CondConv
2019-NIPS-CondConv: Conditionally Parameterized Convolutions for Efficient Inference
来源:ChenBong 博客园
- Institute:Google Brain
- Author:Brandon Yang,Quoc V . Le
- GitHub:
- Citation: 30+
Introduction
CondConv卷积层可以对每个样本进行条件计算,CondConv可以为每个样本定制单独的卷积层,从而在不提高计算量的情况下,提高网络的性能。
CondConv卷积层是一种 plug-in 的 conv layer,可以和现有的 CNN 模型结合,替换 常规conv 即可。
Related Work
conditional computation
条件计算是模型压缩的一个子方向,主要思想是根据不同的样本,选择不同的权重子集。
motivation:不同的 layer 提取的是不同的特征,对于不同的样本,所需要重视的特征应该也是不同的,能否让网络根据输入样本的差异(难度/类别/特征,方圆/颜色...),自动选择不同的 block/branch/layer/filter 进行计算(例如根据样本难度,自动选择推理深度,简单样本early exit)
BigNAS系列的文章可以看做是对计算资源的自适应;条件计算可以看做是一种对样本的自适应,条件计算有时也可以对计算资源自适应(资源不足,early exit / fewer branch)
ensemble
- 模型集成:最简单的模型集成是针对相同的任务、相同的输入设计几个不同的网络(甚至有的时候直接取训练过程中的若干checkpoint,这种集成方法称为快照集成。
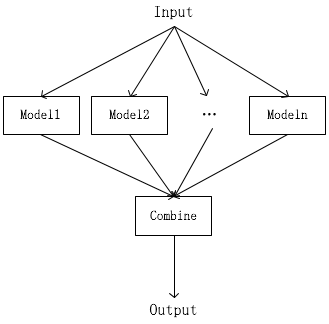
- 分支集成:模型集成的规模往往有些庞大,退而求其次我们可以共享一部分浅层特征,然后产生若干分支,最后融合各分支提取的特征达到集成的目的
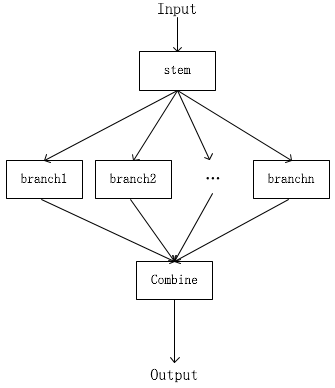
- 带条件计算的分支集成:有的时候可能有的分支的“小专家”对一些样本不太擅长,我们可以选择不听取他们的意见

从上到下,集成的粒度越来越细:
- 多个model进行集成 √
- head-1个stage-tail,1个stage中的多个branch进行集成 √
- head-1个stage-tail,1个stage中的多个branch进行条件集成 √
- head-N个stage-tail,每个stage中的多个branch都独立进行条件集成
- 多个layer,每个layer都独立进行条件集成(本文)
但所有集成方式不可避免的带来参数量(计算量)的N倍增加,本文的方法一样会带来N倍的参数量增加,但计算量和原始模型是相当的(存储资源比计算资源更容易获得)。
attention
不同样本有不同的关注区域,让网络对不同样本关注不同的东西
Motivation
One fundamental assumption is that convolutional kernels should be shared for all examples in a dataset.
current approaches to increasing model capacity are computationally expensive.
Contribution
Method
CondConv
CondConv 可以看成是在layer粒度的条件集成,每个CondConv layer都有n套权重: (W_1 ... W_n)
input先和n套权重分别卷积,再combine(类似 googlenet 中的 multi-branch)
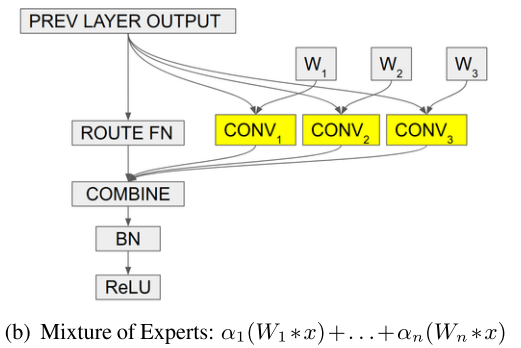
由于这n个卷积运算(一种线性运算)的输入都是相同的,那么如果combine也是线性运算(如加权求和),则这组运算就可以重新表示为先combine再执行一个卷积运算(多个branch卷积整合成一个,如repVGG就是把2个卷积branch合成一个):
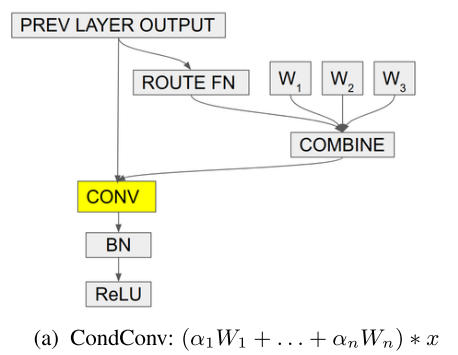
这样就把N倍的卷积计算量减少到1倍的卷积计算量+少量的线性组合计算量,且两者是完全等价的!
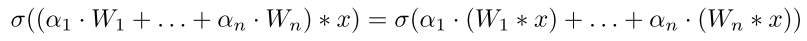
(alpha) 如何得到?
- routing function: (alpha) 是输入x的函数,其中R是 fc 层的参数),将 pool(x) ==> n dim
- (α=r(x)=sigmoid(fc(avg pool(x))))
如果 α 是定值的话,cond conv就等价于普通的conv
Experiments
expert num & width mult
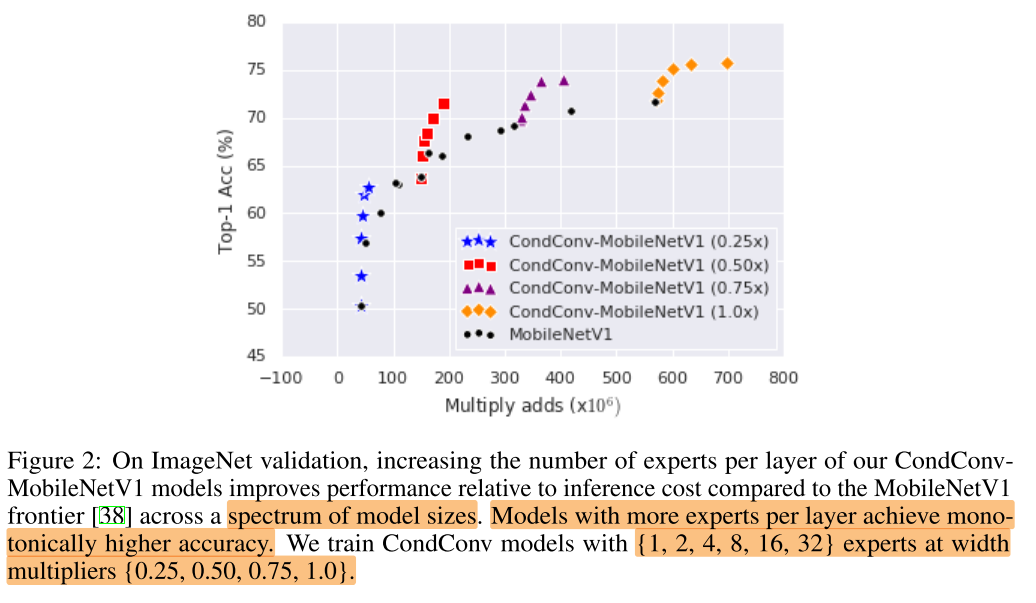
集成的 expert 越多,性能越好,且在不同规模的网络上都有效
plug-in
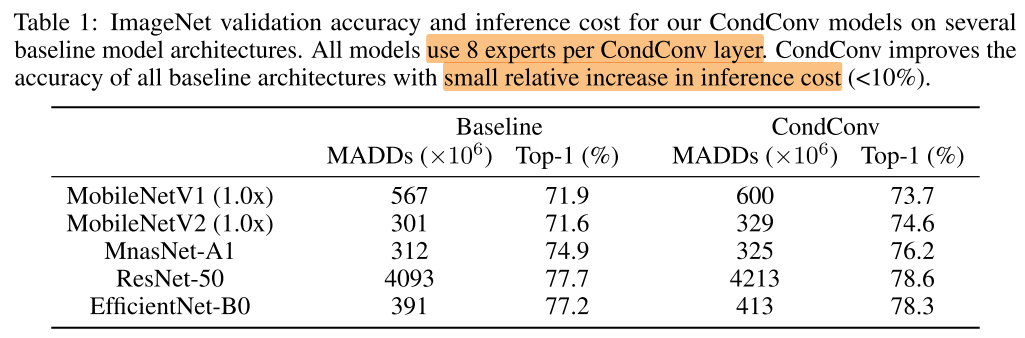
与现有的方法结合,都可以提高性能,即插即用
Ablation Study
plug-in layer
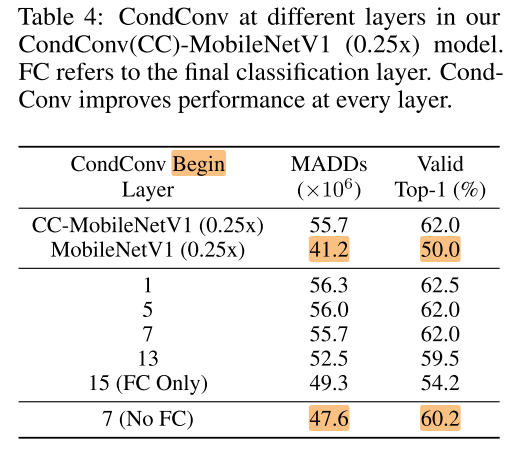
CC-mb1只在第7层开始使用cond conv
fc 层替换为 cond conv 会带来较多的计算开销
routing function
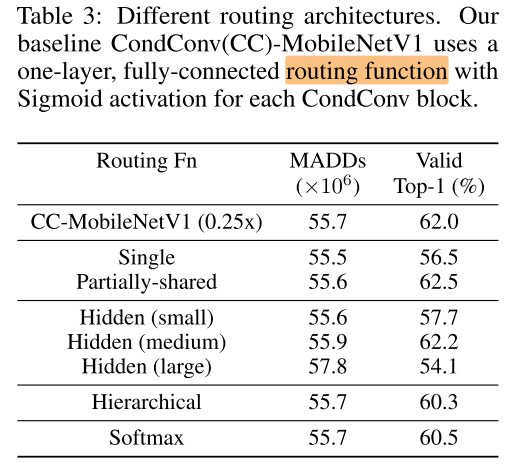
- CC-mb1:(第7层开始)每层都有单独的一组R参数(一个fc) (α=r(x)=sigmoid(fc(avg pool(x))))
- single:(第7层开始)共用一组R
- partially-share:(第7层开始)部分层共享
- hidden:fc层的宽度
- Hierarchical:
- (α^l=r^l(x)=sigmoid(fc(avg_pool(x)+α^{l-1})))
- softmax: (α=r(x)=softmax(fc(avg pool(x))))
mean routing weight

不同层:越深的层,routing weight 对不同的类的差异越大
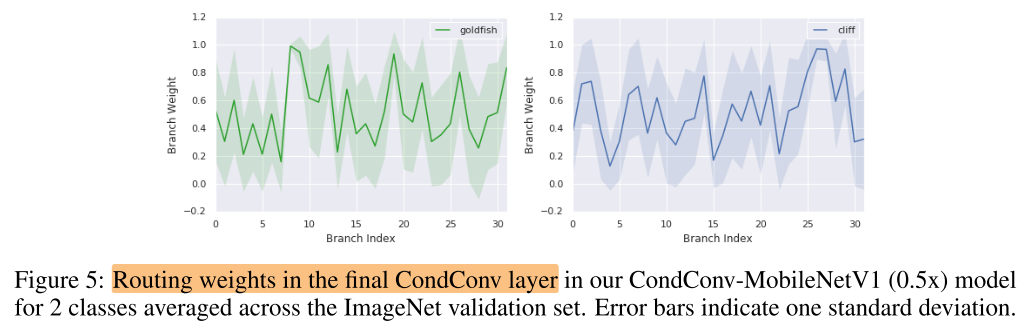
同一层,不同类:同一层不同类所激活的 branch/expert 是不同的

同一层的4个 branch/expert 激活值最大的10张样本,不同的expert对不同类型的样本感兴趣
Conclusion
Summary
pros:
- 从注意力机制的角度,不同的卷积核对不同样本有不同的注意力
- 从条件计算的角度,将条件计算的粒度细化到了layer级别,使得每个样本实际推理使用的conv都各不相同
- 从集成的角度,cond conv模型集成了多个(32个)expert,通过多卷积branch等价融合的方法,计算量减少到一倍;虽然模型参数量急剧增加,但存储空间一般比计算内存更容易获得
- 提升网络的表达容量,比提升模型计算量(宽度/深度)更重要,once for all 中共享
cons:
- 本文是通过N倍的参数量来提高网络表达容量,参数量太大(32倍),能否通过1倍的参数量,通过线性/非线性的变换来得到多倍的表达容量(类似once for all 中共享7x7 center的做法其实也是用1倍的参数量+fc,来得到n倍的网络表达容量)