以前没接触过MPI编程,对并行计算也没什么了解。朋友的期末课程作业让我帮忙写一写,哎,实现结果很一般啊。最终也没完整完成任务,惭愧惭愧。
问题大概是利用MPI完成矩阵和向量相乘。输入:Am×n,Bn×1 ,输出:Cm×1
附:程序中定义m=400,n=100,矩阵和向量的取值为随意整型数,为了便于显示并行效果,循环完成该计算任务100000次。
实现过程
1.实验环境:WINDOWS8.1 64位+ MPICH + VS2013 / kubuntu 14.04 + mpich
2.解题思路:采用带状划分的并行算法,同时用主从结构,设处理器个数为p,对矩阵A按行划分成p块,每块含有连续的m行向量,m = N/p,分别存放在标号0...p-1的处理器中,同时将向量B广播给所有处理器。各处理器并行地进行矩阵向量乘积操作,最后返回结果。
运行代码如下:
#include "mpi.h" #include <stdio.h> #include <stdlib.h> const int rows = 400; //the rows of matrix const int cols = 100; //the cols of matrix int main(int argc, char* argv[]) { int i, j, k, myid, numprocs, anstag; int A[rows][cols], B[cols], C[rows]; int masterpro,buf[cols], ans,cnt; double starttime,endtime; double tmp,totaltime; MPI_Status status; masterpro = 0; MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &myid); MPI_Comm_size(MPI_COMM_WORLD, &numprocs); for(cnt = 0; cnt < 100000; cnt++){ if(numprocs < 2){ printf("Error:Too few processes! "); MPI_Abort(MPI_COMM_WORLD,99); } if(myid == masterpro){ starttime = MPI_Wtime(); for (i = 0; i < cols; i++) { B[i] = rand()%10; for (j = 0; j < rows; j++) { A[j][i] = rand()%10; } } //bcast the B vector to all slave processor MPI_Bcast(B, cols, MPI_INT, masterpro, MPI_COMM_WORLD); //partition the A matrix to all slave processor for (i = 1; i < numprocs; i++) { for (k = i - 1; k < rows; k += numprocs - 1) { for (j = 0; j < cols; j++) { buf[j] = A[k][j]; } MPI_Send(buf, cols, MPI_INT, i, k, MPI_COMM_WORLD); } } } else{ //starttime = MPI_Wtime(); MPI_Bcast(B, cols, MPI_INT, masterpro, MPI_COMM_WORLD); //every processor receive the part of A matrix,and make Mul operator with B vector for ( i = myid - 1; i < rows; i += numprocs - 1){ MPI_Recv(buf, cols, MPI_INT, masterpro, i, MPI_COMM_WORLD, &status); ans = 0; for ( j = 0; j < cols; j++) { ans += buf[j] * B[j]; } //send back the result MPI_Send(&ans, 1, MPI_INT, masterpro, i, MPI_COMM_WORLD); } //endtime = MPI_Wtime(); //tmp = endtime-starttime; } if(myid == masterpro){ //receive the result from all slave processor for ( i = 0; i < rows; i++) { MPI_Recv(&ans, 1, MPI_INT, MPI_ANY_SOURCE, MPI_ANY_TAG, MPI_COMM_WORLD, &status); //sender = status.MPI_SOURCE; anstag = status.MPI_TAG; C[anstag] = ans; } //print the result /* for (i = 0; i < rows; i++) { printf("%d ",C[i]); if((i+1)%20 == 0) printf(" "); } */ } } endtime = MPI_Wtime(); totaltime = endtime-starttime; //printf("cost time:%f s. ",tmp); //MPI_Reduce(&tmp,&totaltime,1,MPI_DOUBLE,MPI_SUM,0,MPI_COMM_WORLD); if(myid == masterpro) printf("total time:%f s. ",totaltime); MPI_Finalize(); return 0; }
测试结果:单机多进程运行时,由于进程资源分配和cpu使用率会随着进程数增加而减少,所以时间反而会久一点。在linux上测试时,发现2进程运行时,CPU使用率能达100%,4进程运行时平均50%左右。

联机测试过程,还存在一些问题,自己也没处理好,这里就不误导大家了。
环境搭建
Linux环境 kubuntu 14.04
(1)安装:
sudo apt-get install mpd sudo apt-get install mpich
(2)编译运行
mpicc -o matrixvec matrixvec.c mpirun -np 2 ./matrixvec
Windows环境
主要是MPICH3.1.3+VS2013搭建过程的一些注意问题。
(1)下载安装:在MPICH官网下载相应的包,虽然系统是64位,但实际测试过程中,发现64为的mpich3.1.3无法运行,重新安装32位版本后才正常,所以建议安装32位版本。同时在环境变量PATH添加mpich/bin的路径。
(2)注册账号:运行安装目录下的/bin/wmpiregister.exe,输入系统用户名、密码。注意,这里注册的是你在使用的电脑系统的用户名和密码。

(3)运行测试:运行安装目录下的/bin/wmpiexec.exe,选择Application为安装目录下examplescpi.exe(一个计算圆周率的例子程序)
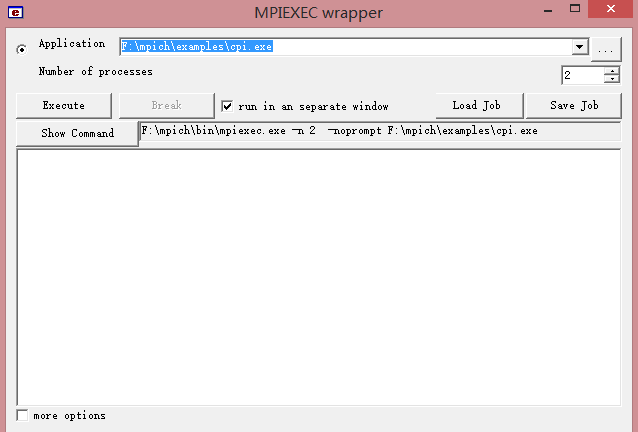
若遇到下例问题,用管理员权限打开控制台,输入smpd -install即可

下面用VS2013实现简单的mpi程序作为示例,分享一下配置过程。
(1)打开VS2013,新建项目及源文件
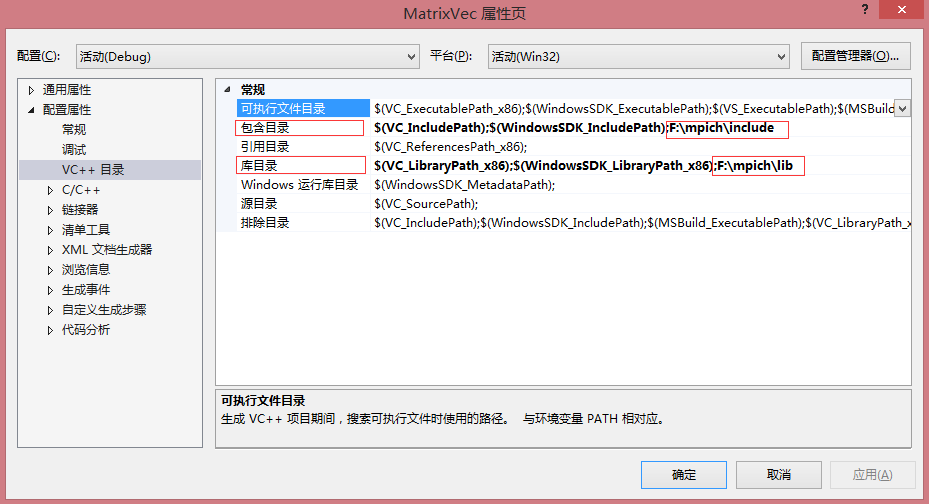
(2)配置项目属性,引入mpi头文件和库
因为VC的IO库与MPI头文件中的宏定义有冲突,所以需要预定义一个MPICH_SKIP_MPICXX宏,使得预编译时跳过MPICXX定义,同时可以添加_CRT_SECURE_NO_WARNINGS。

代码生成,设置运行库为多线程,在如下位置选择“Multi-threaded Debug (/MTd)”,可以通过下拉单选择

链接器添加连接库,在如下位置添加“mpi.lib”

配置完成,通过VS编译mpi程序,用wmpiexec.exe打开生成的exe文件便可运行,或者用命令行形式。
相关参考:
1.MoreWindows Blog:Windows系统下搭建MPI(并行计算)环境
2.Romi-知行合一:Windows下MPI的环境搭建及机群测试