一、简介:
session是一种管理用户状态和信息的机制,与cookie的不同的是,session的数据是保存在服务器端。说的明白点就是session相当于一个虚拟的浏览器,在这个浏览器上处于一种保持登录的状态。
cookie是用来存储一些用户信息以便让服务器辨别用户身份的(大多数需要登录的网站上面会比较常见),比如cookie会存储一些用户的用户名和密码,当用户登录后就会在客户端产生一个cookie来存储相关信息,这样浏览器通过读取cookie的信息去服务器上验证并通过后会判定你是合法用户,从而允许查看相应网页。当然cookie里面的数据不仅仅是上述范围,还有很多信息可以存储是cookie里面,比如sessionid等。
二、特点:
1、requests库的session对象能够帮我们跨请求保持某些参数,也会在同一个session实例发出的所有请求之间保持cookies
2、requests库的session对象还能为我们提供请求方法的缺省数据,通过设置session对象的属性来实现
# 创建一个session对象
s = requests.Session()
# 两种发送请求的方法
s.get():请求指定的页面信息,并返回实体主体。
s.post():向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST 请求可能会导致新的资源的建立和/或已有资源的修改。
以及方法里的几种参数
post(url, headers=headers, data=data, cookies=cookie, timeout=3)分别是地址、相应头、提交的表达数据、cookies、响应超时时间
#几种参数的意义和获取方法(这里以爬取拉钩网实例,借鉴大佬原文:https://www.cnblogs.com/sui776265233/p/11146969.html#_label0
进入拉勾网官网
输入你想搜索的工作岗位 我这里是输入的是:python工程师 。然后右键点击检查或者F12,,使用检查功能查看网页源代码,当我们点击下一页观察浏览器的搜索栏的url并没有改变,这是因为拉勾网做了反爬虫机制, 职位信息并不在源代码里,而是保存在JSON的文件里,因此我们直接下载JSON,并使用字典方法直接读取数据.即可拿到我们想要的python职位相关的信息,

待爬取的python工程师职位信息如下:

为了能爬到我们想要的数据,我们要用程序来模拟浏览器来查看网页,所以我们在爬取的过程中会加上头信息,头信息也是我们通过分析网页获取到的,通过网页分析我们知道该请求的头信息,以及请求的信息和请求的方式是POST请求,这样我们就可以该url请求拿到我们想的数据做进一步处理


#url(你想爬取数据的地址):https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false
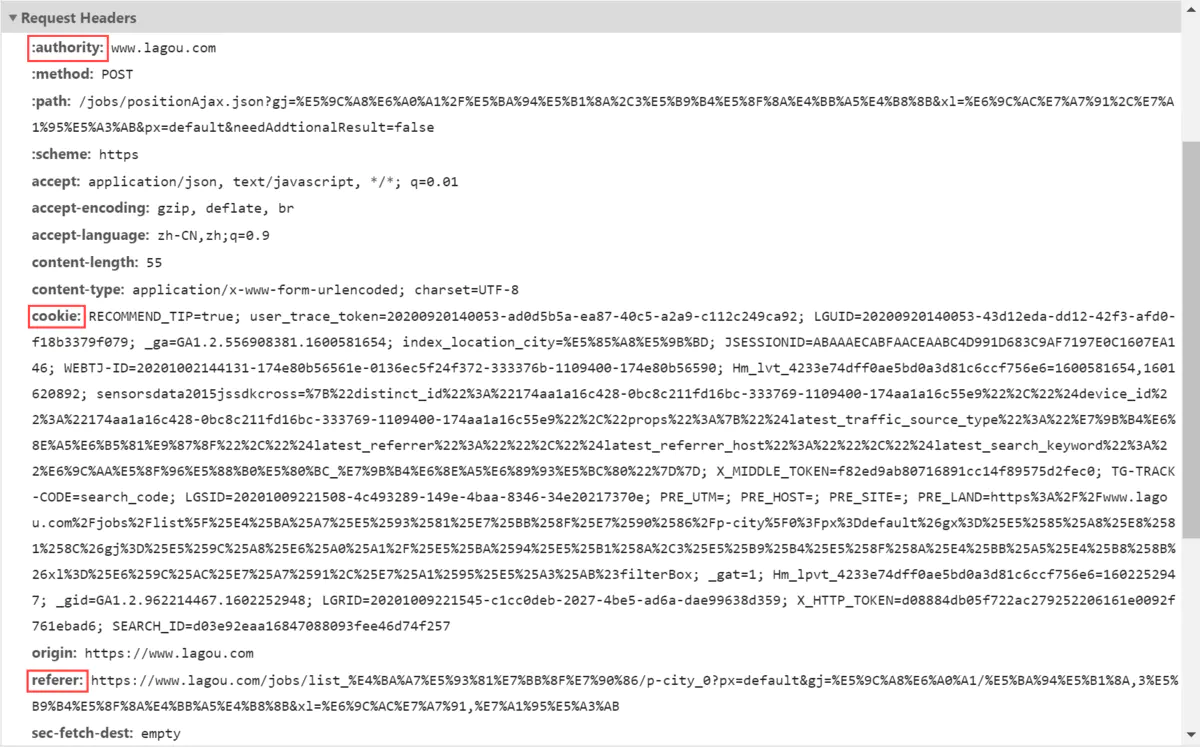
#Request Headers
(请求头信息,我们爬取访问网站时候,需要带着请求访问,那又一部分的请求是放在请求头的,如UA ,cookies ,token 等等很多属性会放在里面进行访问!如果这里没有构造好的话,容易被网站识别为爬虫,被拒绝访问。)
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36', 'Host': 'www.lagou.com', 'Referer': 'https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90?labelWords=&fromSearch=true&suginput=', 'X-Anit-Forge-Code': '0', 'X-Anit-Forge-Token': 'None', 'X-Requested-With': 'XMLHttpRequest' }
Authority:表示服务器的域名以及服务器所监听的端口号。如果所请求的端口是对应的服务的标准端口(80),则端口号可以省略。
Cookie:也作复数Cookies。它的主要功能是维持当前访问会话。当我们输入用户名和密码成功登录某个网站后,服务器会用会话保存登录状态信息,后面我们每次刷新或请求该站点的其他页面时,会发现都是登录状态,这就是 Cookies 的功劳。
Referer:此内容用来标识这个请求是从哪个页面发过来的,通常在访问链接时,都要带上Referer字段,服务器会进行来源验证,后台通常会用此字段作为防盗链的依据。
User-Agent:后台通常会通过此字段判断用户设备类型、系统以及浏览器的型号版本。如果不加此字段,很可能会被识别出为爬虫。
注:headers各属性作用https://blog.csdn.net/philos3/article/details/76946029
#data(常见的form表单可以直接使用data参数进行报文提交,模拟用户操作提交的数据):
如果像是在网站搜索时
data = { 'first': 'true', 'pn': num, 'kd': 'python工程师'}
pn是拉勾网搜索后显示数据栏的下标页数

kd则是我们搜索框输入的想查询的岗位
也可能是登录时
formdata = { 'email':'admin@wuaics.cn', 'password':'你的密码', '_xsrf':_xsrf }
包括需要输入的用户名、密码以及像_xsrf这种参数的页面校检码(如何获取这种参数下面两篇文章有讲解)
这里有两篇模拟登录的例子https://blog.csdn.net/xiaozhanger/article/details/78034015和https://www.jianshu.com/p/3c00d57d0244
#cookie(开头简介有介绍是干嘛的)
模拟登录时
也可以是不用data用设置cookies
例子:https://www.cnblogs.com/qican/p/11153824.html
我运行后的测试:
# coding:utf-8 import requests # 保持登录状态 s = requests.session() url = 'https://www.baidu.com/' # 请求头 headers = { "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63" } r = s.post(url,headers=headers) # 查看的cookies值 cooks = { "BDUSS":"", "BAIDUID":"" } # 添加登录所携带的cookies c = requests.cookies.RequestsCookieJar() c.set("BDUSS",cooks["BDUSS"]) c.set("BAIDUID",cooks["BAIDUID"]) s.cookies.update(c) # 判断是否登录成功 r2 = s.get(url,headers=headers) if '' in r2.text: print('登录成功') else: print("登录失败")

爬取拉勾网时
除了data提交的表单数据外 我们可能还需要一些其他的数据用户名、密码隐藏参数
这时候我们就需要去到我要爬取的的网页获取此时的cookies
1、可以手动赋值粘贴下来

2、也可以
url1 = 'https://www.lagou.com/jobs/list_python%E5%BC%80%E5%8F%91%E5%B7%A5%E7%A8%8B%E5%B8%88?labelWords=&fromSearch=true&suginput=' s.get(url=url1, headers=headers, timeout=3) cookie = s.cookies
url1就是上面图里的

#响应状态码判断
r.raise_for_status()
理解Response类非常重要,Response这样的一个对象返回了所有的网页内容,那么它也提供了一个方法,叫raise_for_status(),这个方法是专门与异常打交道的方法,该方法有这样一个有趣的功能,它能够判断返回的Response类型状态是不是200。如果是200,他将表示返回的内容是正确的,如果不是200,他就会产生一个HttpError的异常。
#响应编码设置
res.encoding = 'utf-8'
请求发出后,Requests 会基于 HTTP 头部对响应的编码作出有根据的推测。当你访问 r.text 之时,Requests 会使用其推测的文本编码。你可以找出 Requests 使用了什么编码,并且能够使用r.encoding 属性来改变它:
#JSON 响应内容
Requests 中也有一个内置的 JSON 解码器,助你处理 JSON 数据,可以通过下列代码获取
r.json()
如果 JSON 解码失败, r.json() 就会抛出一个异常。例如,响应内容是 401 (Unauthorized),尝试访问 r.json() 将会抛出 ValueError: No JSON object could be decoded 异常。
需要注意的是,成功调用 r.json() 并**不**意味着响应的成功。有的服务器会在失败的响应中包含一个 JSON 对象(比如 HTTP 500 的错误细节)。这种 JSON 会被解码返回。要检查请求是否成功,请使用 r.raise_for_status() 或者检查 r.status_code 是否和你的期望相同。
代码示例:
import requests url = ' https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false' def get_json(url, num): """ 从指定的url中通过requests请求携带请求头和请求体获取网页中的信息, :return: """ url1 = 'https://www.lagou.com/jobs/list_python%E5%BC%80%E5%8F%91%E5%B7%A5%E7%A8%8B%E5%B8%88?labelWords=&fromSearch=true&suginput=' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36', 'Host': 'www.lagou.com', 'Referer': 'https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90?labelWords=&fromSearch=true&suginput=', 'X-Anit-Forge-Code': '0', 'X-Anit-Forge-Token': 'None', 'X-Requested-With': 'XMLHttpRequest' } data = { 'first': 'true', 'pn': num, 'kd': 'python工程师'} s = requests.Session() print('建立session:', s, ' ') s.get(url=url1, headers=headers, timeout=3) cookie = s.cookies print('获取cookie:', cookie, ' ') res = requests.post(url, headers=headers, data=data, cookies=cookie, timeout=3) res.raise_for_status() res.encoding = 'utf-8' page_data = res.json() print('请求响应结果:', page_data, ' ') return page_data print(get_json(url, 1))
