中国知网(CNKI)是最重要的中文学术资源数据库,收录绝大多数中文学术刊物。我们可以检索论文,也可以导出检索结果前6000条论文的题录数据。
在CNKI检索结果翻页10次以上,用户需要手动输入验证码才能继续。为了实现自动化题录数据导出,我们就需要通过程序识别验证码。最终,基于Eugu.CV实现验证码识别,正确率在70%以上,能保证自动化导出过程的连贯。
CNKI验证码识别主要分为四个步骤:
1 去掉灰色干扰线
2 去掉干扰点
3 二值化
4 基于Tesseract识别
CNKI验证码是长这个样子。

首先,要去掉验证码图片的灰色干扰线,如图:

去掉干扰线的思路:干扰线都是灰色,而灰色的RGB三色的值相对来说都比较大,所以将RGB三色值均大于150的点的颜色设置成白色。代码如下:
Bitmap bmp = (Bitmap)Image.FromFile(imagePath); for (int i = 0; i < bmp.Width; i++) { for (int j = 0; j < bmp.Height; j++) { Color color = bmp.GetPixel(i, j); int threshold = 150; if (color.R > threshold && color.G > threshold && color.B > threshold) { Color newColor = Color.FromArgb(255, 255, 255); bmp.SetPixel(i, j, newColor); } } }
然后,去掉干扰点,如图:

去掉干扰点的思路很简单,遍历每个点,如果它上下左右8个邻居点,有6个以上是白色的点,就把这个点也设置成白色。
for (int i = 0; i < bmp.Width; i++) { for (int j = 0; j < bmp.Height; j++) { var colorList = GetColorList(bmp, i, j); var count = colorList.Count(x => x.R == 255 && x.G == 255 && x.B == 255); if (count >= 6) { bmp.SetPixel(i, j, Color.FromArgb(255, 255, 255)); } } }
图片识别前需要二值化,也就是把图片变成黑白两色,即把所有的点都变成黑色。
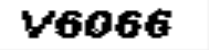
Eugu.CV提供了二值化的方法。
var gray = new Image<Gray, Byte>(bmp); var image = gray.CopyBlank(); CvInvoke.Threshold(gray, image, 120, 255, ThresholdType.Triangle);
最后,就是用Eugu.CV集成的Tesseract-OCR识别二值化图片。
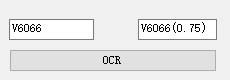
Tesseract是非常强大的OCR开源库,Eumu.CV集成了Tesseract 4.0,可以用lstm识别模式提供识别效率。
Emgu.CV.OCR.Tesseract ocr = new Emgu.CV.OCR.Tesseract(path, "eng", Emgu.CV.OCR.OcrEngineMode.LstmOnly, whitelist, true);
ocr.PageSegMode = Emgu.CV.OCR.PageSegMode.SingleLine;
var gray = new Image<Gray, Byte>(image);
ocr.SetImage(gray);
if (ocr.Recognize() != 0) throw new Exception("Failed to recognizer image"); var list = ocr.GetCharacters().Select(x => x.Text); textBox.Text = string.Join("", list);
如果你对识别结果的精确度不够满意,还可以通过Tesseract自己训练提高识别精度。