从PC客户端开发转项目经理已经有一段时间了,感觉还不错,平安这边的项目经理还需要对外,所以部门其他项目经理经常需要出差去见客户,我专门对内,部门所有的开发和测试每天做什么、接下来做什么我都必须了解,部门所有的项目在项目经理在公司或不在公司(他们经常不在)时,我都需要去跟进及协调,也算渐渐找到管理的感觉了。
说的有点远了,这段时间专门看了下部门Java后台的其他几个技术栈,可以合并为一个,那就是TDDL(Taobao Distributed Data Layer,淘宝分布式数据层)。
出现背景
当代互联网项目的数据都是海量的,当数据达到一定水平时,无法通过单个数据库服务器来实现,然后就出现了垂直分区(分库),根据业务不同对数据进行拆散,存储到不同的数据库中。但当数据继续增加时,单个数据库任然会因为数据量过大而导致性能下降,这时就可以采用水平分区(分表),将一个业务表拆成多个子表,比如user_table0、user_table1、user_table2,用N张表来维护同一个业务的数据。子表之间通过某种契约关联在一起,每一张子表均按段位进行数据存储,比如user_table0存储1-10000的数据,而user_table1存储10001-20000的数据,最后user_table3存储20001-30000的数据。经过水平分区设置后的业务表,必然能够将原本一张表维护的海量数据分配给N个子表进行存储和维护,这样的设计在国内一流的互联网企业比较常见,如下图

TDDL原型
淘宝根据自身业务需求研发了TDDL(Taobao Distributed Data Layer)框架,主要用于解决分库分表场景下的访问路由(持久层与数据访问层的配合)以及异构数据库之间的数据同步,它是一个基于集中式配置的JDBC DataSource实现,具有分库分表、Master/Salve、动态数据源配置等功能。
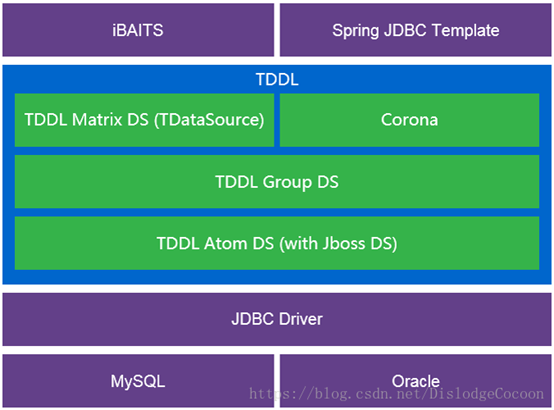
TDDL其实主要可以划分为3层架构,分别是Matrix层、Group层和Atom层。
- Matrix(TDataSource)实现分库分表逻辑,持有多个Group实例;
- Group(TGroupDataSource)实现数据库的主备切换,读写分离逻辑,持有多个Atom实例;
- Atom(TAtomDataSource)实现数据库ip,port,password,connectionProperties等信息的动态推送,持有原子的数据源(分离的Jboss数据源)。
SQL执行过程

TDDL的工作流程类似上图,client发送一条SQL的执行语句,会优先传递给Matrix层。由Martix 解释 SQL语句,优化,并根据查询条件路由到各个group,转发sql进行查询,各个group根据权重选择其中一个Atom进行查询,各个Atom再将结果返回给Matrix,Matrix将结果合并返回给client。具体的工作流程的可以拆分成如下图:
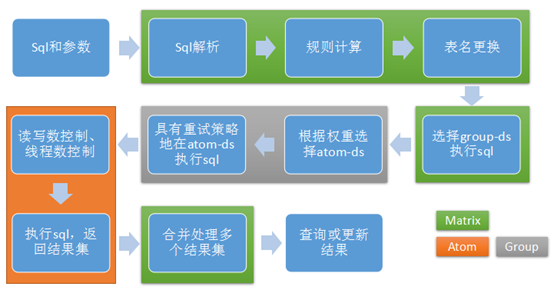
Matrix层会先执行以下四个过程:
a)Sql的解析。首先将Sql语句解析成一颗抽象语法树(Abstract Syntax Tree),解析成我们比较好处理的一个结构
b)规则的匹配与计算。基于上一步创建的语法树查找匹配的规则,再根据规则去确定分库分表的结果。这里有一个概念就是规则,规则这里可以简单的看做就是定义数据库怎么进行分库分表,要分成几张库几张表,库名和表名的命名是怎么样的。规则的匹配就是根据SQL的语句确定,具体查询的子表是哪几张。
c)表名替换。对于开发人员来说,它查询的表直接就是select * from A.B limit 10(A为数据库名,B为数据表名)。但底层其实会把这些表名替换成类似select * from A_000.B_001,select * from A_000.B_002,select * from A_001.TABLE_001这样的形式。表名替换就是把总表的名称替换为这些子表的名字。
d)Sql的转发。将上一步生成的各个sql语句转发到对应的Group进行执行。这里如上图,我查询的条件是where id = 2 or 3。那么转发给Group0的查询为where id=3,转发给group1的查询为where id =2 。查询的条件也会发生一定修改。
这样四个步骤可以在Matrix层就实现了分库分表的功能,对原始的Sql进行分解,将原本单库单表的查询语句,底层转发到多库多表并行的进行执行,提高了数据库读写的性能。
接下来由Group执行两个过程:
e)根据权重选择AtomDs。通常会在主节点和副节点上读取数据,只在主节点上写入数据。
f)具有重试的策略地在AtomDs上执行SQL。这个可以防止单个的AtomDs发生故障,那么会进入读重试,以确保尽可能多的数据访问可以在正常数据库中访问。
然后是Atom层执行两个过程:
g)读写数控制、线程并发数控制 。同时会统计线程数、执行次数等信息。
h)执行sql,返回结果集。Atom底层利用druid进行连接池的管理,具体查询还是对JDBC做了一定封装。执行完Sql后对将结果返回给Matrix。
最后Matrix执行最后一个过程:
i)结果集合并。Matrix将Atom层的返回的各个结果集进行合并Merge,返回给Client端。
主要特征
1.数据库主备和动态切换
2.带权重的读写分离
3.单线程读重试
4.集中式数据源信息管理和动态变更
5.剥离的稳定jboss数据源
6.支持mysql和oracle数据库
7.基于jdbc规范,很容易扩展支持实现jdbc规范的数据源
8.无server,client-jar形式存在,应用直连数据库
9.读写次数,并发度流控,动态变更
10.可分析的日志打印,日志流控,动态变更
最后因为TDDL依赖于diamond配置管理中心,这里推荐一篇博客https://blog.csdn.net/kevinlynx/article/details/40017109