本次使用爬虫的对象是图虫网(https://stock.tuchong.com/ )来获取主页的图片,由于图虫网中间使用了加密,但很容易就发现了规律。具体代码如下:
import requests
import re
request = requests.get('https://stock.tuchong.com/?source=extbaidukey2&utm_source=extbaidukey2')
date = request.text
img = re.findall('"imageId":"(.*?)","',date)
for i in img:
response = requests.get('http://weiliicimg6.pstatp.com/weili/sm/'+i+'.webp')
if response.status_code == 404:
response = requests.get('http://icweiliicimg6.pstatp.com/weili/sm/' + i + '.webp')
img_data = response.content
f = open(i+'.jpg','wb')
f.write(img_data)
f.flush()
这是我爬下来的图片不是原图大概在(100kb~200kb之间)
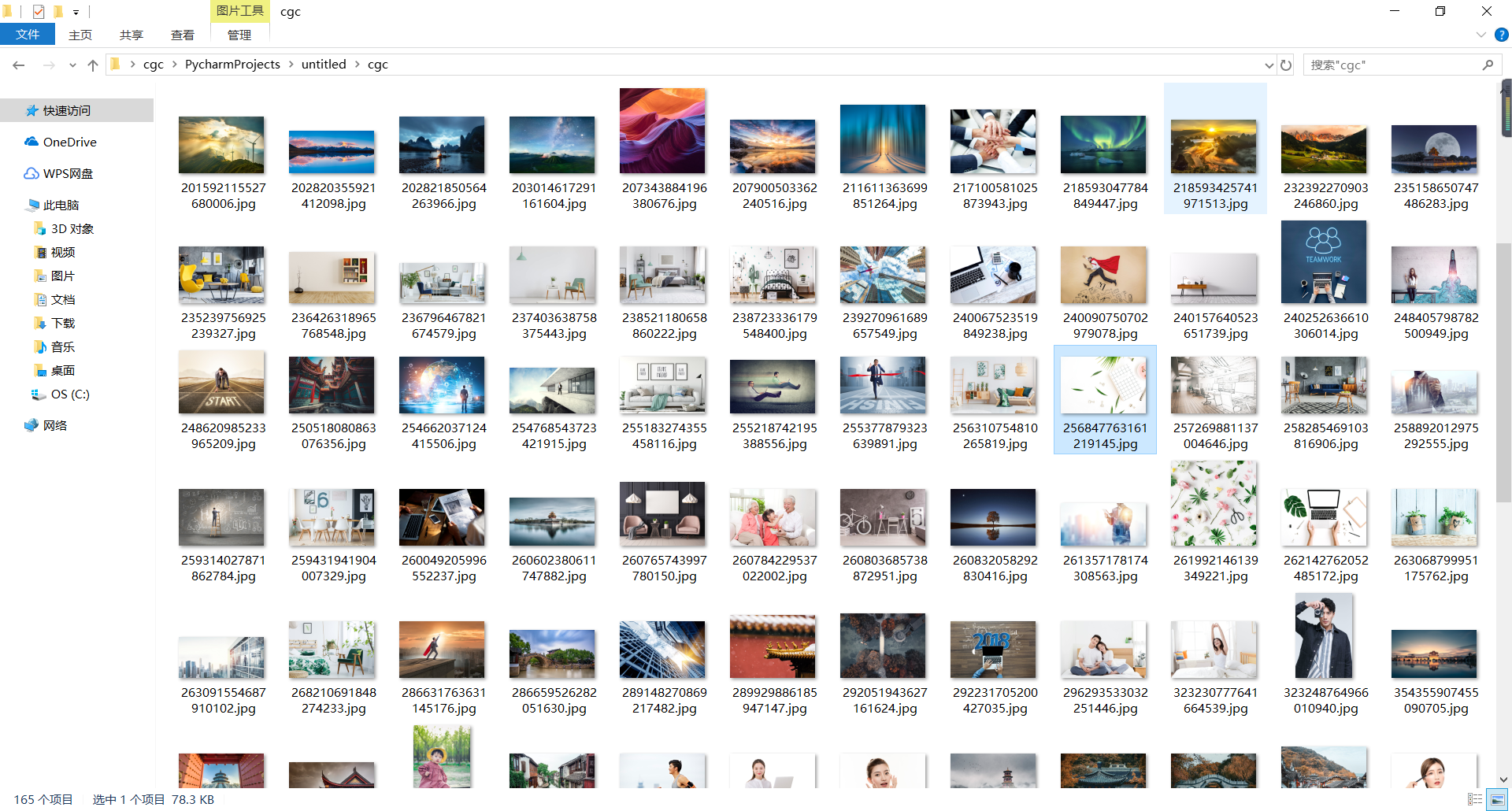
如有感兴趣的朋友可以和我讨论一下如何获取高清的样图