urlopen(startingPage) 44 bsObj = BeautifulSoup(html) 45 externalLinks = getExternalLinks(bsObj, splitAddress(startingPage)[0]) 46 if len(externalLinks) == 0: 47 internalLinks = getInternalLinks(startingPage) 48 return getNextExternalLink(internalLinks[random.randint(0, 49 len(internalLinks)-1)]) 50 else: 51 return externalLinks[random.randint(0, len(externalLinks)-1)] 52 53 def followExternalOnly(startingSite): 54 externalLink = getRandomExternalLink("http://oreilly.com") 55 print("随机外链是:"+externalLink) 56 followExternalOnly(externalLink) 57 58 followExternalOnly("http://oreilly.com")
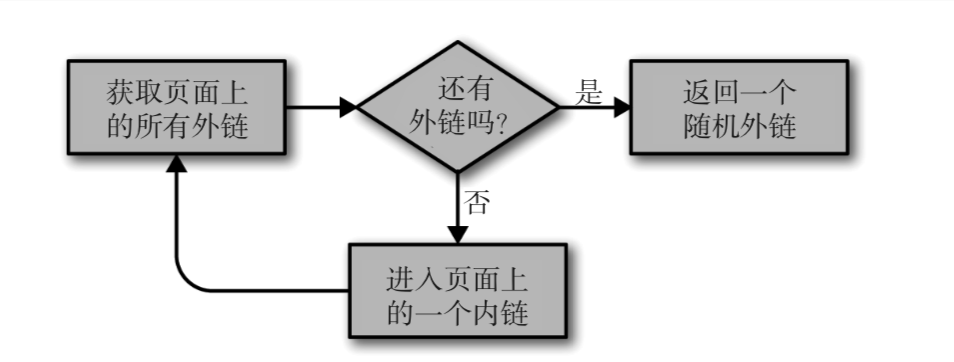
上面这个程序从 http://oreilly.com 开始,然后随机地从一个外链跳到另一个外链。
网站首页上并不能保证一直能发现外链。这时为了能够发现外链,递归地深入一个网站直到找到一个外链才停止。