Cream of the Crop
2020-NIPS-Cream of the Crop: Distilling Prioritized Paths For One-Shot Neural Architecture Search
来源:ChenBong 博客园
- Institute:MSRA,CUHK,CAS,THU
- Author:Houwen Peng, Hao Du,Hongyuan Yu,Jianlong Fu
- GitHub:https://github.com/microsoft/cream 100+
- Citation: /
Introduction
一般的超网NAS方法(e.g. SPOS):训练超网 ==> 搜索最佳子模型 ==> retrain
本文的方法:训练超网,得到最佳子模型 ==> retrain
基于SPOS的改进:
- 训练:在抽样子网的同时,维护了一个优质模型池(<目标flops),用于存储采样中获得的优质子网,每次随机采样一个子网后,从优质模型池(使用Meta Network)找到与之最匹配的优质子网,作为 teacher,指导采样到的子网进行更新(蒸馏)。
- 模型池更新:如果采样到的子网比模型池中最差的子网优秀,则将该采样到的子网加入模型池
- 获得最佳子网结构:训练结束,模型池中性能最好的子网即作为最佳结构,无需搜索过程
- 获得最佳子网:retrain,将最佳子网retrain 500 个epoch
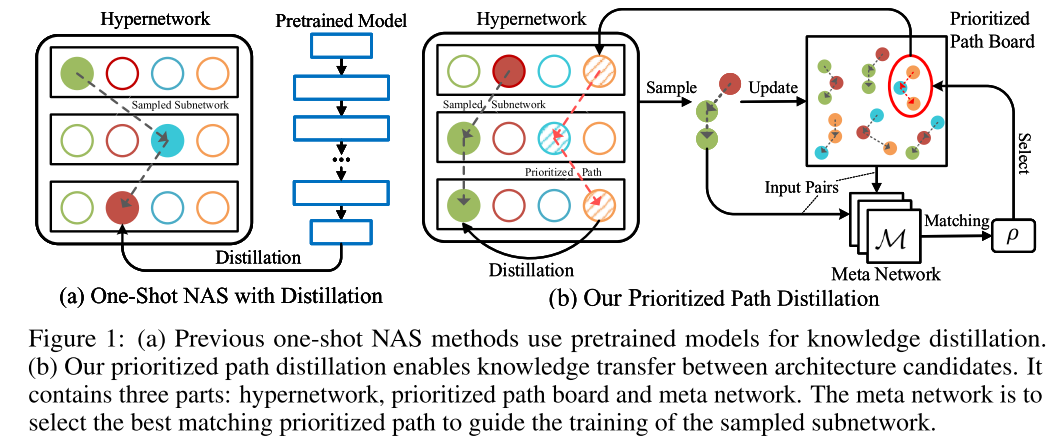
Motivation
超网训练的固有缺陷:子网没有得到充足训练
其他方法在超网训练结束后还需要对超网进行搜索(EA,RL...)
其他使用蒸馏的超网训练方法采样到的子网进行训练时,需要额外的 tearcher (OFA)
Contribution
Method
模型池
包含 K 个优质子网
每个 batch 采样1个子网,在模型池中寻找与之最匹配的优质子网指导其更新,验证采样到的子网,如果该子网比模型池中最差的子网优秀,则将该采样到的子网加入模型池,替换模型池中最差的子网:
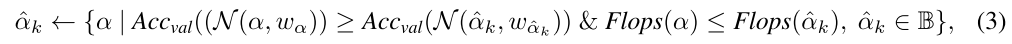
使用模型池的SPOS

在模型池中找到与采样子网的最佳匹配
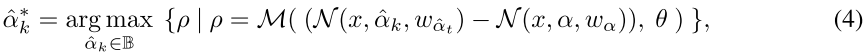
更新子网参数
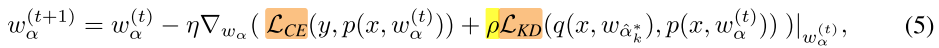
更新MetaNetwork参数
冻结网络参数,更新MetaNetwork参数 θ,需要计算二阶导,计算量大因此间隔 ( au) 计算一次:
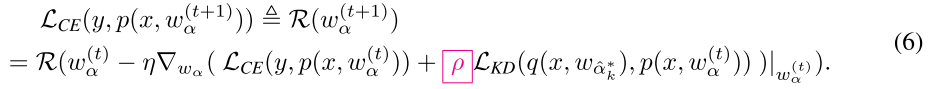
Experiments
Setup
- 16 V100
- 2048 batchsize
- AutoAugment
- 500 epochs
- lr scheduler:cosine annealing
Search Space
ImageNet
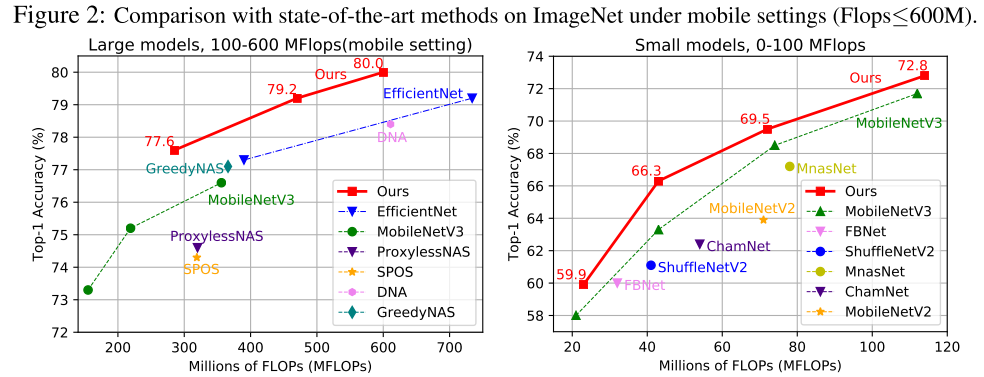
左图为小flops(<100M)的搜索结果,在其他nas方法中较少见

在每个区间,不同方法没有在相近的flops下比较,且本文的方法的flops都较大
Ablation Study
各个模块的作用

1 vs #2:EA搜索和模型池作用相当
2 vs #4 / #5:KD的有效性
5 vs #6:模型池+EA作用不大
模型池的规模 K
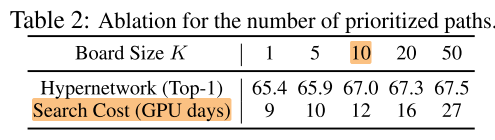
超网训练/搜索开销:12 GPU days(V100)
Conclusion
Summary
pros:
- 做了小flops的一些结构搜索,在其他 nas 工作中好像比较少见
cons:
- 使用子网与优质模型的 output logit 的差计算两个模型匹配度,感觉理由不够充分,匹配度应该是包括中间层的一些输出,而不仅仅是最后一层的输出
- MetaNetwork 的输入实际上只是计算2个一维向量的距离,使用全连接似乎大材小用,能否使用简单的L1/L2-norm
- 还是需要retrain,最近的超网工作的趋势应该都是无需retrain的,不同规模都要重新搜索+retrain(对比无需retrain的OFA、BigNAS,代价太大)
- retrain 开销太大,500 epoch,AutoAugment...