一、创建一个scrapy项目
在开始爬取之前,我们首先要创建一个scrapy项目,在命令行输入一下命令即可创建。
scrapy startproject xxx
二、编写第一个scrapy蜘蛛
创建第一个scrapy蜘蛛文件
上面我们已经成功创建了一个scrapy 项目,在spiders目录下面,有一个scrapy 文档,下面来创造一只scrapy蜘蛛
文件名这里我就取名为:cjj_spider.py (保存在pachong/spiders目录下),已经成功创建了一个scrapy蜘蛛文件,我们要爬取哪个网站、爬取这个网站的神马数据,统统在这个文件里面编写。
编写第一个蜘蛛
首先介绍下scrapy遵守的规则:
1、首先我们需要创建一个类,并继承scrapy的一个子类:scrapy.Spider 或者是其他蜘蛛类型,除了Spider还有很多牛X的蜘蛛类型;
2、然后定义一个蜘蛛名,name=“”
后面我们运行的话需要用到;
3、定义我们需要爬取的网址,没有网址蜘蛛肿么爬,所以这是必须的
4、继承scrapy的一个方法:start_requests(self),这个方法的作用就是通过上面定义的链接去爬取页面,简单理解就是下载页面。
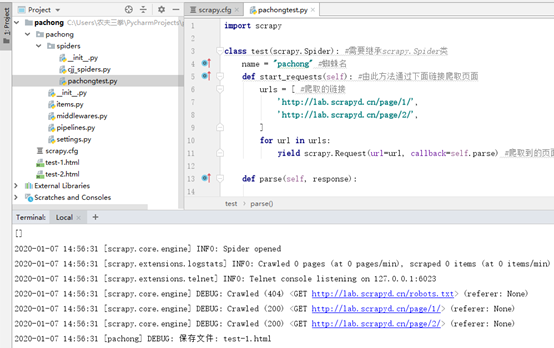
import scrapy
class test(scrapy.Spider): #需要继承scrapy.Spider类
name = "pachong" # 定义蜘蛛名
def start_requests(self): # 由此方法通过下面链接爬取页面
# 定义爬取的链接
urls = [
'http://lab.scrapyd.cn/page/1/',
'http://lab.scrapyd.cn/page/2/',
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse) # 爬取到的页面如何处理?提交给parse方法处理
def parse(self, response):
'''
start_requests已经爬取到页面,那如何提取我们想要的内容呢?那就可以在这个方法里面定义。
这里的话,并木有定义,只是简单的把页面做了一个保存,并没有涉及提取我们想要的数据,后面会慢慢说到
也就是用xpath、正则、或是css进行相应提取,这个例子就是让你看看scrapy运行的流程:
1、定义链接;
2、通过链接爬取(下载)页面;
3、定义规则,然后提取数据;
'''
page = response.url.split("/")[-2] # 根据上面的链接提取分页,如:/page/1/,提取到的就是:1
filename = 'test-%s.html' % page # 拼接文件名,如果是第一页,最终文件名便是:pachong-1.html
with open(filename, 'wb') as f: # python文件操作,不多说了;
f.write(response.body) # 刚才下载的页面去哪里了?response.body就代表了刚才下载的页面!
self.log('保存文件: %s' % filename) # 打个日志
运行蜘蛛
scrapy crawl pachong
我们一定要进入:pachong 这个目录,也就是我们创建的蜘蛛项目目录,以上命令才有效!还有crawl后面跟的是你类里面定义的蜘蛛名,也就是:name,并不是项目名、也不是类名,这些细节希注意!
三、scrapy start_url(初始链接)简写
上面的项目中还有另外一种玩法,也就是可以简化start_requests()这么一个方法,也就是我们可以把这个方法简化掉,然后把初始链接放在一个常量里面,对比一下:简化前,我们需要定义一个方法:start_requests(self),然后经过这个方法不断循环发送请求:
def start_requests(self):
urls = [
'http://lab.scrapyd.cn/page/1/',
'http://lab.scrapyd.cn/page/2/',
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
简化后,以上的链接可以写在:start_urls这个常量里面,是不是省了好多事。
start_urls = [ # 另外一种写法,无需定义start_requests方法
'http://lab.scrapyd.cn/page/1/',
'http://lab.scrapyd.cn/page/2/',
]
但是用简化的方法,我们必须定义一个方法为:def parse(self, response),方法名一定是:parse,这样的话用简写的方式就能愉快的工作了
完整代码如下:
import scrapy
class cjj(scrapy.Spider): #需要继承scrapy.Spider类
name = "pachong" #蜘蛛名
start_urls = [
'http://lab.scrapyd.cn/page/1/',
'http://lab.scrapyd.cn/page/2/',
]
def parse(self, response):
page = response.url.split("/")[-2]
filename = 'cjj-%s.html' % page
with open(filename, 'wb') as f:
f.write(response.body)
self.log('保存文件: %s' % filename)
四、scrapy调试工具:scrapy shell使用方法
scrapy提取数据的几种方式:CSS、XPATH、RE(正则),验证scrapy到底有木有提取到数据的工具,其实说白了就是scrapy调试工具,如果木有它你根本不知道你写的规则到底有木有提取到数据,所以这个工具是个:刚需!其实也很简单,就是在命令行输入下面一行代码而已:
scrapy shell http://lab.scrapyd.cn
scrapy shell 固定格式,后面的话跟的是你要调试的页面,如果是百度就:
scrapy shell http://www.baidu.com
就这样一个格式,其实这段代码就是一个下载的过程,一执行这么一段代码scrapy就立马把我们相应链接的相应页面给拿到了。
比如我们想提取http://www.baidu.com的 title,我们可以在 In[1]: 后面输入:response.css('title') ,然后回车, 立马就得到如下结果:
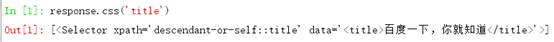
五、scrapy css选择器使用
crapy的第一种数据提取工具:css提取工具的用法。
那我们要提取那个数据呢?就提取:http://lab.scrapyd.cn 这个页面的title里面的数据,我们来看一下他的html结构:
<!DOCTYPE HTML>
<html class="no-js">
<head>
……
<meta name="applicable-device" content="pc,mobile">
<title>爬虫实验室 - SCRAPY中文网提供</title>
……
我们要提取的就是上面:
<title>爬虫实验室 - SCRAPY中文网提供</title>
这个标签里面的数据,我们最终要得到的是:
“爬虫实验室 - SCRAPY中文网提供”
这么一段字符串,那我们就循序渐进的看看我们会怎么操作,会使用哪些函数。
首先我们需要在命令行输入:
scrapy shell http://lab.scrapyd.cn
然后我们继续在命令行输入如下命令:response.css('title') ,这个格式是scrapy固定的格式照着写就行了;response.css('标签名'),标签名的话可以是html标签比如:title、body、div,也可以是你自定义的class标签,这里的话先看我们提取一下简单的,后面我们会讲解如何提取复杂的;
那当我们输入以上命令之后,你会发现已经很给力的提取了一些数据:
>>> response.css('title')
[<Selector xpath='descendant-or-self::title' data='<title>爬虫实验室 - S
CRAPY中文网提供</title>'>]
那你会发现,我们使用这个命令提取的一个Selector的列表,并不是我们想要的数据;那我们再使用scrapy给我们准备的一些函数来进一步提取,那我们改变一下上面的写法,输入:
>>> response.css('title').extract()
['<title>爬虫实验室 - SCRAPY中文网提供</title>']
我们只是在后面加入了:extract() 这么一个函数你就提取到了我们标签的一个列表,更近一步了,那如果我们不要列表,只要title这个标签,要怎么处理呢,看我们的输入:
>>> response.css('title').extract()[0]
'<title>爬虫实验室 - SCRAPY中文网提供</title>'
这里的话,我们只需要在后面添加:[0],那代表提取这个列表中的第一个元素,那就得到了我们的title字符串;这里的话scrapy也给我提供了另外一个函数,可以这样来写,一样的效果:
>>> response.css('title').extract_first()
'<title>爬虫实验室 - SCRAPY中文网提供</title>'
extract_first()就代表提取第一个元素,和我们的:[0],一样的效果,只是更简洁些,至此我们已经成功提取到了我们的title,但是你会发现,肿么多了一个title标签,这并不是你需要的,那要肿么办呢,我们可以继续改变一下以上的输入:
>>> response.css('title::text').extract_first()
'爬虫实验室 - SCRAPY中文网提供'
我们在title后面加上了 ::text ,这代表提取标签里面的数据,至此,我们已经成功提取到了我们需要的数据:
'爬虫实验室 - SCRAPY中文网提供'
总结一下,其实就这么一段代码:
response.css('title::text').extract_first()
六、scrapy提取一组数据
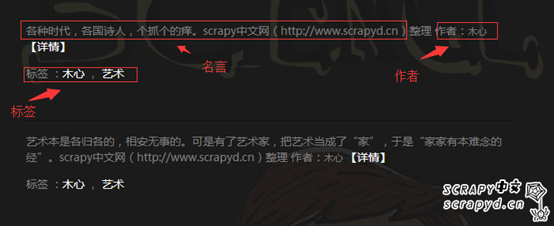
上面的话我们只是在命令行使用,那经过我们的scrapy shell验证正确之后,我们怎么把它写进我们的蜘蛛文件?怎么让它提取数据?那接下来我们来看一下具体的操作。网站:http://lab.scrapyd.cn,们先试着提取里面一条名言的信息,然后进一步提取多条;那一条名言其实包含这么几个部分:名言、作者、标签,如下图:
我们打开源代码,再来看一下对应的HTML标签:
<div class="quote post">
<span class="text">
各种时代,各国诗人,个抓个的痒。scrapy中文网(http://www.scrapyd.cn)整理
</span>
<span>
作者:<small class="author">木心</small>
<a href="http://lab.scrapyd.cn/archives/29.html">【详情】</a>
</span>
<p></p>
<div class="tags">
标签 :
<a href="http://lab.scrapyd.cn/tag/木心/">木心</a> ,
<a href="http://lab.scrapyd.cn/tag/艺术/">艺术</a>
</div>
</div>
那我们要爬取的标签就是:
名言,对应着
class=“text” 标签里面的内容;
作者,对应着
class=“authou” 里面的内容;
标签,对应着
class=“tags” 里面的内容;
因为我们提取的是第一段名言里面的数据,所以我们需要先找到第一段名言,然后保存在一个变量里面,再进一步提取里面的以上数据,那我们要怎么找到第一段名言呢,我们先来看一下HTML结构:
<div class="quote post">
……
</div>
<div class="quote post">
……
</div>
<div class="quote post">
……
</div>
……
我们可以看到,每一段名言都被一个 <div class="quote post">……</div> 包裹,那如果我们要找到第一段名言我们可以这样写:
mingyan1 = response.css('div.quote')[0]
这样的话,我们就把第一段名言保存在:mingyan1 这么一个变量里面了。为什么会有一个:[0] 这表示提取第一段,如果没有这个限制,那我们提取的是本页所有名言。接下来我们就可以来提取里面的:名言内容、作者、标签了。首先提取名言内容,可以这样写:
>>> mingyan1.css('.text::text').extract_first()
'各种时代,各国诗人,个抓个的痒。scrapy中文网(http://www.scrapyd.cn)
整理'
好了,这样我们已经得到了第一段里面的名言内容,上面的表达式里面,我们使用了:.text 这是class选择器,如果是id选择器的话:#text 这些都是HTML的只是,不多说。那接下来我们提取作者:
>>> mingyan1.css('.author::text').extract_first()
'木心'
用的还是class选择器!接下来我们提取标签:
>>> mingyan1.css('.tags .tag::text').extract()
['木心', '艺术']
这里的话,大家可以发现我们用的并非是.extract_first() 而是 extract(),why?应为里面有多个标签,我们并非只是提取一个,而是要把所有标签都提取出来,因此就用了:.extract()
好了,所有内容都已经在scrapy shell 里面验证通过了,那接下来我们把它合并到我们蜘蛛里面,代码如下:
import scrapy
class itemSpider(scrapy.Spider):
name = 'itemSpider'
start_urls = ['http://lab.scrapyd.cn']
def parse(self, response):
mingyan = response.css('div.quote')[0]
text = mingyan.css('.text::text').extract_first() # 提取名言
autor = mingyan.css('.author::text').extract_first() # 提取作者
tags = mingyan.css('.tags .tag::text').extract() # 提取标签
tags = ','.join(tags) # 数组转换为字符串
fileName = '%s-语录.txt' % autor # 爬取的内容存入文件,文件名为:作者-语录.txt
f = open(fileName, "a+") # 追加写入文件
f.write(text) # 写入名言内容
f.write('
') # 换行
f.write('标签:'+tags) # 写入标签
f.close() # 关闭文件操作
七、scrapy 爬取多条数据(scrapy 列表爬取)
我们要爬取多条,也就是把首页里面的都爬了!我们把首页里面,每一个作家的名言都爬取了保存在一个txt里面,然后再用他的名字命名文件。
这里的话,新的知识点木有什么,唯一多了个递归调用,我们来看一下关键变化,原先我们取出一条数据,用的是如下表达式:
mingyan = response.css('div.quote')[0]
我们在后面添加了游标 [0] 表示只取出第一条,那我们要取出全部,那我们就不用加了,直接:
mingyan = response.css('div.quote')
那现在的变量就是一个数据集,里面有多条数据了,那接下来我们要做的就是循环取出数据集里面的每一条数据,那我们看一下怎么做:
mingyan = response.css('div.quote') # 提取首页所有名言,保存至变量mingyan
for v in mingyan: # 循环获取每一条名言里面的:名言内容、作者、标签
text = v.css('.text::text').extract_first() # 提取名言
autor = v.css('.author::text').extract_first() # 提取作者
tags = v.css('.tags .tag::text').extract() # 提取标签
tags = ','.join(tags) # 数组转换为字符串
# 接下来,进行保存
好了,可以看到,关键是:
for v in mingyan:
表示把 mingyan 这个数据集里面的数据,循环赋值给:v ,第一次循环的话 v 就代表第一条数据,那 text = v.css('.text::text').extract_first() 就代表第一条数据的名言内容,以此类推,把所有数据都取了出来,最终进行保存,我们看一下完整的代码:
import scrapy
class itemSpider(scrapy.Spider):
name = 'listSpider'
start_urls = ['http://lab.scrapyd.cn']
def parse(self, response):
mingyan = response.css('div.quote') # 提取首页所有名言,保存至变量mingyan
for v in mingyan: # 循环获取每一条名言里面的:名言内容、作者、标签
text = v.css('.text::text').extract_first() # 提取名言
autor = v.css('.author::text').extract_first() # 提取作者
tags = v.css('.tags .tag::text').extract() # 提取标签
tags = ','.join(tags) # 数组转换为字符串
"""
接下来进行写文件操作,每个名人的名言储存在一个txt文档里面
"""
fileName = '%s-语录.txt' % autor # 定义文件名,如:木心-语录.txt
with open(fileName, "a+") as f: # 不同人的名言保存在不同的txt文档,“a+”以追加的形式
f.write(text)
f.write('
') # ‘
’ 表示换行
f.write('标签:' + tags)
f.write('
-------
')
f.close()
八、scrapy 爬取下一页,scrapy整站爬取
接下来,还是继续爬取:http://lab.scrapyd.cn (链接独白:为神马受伤的总是我?)!我们既然要爬取下一页,那我们首先要分析链接格式,找到下一页的链接,那爬取就简单了,我们先来看看,下一页链接长什么样?
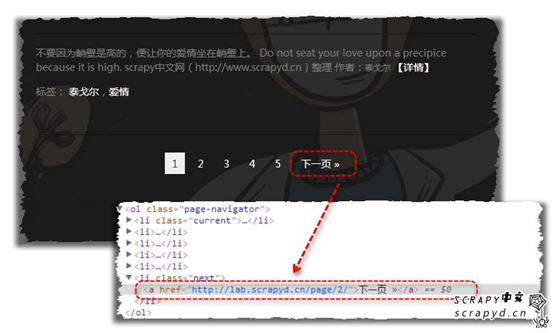
可以看到,下一页的链接如下:
<li class="next">
<a href="http://lab.scrapyd.cn/page/2/">下一页 »</a>
</li>
那到底如何让蜘蛛自动的判断、并爬取下一页、下一页的内容呢?我们可以这样来做,我们每爬一页就用css选择器来查询,是否存在下一页链接,存在:则爬取下一页链接:http://lab.scrapyd.cn/page/*/,然后把下一页链接提交给当前爬取的函数,继续爬取,继续查找下一页,知道找不到下一页,说明所有页面已经爬完,那结束爬虫。我们来看一下简单的流程图:
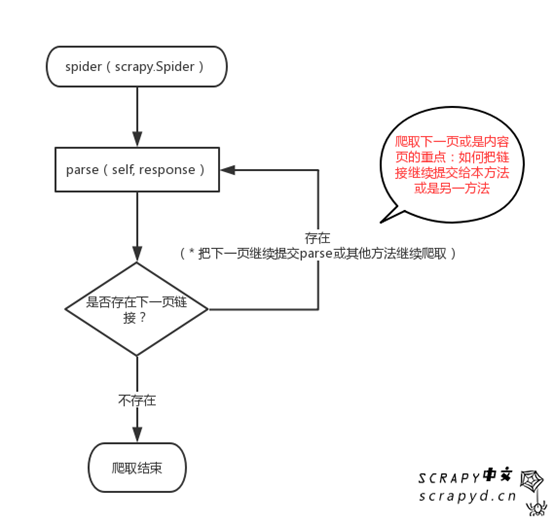
爬取内容的代码和上一文档(listSpider)一模一样,唯一区别的是这么一个地方,我们在:listSpider 蜘蛛下面添加几段代码:
next_page = response.css('li.next a::attr(href)').extract_first()
if next_page is not None:
next_page = response.urljoin(next_page)
yield scrapy.Request(next_page, callback=self.parse)
首先:我们使用:response.css('li.next a::attr(href)').extract_first()查看有木有存在下一页链接,如果存在的话,我们使用:urljoin(next_page)把相对路径,如:page/1转换为绝对路径,其实也就是加上网站域名,如:http://lab.scrapyd.cn/page/1;接下来就是爬取下一页或是内容页的秘诀所在,scrapy给我们提供了这么一个方法:scrapy.Request() 这个方法还有许多参数,后面我们慢慢说,这里我们只使用了两个参数,一个是:我们继续爬取的链接(next_page),这里是下一页链接,当然也可以是内容页;另一个是:我们要把链接提交给哪一个函数爬取,这里是parse函数,也就是本函数;当然,我们也可以在下面另写一个函数,比如:内容页,专门处理内容页的数据。经过这么一个函数,下一页链接又提交给了parse,那就可以不断的爬取了,直到不存在下一页。
九、scrapy arguments:指定蜘蛛参数爬取
我们要爬取http://lab.scrapyd.cn里面的数据,原先我们需要全站的,于是我们写呀、写呀,终于写了一个全站爬虫(其实就是上一文档的内容即可全站爬取);过了几天需求变了,我们只需要:“人生”这个标签下面的内容,那我们又需要更改爬虫;又过了几天,需求又变,我们又需要标签:“励志”下面的内容,那我们又得改爬虫……最终出现下面的情况:
for{
又过了几天……需求又变……又改……
}
如果爬虫量少还好,那如果有十个、一百个……那一天到晚我们只能不断的修改、不断的伺候这些爬虫了,于是性生活都没有了!那怎样才能让我们的爬虫更灵活呢?scrapy给我提供了可传参的爬虫,有了这么个功能,那人生就更加美丽了,上面不断变化的爬虫我们就可以这样来玩,首先按scrapy 参数格式定义好参数,如下:
def start_requests(self):
url = 'http://lab.scrapyd.cn/'
tag = getattr(self, 'tag', None) # 获取tag值,也就是爬取时传过来的参数
if tag is not None: # 判断是否存在tag,若存在,重新构造url
url = url + 'tag/' + tag # 构造url若tag=爱情,url= "http://lab.scrapyd.cn/tag/爱情"
yield scrapy.Request(url, self.parse) # 发送请求爬取参数内容
可以看到 tag = getattr(self, 'tag', None) 就是获取传过来的参数,然后根据不同的参数,构造不同的url,然后进行不同的爬取,经过这么一个处理,我们的蜘蛛就灰常的灵活了,我们来看一下完整代码:
# -*- coding: utf-8 -*-
import scrapy
class ArgsspiderSpider(scrapy.Spider):
name = "argsSpider"
def start_requests(self):
url = 'http://lab.scrapyd.cn/'
tag = getattr(self, 'tag', None) # 获取tag值,也就是爬取时传过来的参数
if tag is not None: # 判断是否存在tag,若存在,重新构造url
url = url + 'tag/' + tag # 构造url若tag=爱情,url= "http://lab.scrapyd.cn/tag/爱情"
yield scrapy.Request(url, self.parse) # 发送请求爬取参数内容
"""
以下内容为上一讲知识,若不清楚具体细节,请查看上一讲!
"""
def parse(self, response):
mingyan = response.css('div.quote')
for v in mingyan:
text = v.css('.text::text').extract_first()
tags = v.css('.tags .tag::text').extract()
tags = ','.join(tags)
fileName = '%s-语录.txt' % tags
with open(fileName, "a+") as f:
f.write(text)
f.write('
')
f.write('标签:' + tags)
f.write('
-------
')
f.close()
next_page = response.css('li.next a::attr(href)').extract_first()
if next_page is not None:
next_page = response.urljoin(next_page)
yield scrapy.Request(next_page, callback=self.parse)
代码写好之后,那我们要如何传参呢?如何运行呢?比如我们要爬取标签:爱情,我们可以这样:
scrapy crawl argsSpider -a tag=爱情
要爬取标签:励志,我们可以这样:
scrapy crawl argsSpider -a tag=励志
参数:tag=爱情、tag=励志就可以在爬取的时候传进去我们蜘蛛里面,我们就可以不修改蜘蛛,愉快的爬取了。
GitHub:
https://github.com/chenjj9527/scrapyTest.git
实战scrapy中文网存入mongodb:
http://www.scrapyd.cn/jiaocheng/171.html
实战Scrapy中文网存入MySQL: