SCAN
2019-NIPS-SCAN: A Scalable Neural Networks Framework Towards Compact and Efficient Models
来源:ChenBong 博客园
- Institute:Tsinghua
- Author:Linfeng Zhang,Zhanhong Tan,Chenglong Bao
- GitHub:/
- Citation: 14
Introduction
attention,self KD,dynamic network,model ensemble,genetic algorithm
2019-ICCV-Be Your Own Teacher 的兄弟篇
在推理过程中实时调整 latency 和 acc 的 trade off 的动态(结构)网络。对不同深度的中间层插入多个分类器的一类方法(MSDNet)的改进。
Motivation
人类的视觉系统:简单的图片快速识别,遇到困难的图片花更多的时间/脑力(算力)进行辨认,人类的大脑自然而然地会对不同难度的图片花费不同的识别开销,因此提出动态网络的概念(sample individual)
之前的动态网络方法存在的问题:
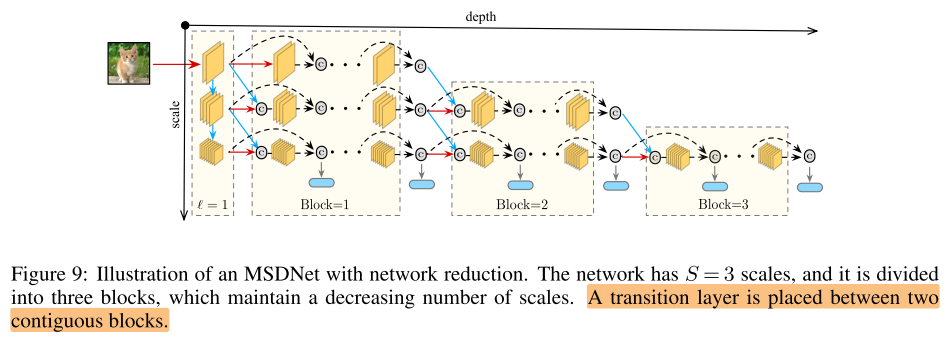
- 在 backbone 不同深度的中间层插入多个分类器的方法(MSDNet),由于不同深度的分类器共享 backbone 参数,不同深度的分类器有消极的互相影响,导致多个分类器的性能都不如单独训练时的性能
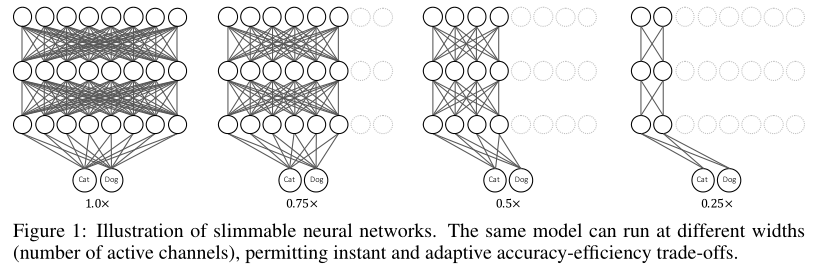
- 宽度可变的方法(Silmmable),窄网络的计算,不能被宽网络重用,导致每个宽度都要从头推理,浪费了推理时的计算开销/时间
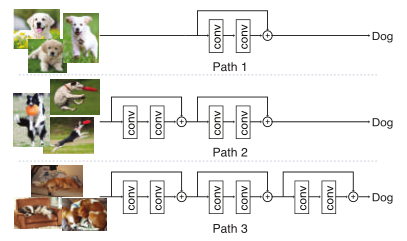
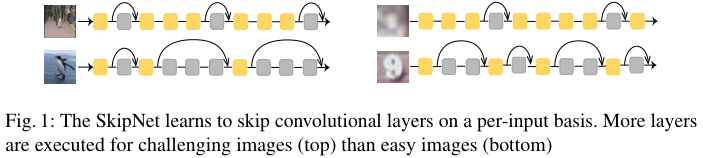
- 对于自适应的推理图的方法(BlockDrop,SkipNet),有着比较复杂的 dropping/skipping 策略,导致加速效果不好
之前模型压缩方法存在的问题:
- 传统的压缩方法专注与模型结构的冗余性,而忽略了样本难度的差异,不应该将不同难度的样本同等对待
MSDNet:
Silmmable:
BlockDrop:
SkipNet:
Contribution
- 加入了知识蒸馏和注意力机制,使得不同深度的多个分类器不再有消极的相互影响,反而可以相互受益。
- 在不同深度的中间层插入多个分类器,使得不同分类器的计算可以被重用
- 本文的方法可以与任何结构的 backbone 网络结合(其他方法可能需要重新设计backbone网络,如MSDNet), 实现动态推理。
- 第一次将网络压缩和加速与注意力机制结合(精度提高),使用静态的推理图(加速效果好)
Method

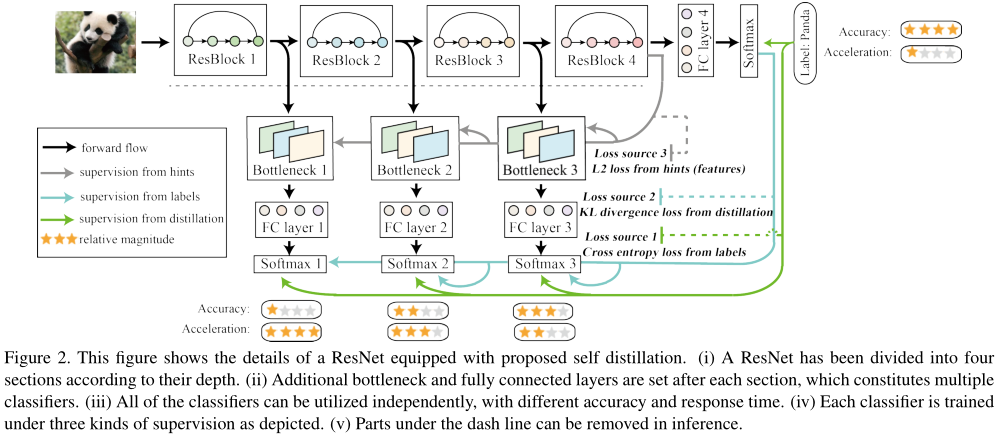
横向为backbone网络,将backbone网络分为不同的stage,在stage之间插入纵向模块
纵向分为3部分,分别为 Backbone 网络,Attention 模块,Classifier 模块:
- Backbone:和原始网络一样
- Attention 模块:conv,deconv,sigmoid
- Shallow Classifier 模块:Bottleneck layer,FC
Self distillation
Shallow Classifier 模块由 Bottleneck layer&& 和 FC 组成;
浅层分类器和最终分类器做蒸馏:
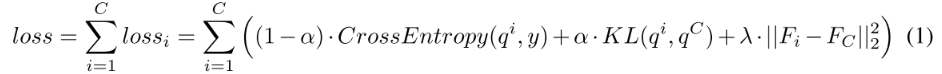
q 是 softmax,F是 feature map
Attention modules
Attention modules&& 由 conv,deconv,sigmoid 组成,输出一个0/1的 attention map,和原始的feature map作dot product,得到 classifier-specific features
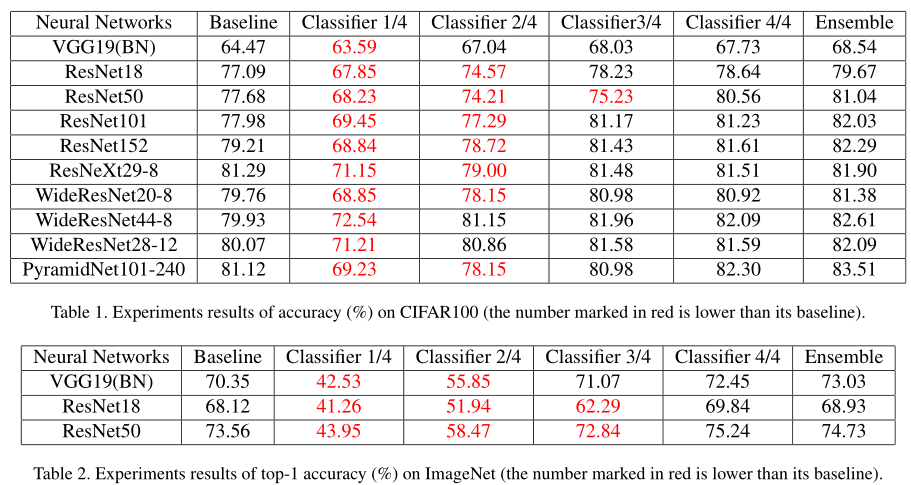
cifar100,res50,x=1-4指不同的shallow classifier,x=5指 ensemble所有 classifier 的结果
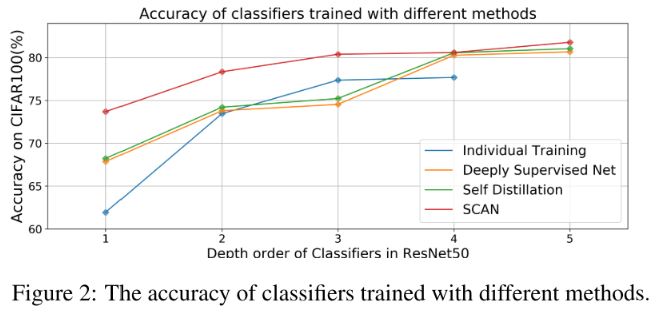
如果中间层直接插入分类器,由于每个分类器都会使靠近它的层学习有利于分类的(高级)特征,而深的分类器又希望浅层学习低级特征,导致互相干扰。即使用了 self distillation,还是比 individual training 差
加入 Attention module,学习 classifier-specific features,从图2可以看出,性能有了很大的提高
Scalable inference mechanism
低层的classifier输出的置信度高于某个阈值(softmax值大),则认为预测结果足够准确,即提前退出。
如何设置阈值?为每个classifier单独设置阈值,且使用进化算法搜索每个classifier的阈值
总体算法流程:

Experiments
CIFAR100
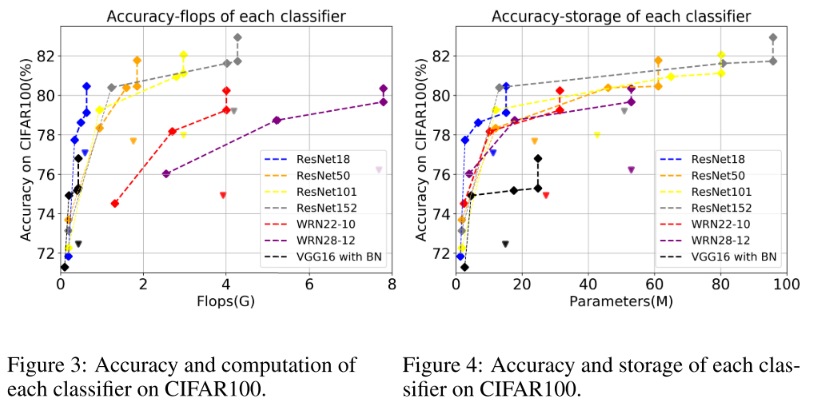
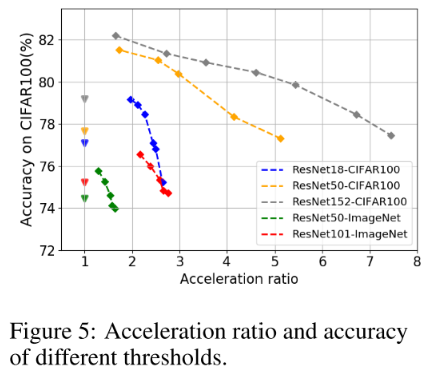
虚线上横向的方块是不同classifier的性能,纵向上的方块是ensemble的性能;三角是对应颜色曲线的 baseline
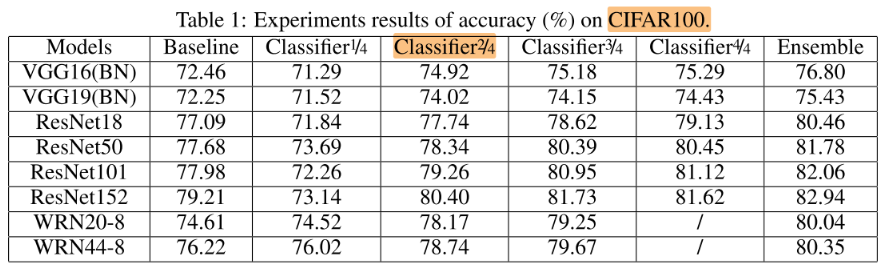
- 所有的模型中,classifier 2/4就已经超过了baseline
- 在精度不掉的情况下,平均(FLOPs)加速比 2.17x,平均(参数)压缩率 3.20x
- 平均在增加4.4%的计算开销下,有4.05%的性能增长
ImageNet

加速比
Discussion
Attention module 学到了什么?
将attention map的不同channel对应位置元素求均值,左到右应该是不同深度的 attention module

不同深度classifier预测正确的比例
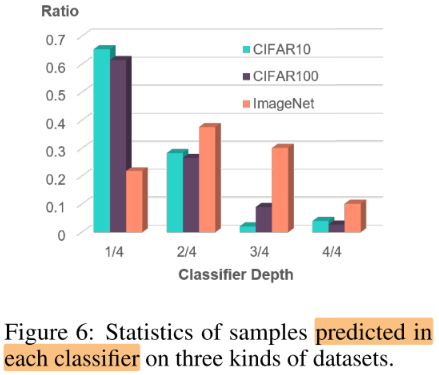
观察:简单的数据集主要在浅层的classifier被分类出来,而困难的数据集需要在较深的classifier才能被分类出来
作用:
- 指导压缩,对于cifar10/100,深层存在很大的冗余
- 作为一个metric来评估数据集的困难程度
Conclusion
Summary
pros:
- 折线图,柱状图,attention可视化图
- 热点较多,但框架和之前的一些动态网络比起来还是比较简单清晰高效的
cons:
- 对 bottleneck layer 的设计没有具体的解释
- attention module 本质上也只是加了2个layer,为什么加了conv和deconv就可以大幅提高性能?没有具体的解释;attention 可视化有hand-pick的空间
与Be your own teacher的区别
Be your own teacher:
SCAN:
本文与Be your own teacher相比,只多了attention模块
Be your own teacher:
SCAN:
两篇文章的框架和训练思路基本都相同,主要是出发点不同,Be your own teacher是从自蒸馏的角度,SCAN是从动态计算的角度。