Few-shot Neural Architecture Search
2021-ICMLo-Few-shot Neural Architecture Search
- Institute:Worcester Polytechnic Institute(伍斯特理工学院), Brown University, FAIR
- Author:Yiyang Zhao, Linnan Wang, Yuandong Tian
- GitHub:https://github.com/facebookresearch/LaMCTS
- Citation:8
Introduction
One-shot是使用1个超网, 本文的few-shot是将超网划分为几个子超网, 以增加一定的训练开销为代价改善子网评估的效果(rank)
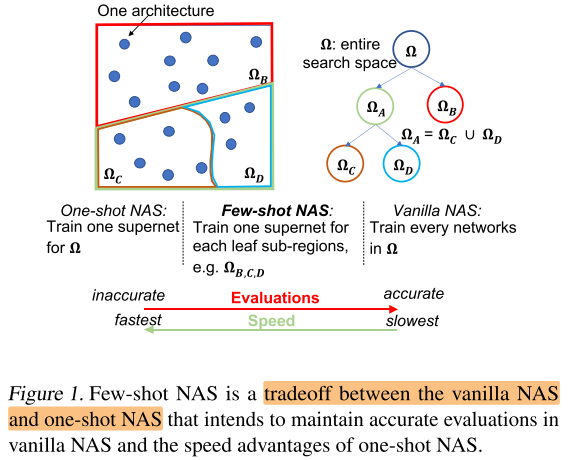
Motivation
- One-shot由于不准确的子网 rank, 导致较差的搜索性能
Contribution
- One-shot NAS 速度快, rank差; vanilla NAS 速度慢, rank好; few shot NAS作为两者的trade off, 兼具2者的优点(快和准)
- 超网拆分为n个子超网后, 会面临训练开销随之变为原来的n倍的问题, 作者提出了一种迁移学习的策略, 来节省多个子超网的训练开销
- ImageNet 600M 80.5%, 238M 77.5%, CIFAR-10 98.72%
Method
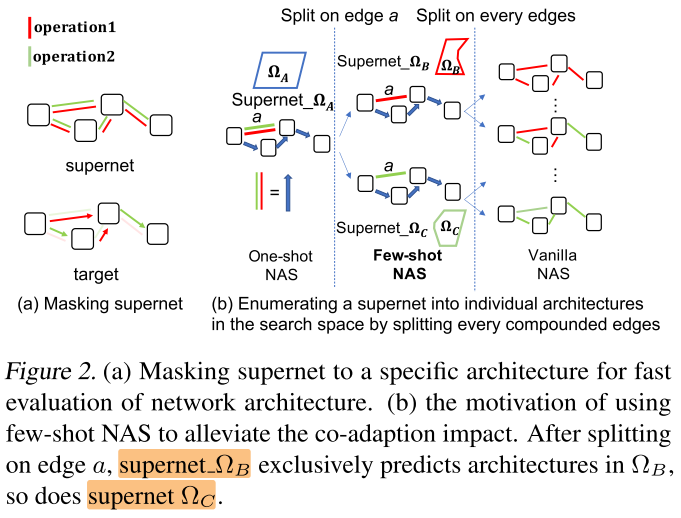
超网拆分为多个子超网: 设每条复合边有 (n) 个op, 则拆1条复合边可以得到 (n) 个子超网; 拆2条复合边可以得到 (n^2) 个子超网... ;
但训练开销相应地增加为原来的 (n, n^2, ...) 倍, 这是不可接受的; 子超网拆分的过程可以看做一棵树, 原始的超网是根节点, 每拆分1条复合边得到 (n) 个叶子节点
子超网的训练方式: 先将1个根节点 (原始超网) 训练到收敛, 下一级的叶子节点的子超网集成父节点的权重继续训练(迁移学习), 很快就能收敛(几个epoch), 从而节省多个子超网的训练开销
拆的边越多, rank越高, 但训练开销也越大; 在总训练开销T (设置为2倍One-shot NAS开销) 一定的情况下, 拆分的子超网的深度定义为: 若总训练开销超过T时, 则停止往下拆分 (后面的实验基本上就是拆1个op)
Experiments
验证性实验
拆几条边?
为了验证将超网拆分为多个子超网, 可以提高子超网的rank, 作者先做了一个验证性实验:
构造1个有有4条复合边, 每条复合边有6个op的超网, 逐步拆分为1, 6, 36, 216, 1296 个子超网, 验证不同数量的子超网对全部子网 (1296个) 的rank准确性:
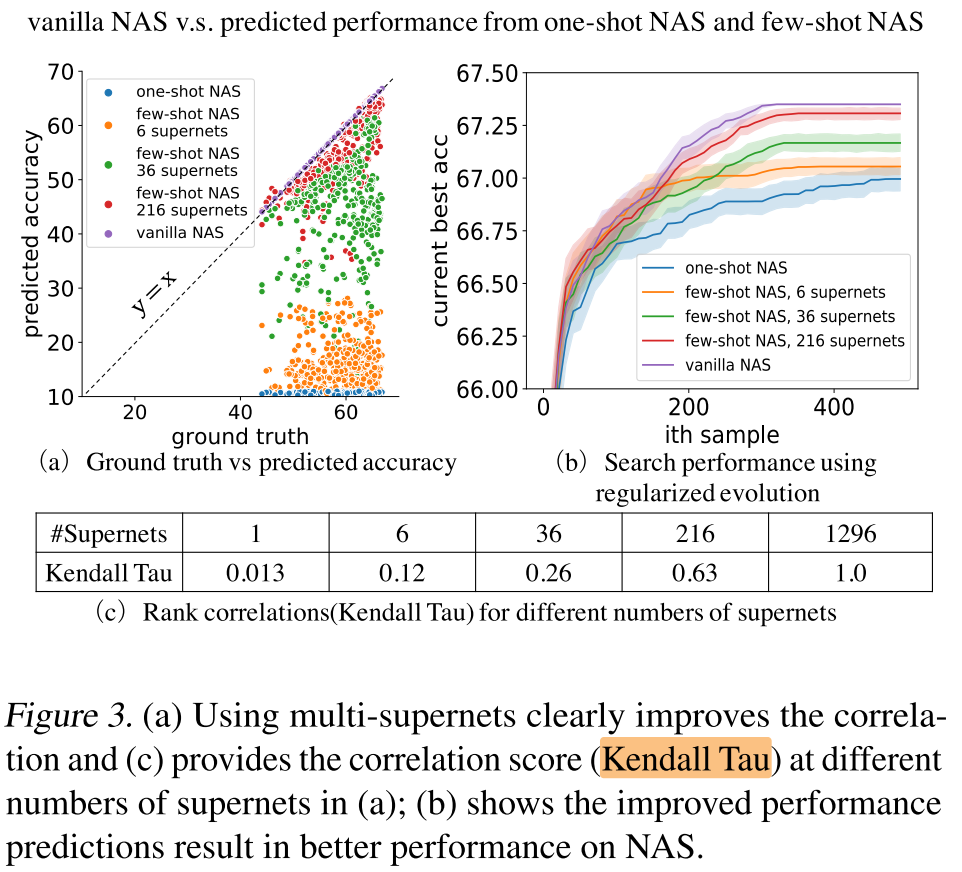
可以看出, 拆分的越多, rank的准确性越高;
拆哪几条边?
拆k条复合边时, 应该选哪种组合? 作者在NASBench 201(6条复合边, 每条复合边5个op) 上做了一个验证性实验
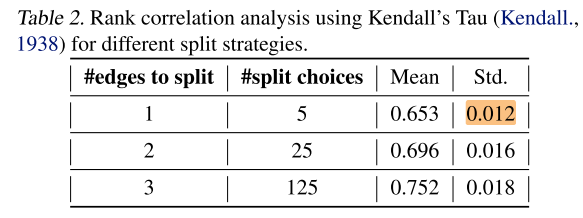
每条复合边5个op, 拆1, 2, 3条边, 会分别生成 5, 25, 125个子超网;
一共6条复合边, 拆1, 2, 3条边, 分别有 (C_6^1=6, C_6^2=15, C_6^3=30) 种选择, 作者将每种拆分选择都测了一遍, 发现:
- 拆分越多, rank越高 (和上个实验结论一样)
- 方差很小, 即不同的的拆分方式, rank差距不大
即只需要关注要拆几条, 无需关注拆哪几条边
NASBench 201 Search Space, use Gradient-based NAS Method
基于梯度的NAS方法: 将1个One-shot超网, 从头梯度优化到底, 得到1个最佳的子结构(及对应权重)
作者这里在4种梯度的NAS方法上, 将One-shot改为few-shot(拆分1条复合边, 得到5个子超网), 在NASBench 201的搜索空间上进行实验, 首先将原始超网训练到收敛, 分割为5个子超网, 继承超网权重, 继续训练到收敛, 从所有子超网中选择acc最高的子网作为最终的最佳子网;
图5中显示 few-shot 一致地比One-shot更好
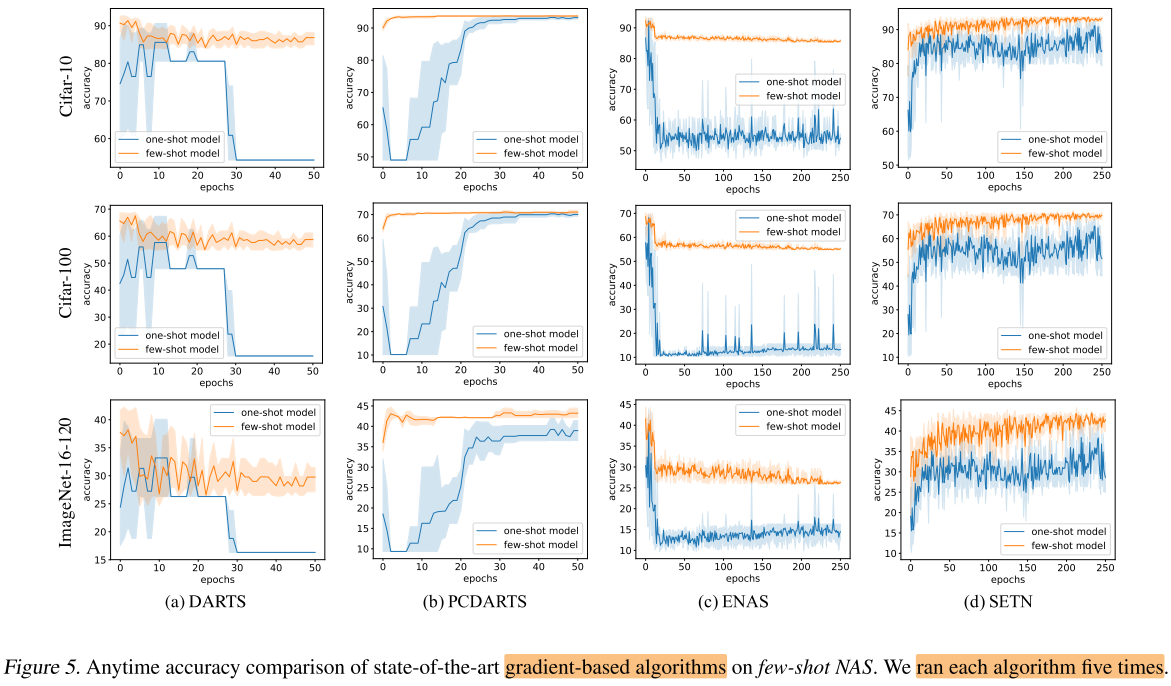
在这部分实验中没有使用(无法使用) 迁移学习, 因此作者说是保持相同的训练epoch进行对比 (&& 应该是指每个子超网的训练的epoch和原始超网相同, 即总训练开销为不拆分前的5倍)
NASBench 201 Search Space, use Search-based NAS Method
Search-based NAS 方法概述
在基于搜索的One-shot NAS方法: 选择1个性能函数来指导搜索, 搜索流程:
- 采样1个子网(一组结构参数 (arch_i), 可以看做待搜索的超参)
- 性能函数评估改子网的性能 (acc_i)
- 超参搜索算法(TPE/SMAC...) 根据历史的超参选择( (arch_1, arch_2, ...))及对应的性能指标( (acc_1, acc_2, ...) ), 来决定下一次采样 (return 1)
- 达到最大采样次数 T 时, 采样停止, 根据所有的采样结果, 选择top k个子网, 从头训练这k个子网, 选择性能最好的作为本次搜索流程的最终结果
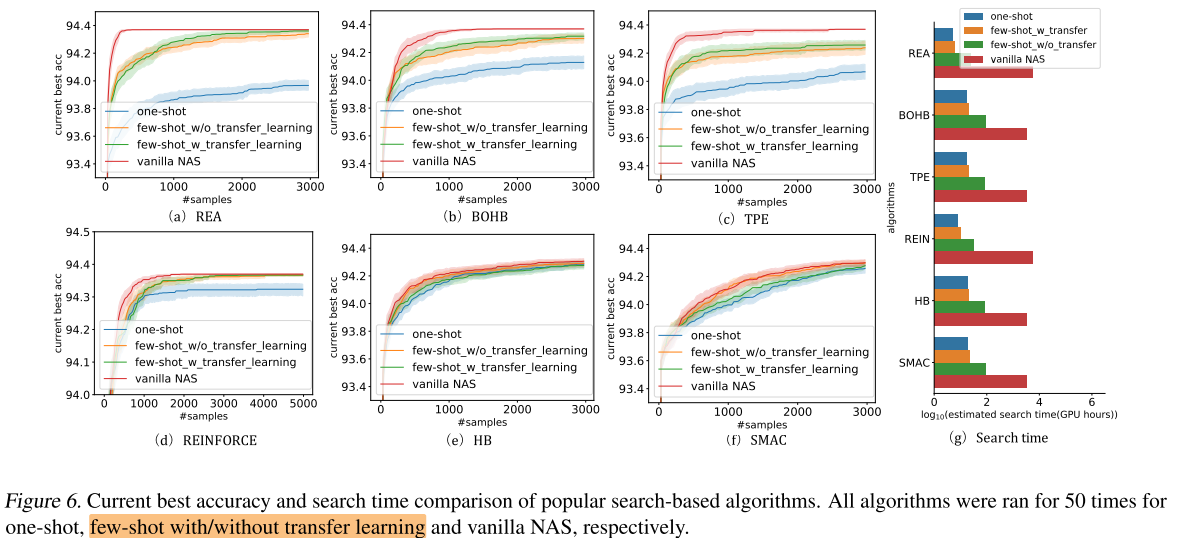
由于在NASBench 201上进行搜索, 步骤4可以直接查表得到子网的真实性能, 因此可以获得T=1,2,3,... 时的实时搜索结果;
影响搜索流程的2个部分: 性能函数(vanilla / One-shot supernet / Few-shot sub-supernets) 和 超参搜索算法(TPE/SMAC...)
性能函数(性能评估器)
- vanilla NAS: 对所采样结构从头训练+early stop
- One-shot supernet: 预先训练One-shot supernet
- Few-shot sub-supernets: 预先训练 Few-shot sub-supernets
超参搜索算法
TPE/SMAC/BOHB/...
总时间开销
包含性能函数的开销和超参搜索算法的开销(可忽略), 主要就是性能函数的开销
图6可以看出 使用 vanilla NAS作为性能评估器的搜索效率最高, 但总开销最大
few-shot sub-supernets作为评估器的搜索效率一致地高于One-shot supernet, 总开销只是略高于One-shot
将few-shot NAS应用在现有的NAS方法上
把网上放出来的开源代码然后从 one-shot NAS 改成 few-shot NAS,然后并且使用同样的超参,重新跑一遍结果进行对比
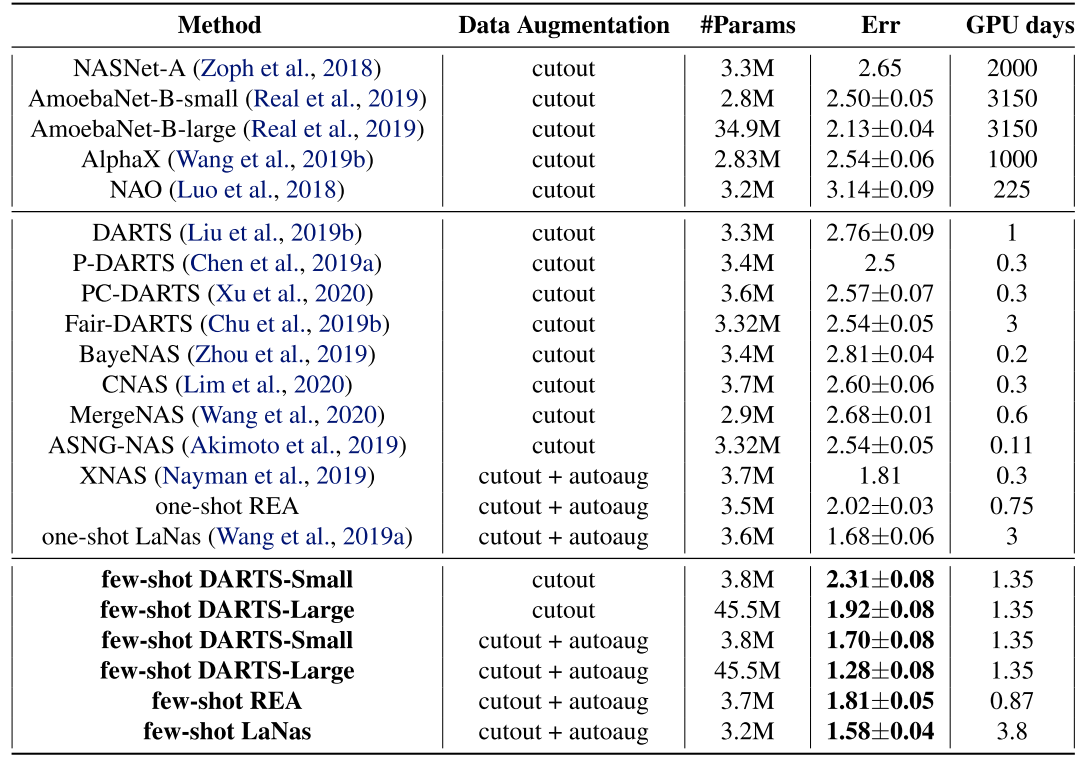
CIFAR-10
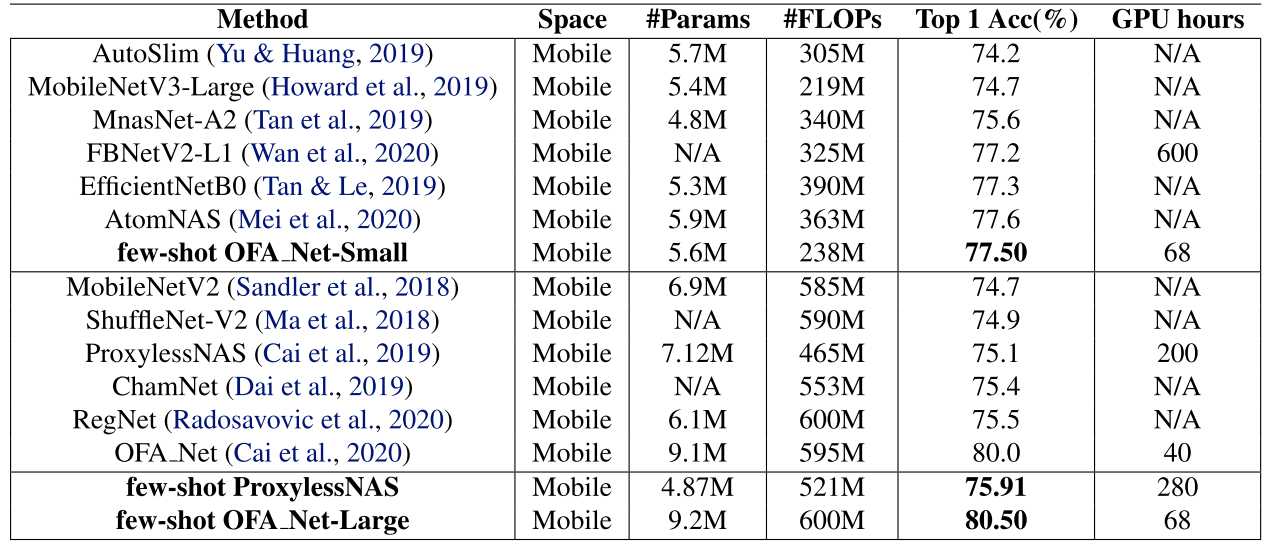
ImageNet
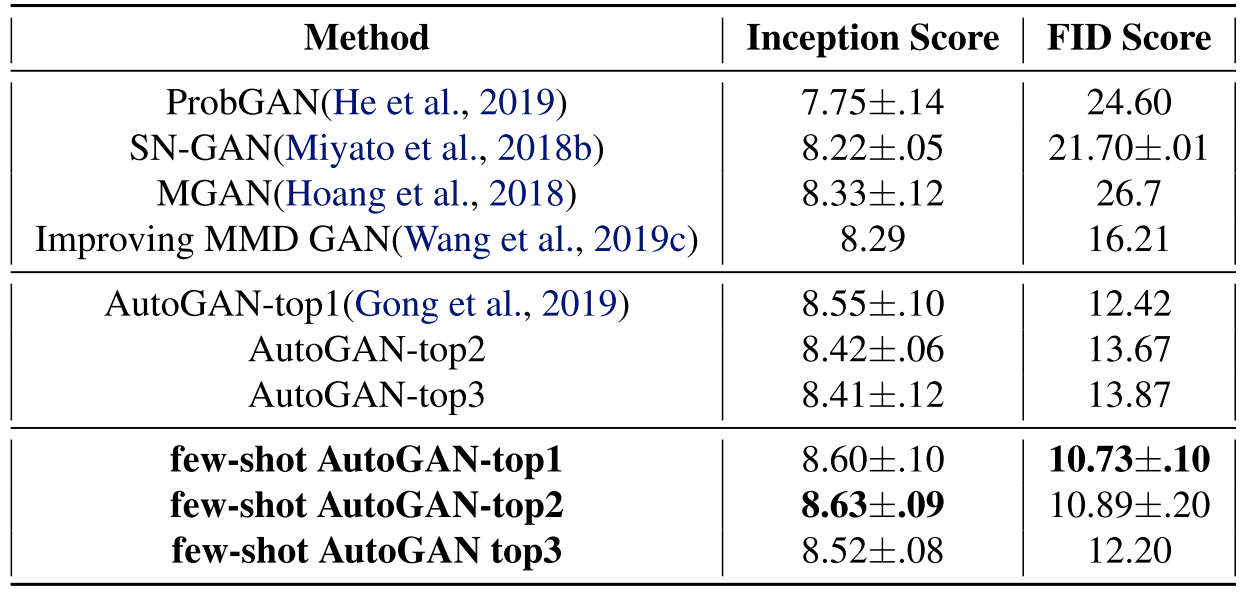
AutoGAN
Conclusion
Summary
pros:
- nas方法中的基础方法的小改动, 可以直接用到所有One-shot NAS中