BigNAS
2020-ECCV-BigNAS Scaling Up Neural Architecture Search with Big Single-Stage Models
来源:ChenBong 博客园
- Institute:Google Brain
- Author:Jiahui Yu
- GitHub:/
- Citation: 20+
Introduction
训练supernet,直接采样子网即可直接部署
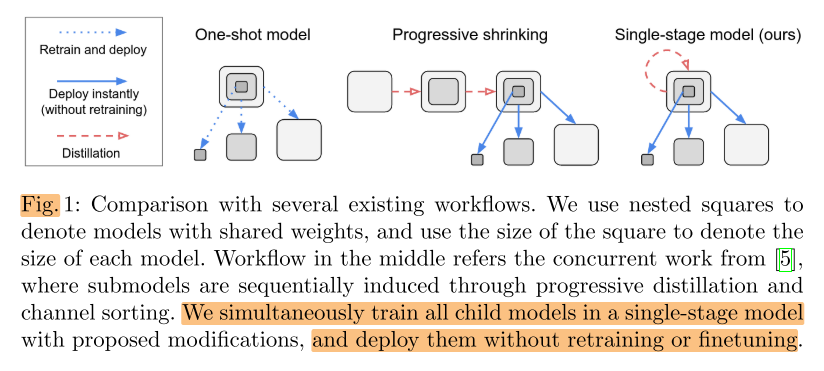
Motivation
- 2019-ICLR-Slimmable Neural Networks
- scale 维度:
- channel num(network-wise,top n index)
- 每个 batch:
- channel num(固定的4个:0.25x,0.5x,0.75x,1.0x)
- scale 维度:
- 2019-ICCV-US-Net
- scale维度:
- channel num(network-wise,top n index)
- 每个 batch:
- channel num(随机的4个:min,random×2,max)
- inplace distillation: $CE(max, hat y), CE(min, y_{max}), CE(random_{1,2}, y_{max}) $
- scale维度:
- 2020-ECCV-MutualNet
- scale 维度:
- input resolution(network-wise)
- channel num(network-wise,top n index)
- 每个 batch:
- input resolution(相同的1个crop,resize成4个resolution)
- channel num(随机的4个:min,random×2,max)
- inplace distillation: (CE(max, hat y), KLDiv(random_{1,2}, y_{max}), KLDiv(min, y_{max}))
- scale 维度:
- 2020-ECCV-RS-Net
- scale维度:
- input resolution(network-wise)
- 每个 batch:
- input resolution(相同的1个crop,resize成S个resolution:(S_1>S_2>...>S_N))
- inplace distillation: $CE(ensemble, hat y), CE(S_1, ensemble), CE(S_2, S_1)... $
- scale维度:
- 2020-ICLR-Once for All:
- scale维度:
- input resolution(network-wise)
- channel num(layer-wise,top L1 select)
- layer num(stage-wise,top n select)
- kernel size(layer-wise,center+layer's fc)
- train full
- KD: (CE(ps_1, full), CE(ps_2, ps_1)...)
- scale维度:
- 2020-ECCV-BigNAS
- scale维度:
- input resolution(network-wise)
- channel num(layer-wise,top n select)
- layer num(stage-wise,top n select)
- kernel size(layer-wise,center)
- 每个 batch:
- input resolution(相同的1个crop,resize成4种resolution)
- 每个batch sample 3个child model (full, rand1, rand2)
- inplace distillation: (CE(full, hat y), KLDiv(random_{1,2}, y_{full}))
- scale维度:
Contribution
Method
Training a High-Quality Single-Stage Model
Sandwich Rule (previous work)
Inplace Distillation (previous work)
Batch Norm Calibration (previous work)
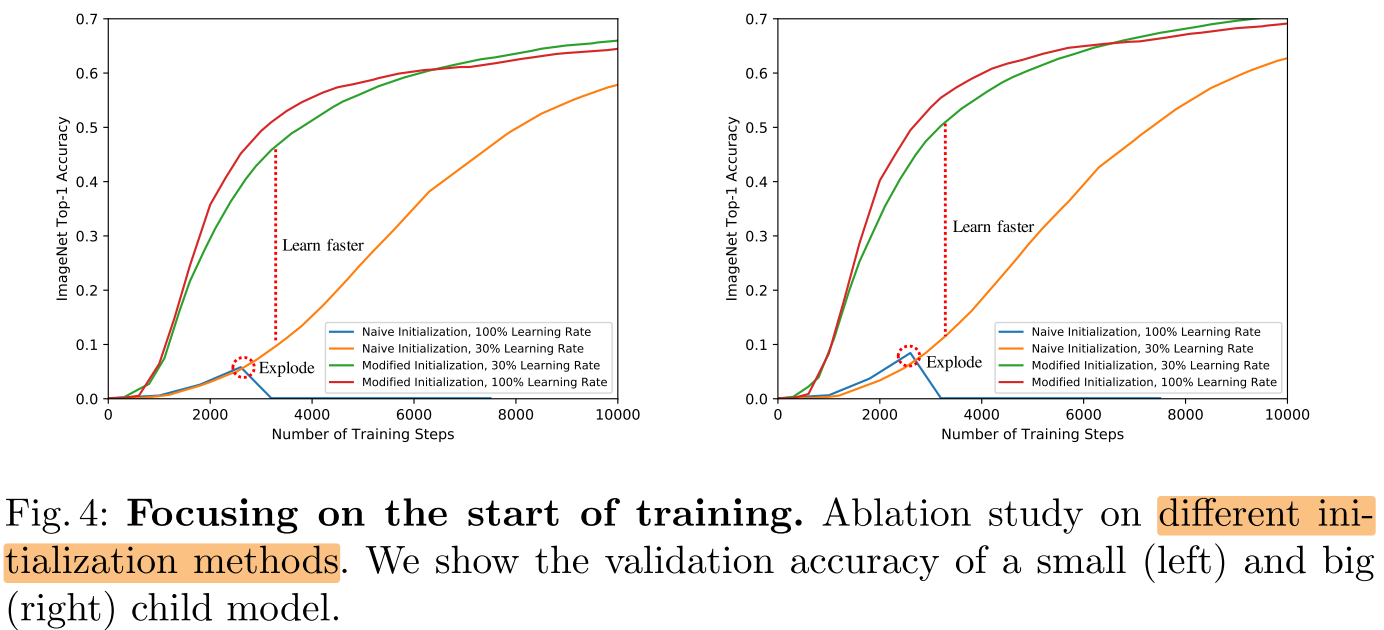
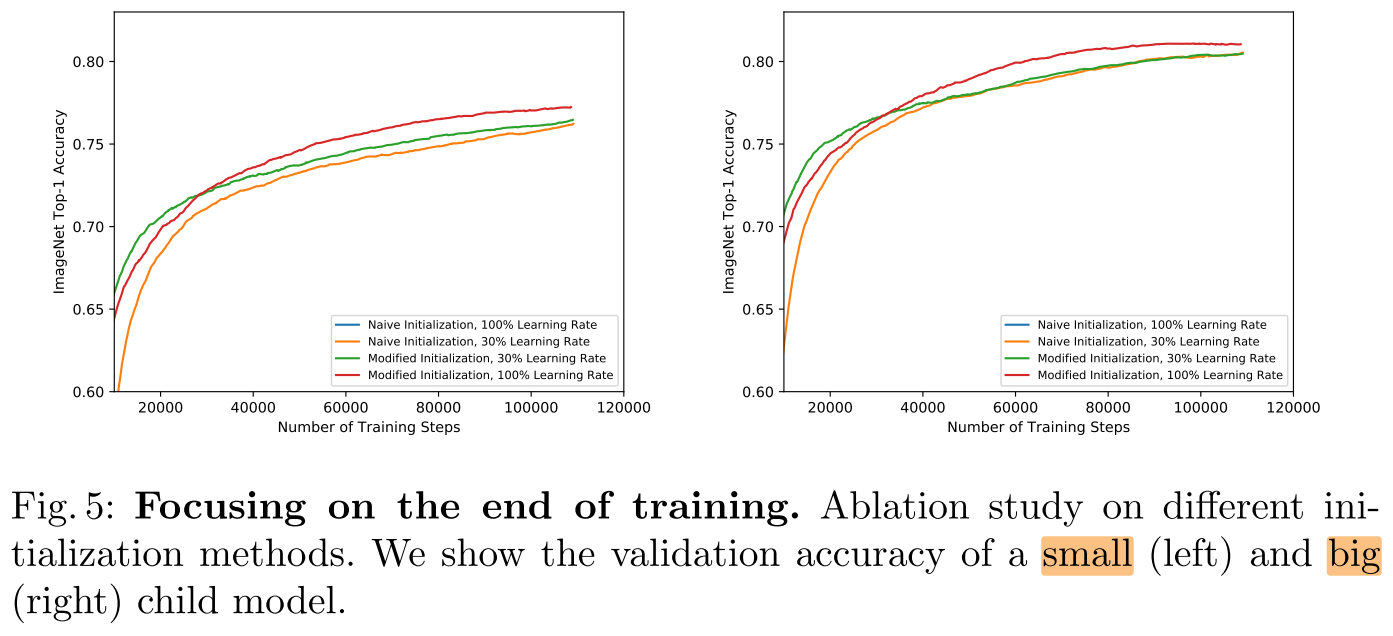
Initialization
- He Initialization: both small (left) and big (right) child models drops to zero after a few thousand training steps during the learning rate warming-up.
- The single-stage model is able to converge when we reduce the learning rate to the 30%.
- If the initialization is modified according to Section 3.1, the model learns much faster at the beginning of the training (shown in Figure 4), and has better performance at the end of the training (shown in Figure 5).
Section 3.1:
we initialize the output of each residual block (before skip connection) to an allzeros tensor by setting the learnable scaling coefficient γ = 0 in the last Batch Normalization [20] layer of each residual block.
We also add a skip connection in each stage transition when either resolutions or channels differ (using 2 × 2 average pooling and/or 1 × 1 convolution if necessary) to explicitly construct an identity mapping.
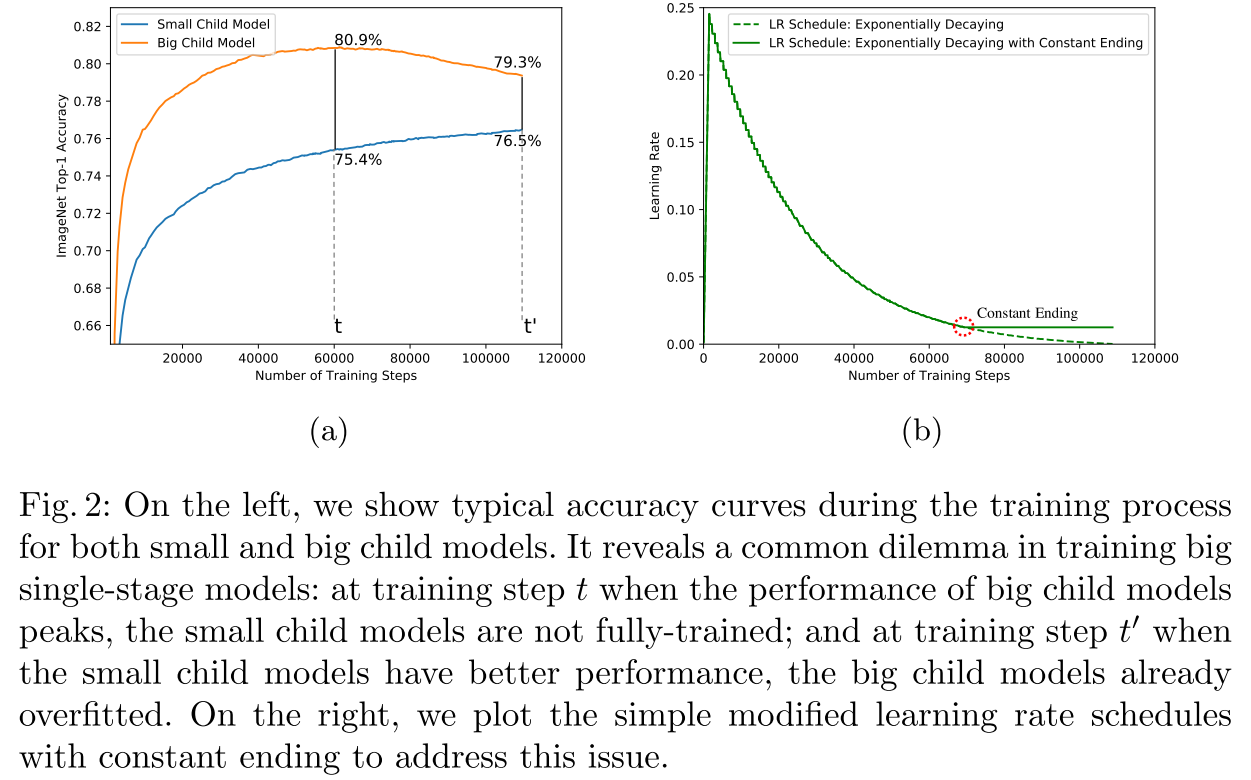
Convergence Behavior
small child models converge slower and need more training
==> exponentially decaying with constant ending.
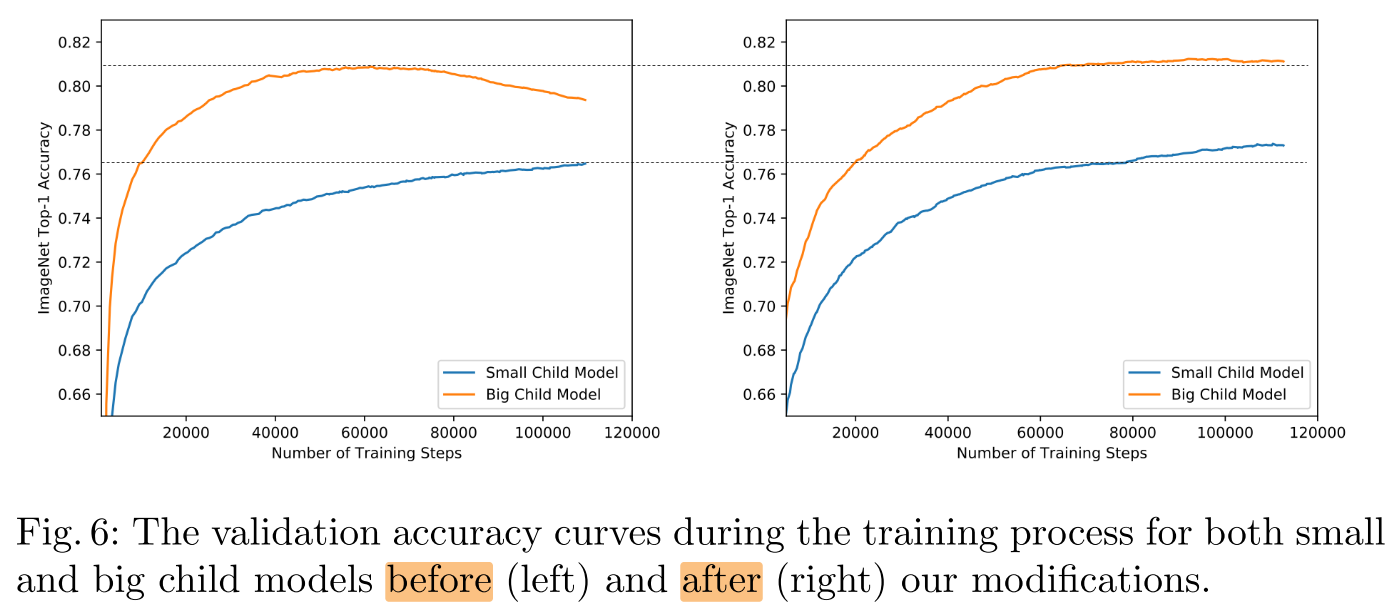
Regularization
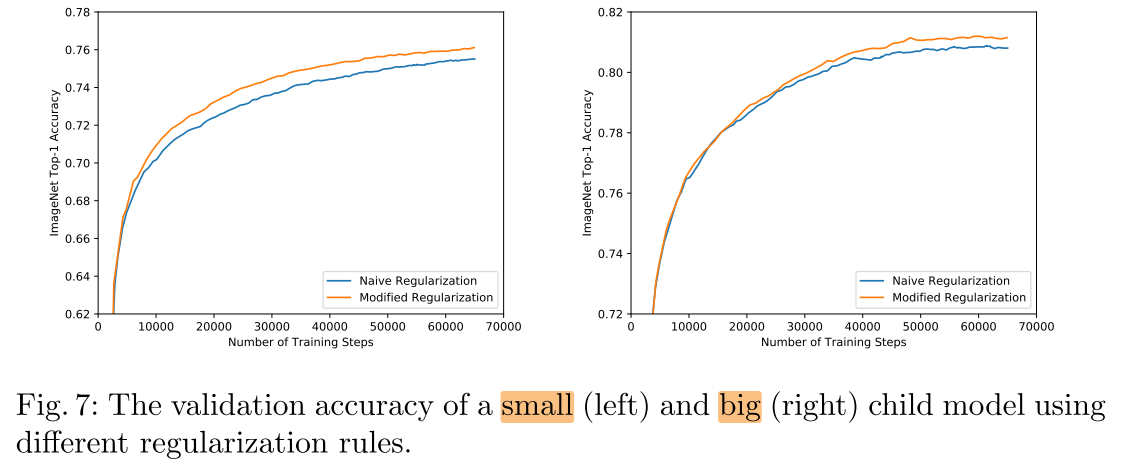
we compare the effects of the regularization (weight decay and dropout) between two rules:
- applying regularization on all child models
- applying regularization only on the full network
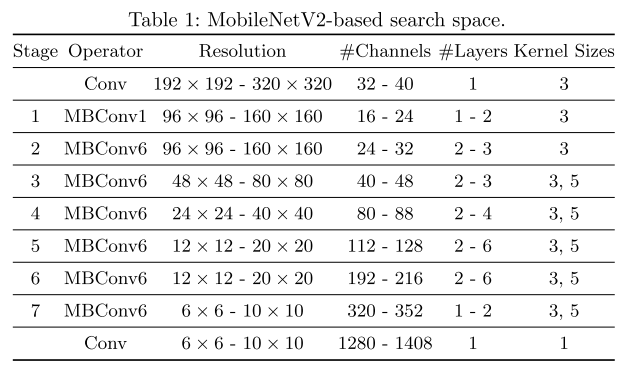
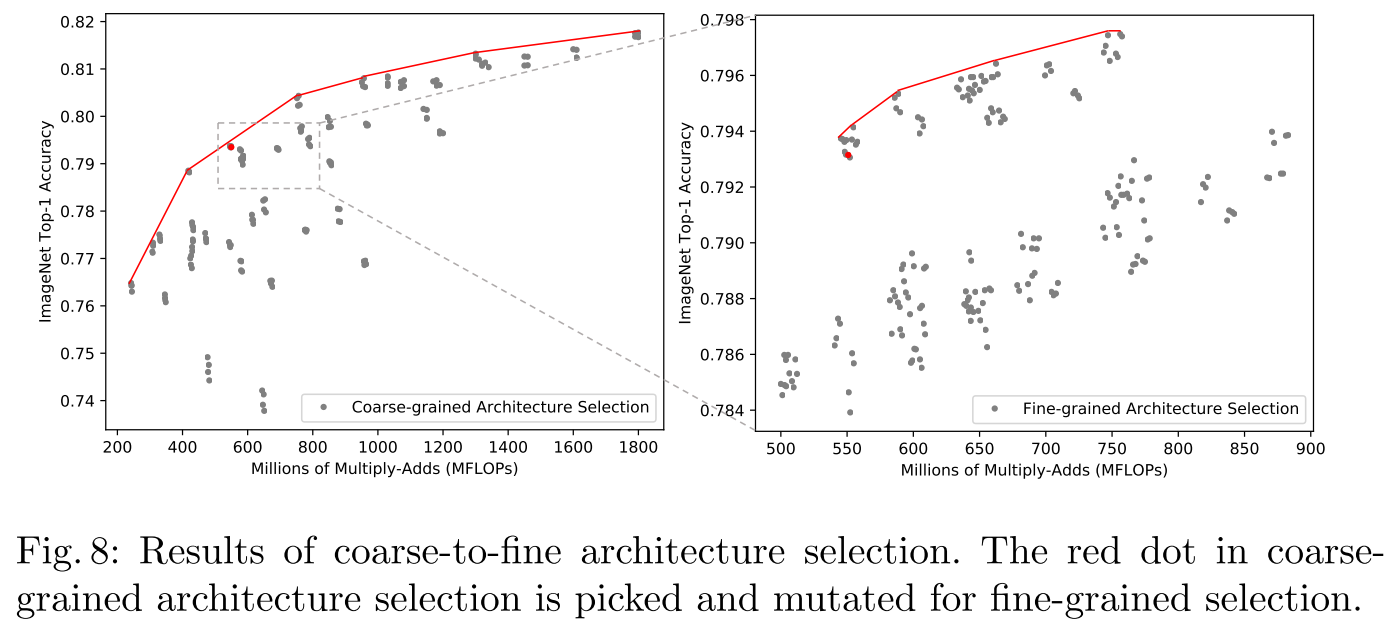
Coarse-to-fine Architecture Selection
scale维度:
- input resolution(network-wise)
- channel num(layer-wise,top n select)
- layer num(stage-wise,top n select)
- kernel size(layer-wise,center)
we pre-define :
five input resolutions (network-wise, {192, 224, 256, 288, 320}),
four depth configurations (stage-wise),
two channel configurations (stage-wise),
four kernel size configurations (stage-wise)
Experiments
Cost
8×8 TPUv3
To train a single-stage model, it roughly takes 36 hours.
ImageNet
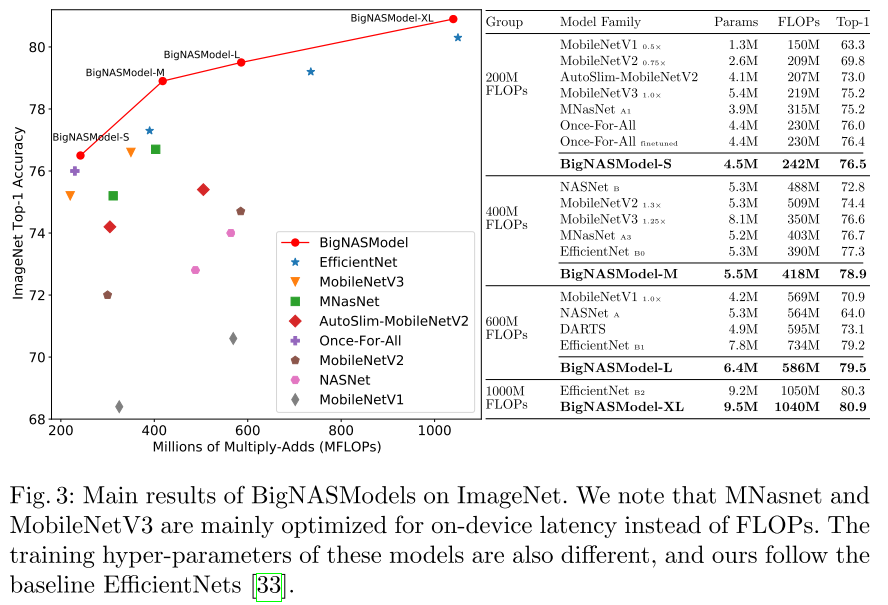
ablation study
Finetuning child models

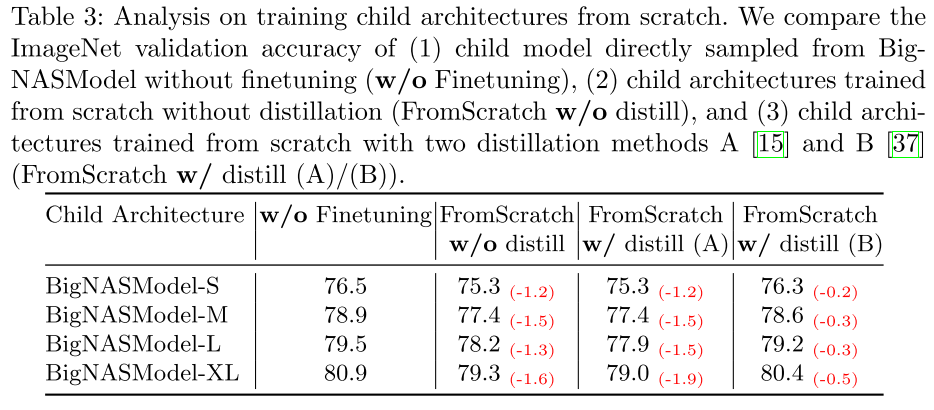
Training child from scratch
Conclusion
Summary
-
将one-shot超网训练做到比较完善的一个工作,相比之下ofa还需要多个stage,分阶段蒸馏/fine-tune,不够one-shot
-
将无需 fine-tune 的 motivation 贯彻到底
-
整个pipeline之所以work的主要原因应该是 top n select + self KD 的超网训练方式,其他的部分都是一两个点的小修小补的工作
-
训练开销也在可接受的范围内(和once for all 比起来)
-
fine-tune和train from scratch child model都无法再提高模型性能,有点反直觉,说明这个超网训练的pipeline确实对child model非常有益?
-
搜索空间似乎经过精心设计
-
没有开源